
08 Dec 2025
Researchers from University of Wisconsin-Madison, UCLA, and Adobe Research introduce a computational framework for "relational visual similarity," which identifies image commonalities based on abstract logic rather than surface features. Their `relsim` model, trained on a novel dataset of images paired with anonymous group-derived captions, aligns significantly with human perception of relational similarity and outperforms existing attribute-based metrics in retrieval tasks.

08 Dec 2025


Researchers from Meta AI and the University of Copenhagen developed OneStory, a framework for coherent multi-shot video generation that utilizes adaptive memory modules to model long-range cross-shot context. The method consistently outperforms existing baselines, achieving higher inter-shot coherence scores (e.g., 0.5813 average inter-shot coherence in text-to-multi-shot video tasks) and enhanced shot-level quality.

09 Dec 2025
CLINICALTRIALSHUB unifies clinical trial data from structured registries and unstructured scientific literature, expanding access to structured trial information by 83.8% and providing evidence-grounded, interactive question answering. This platform, developed at The Ohio State University, leverages advanced Large Language Models to streamline information discovery and synthesis for medical professionals and researchers.
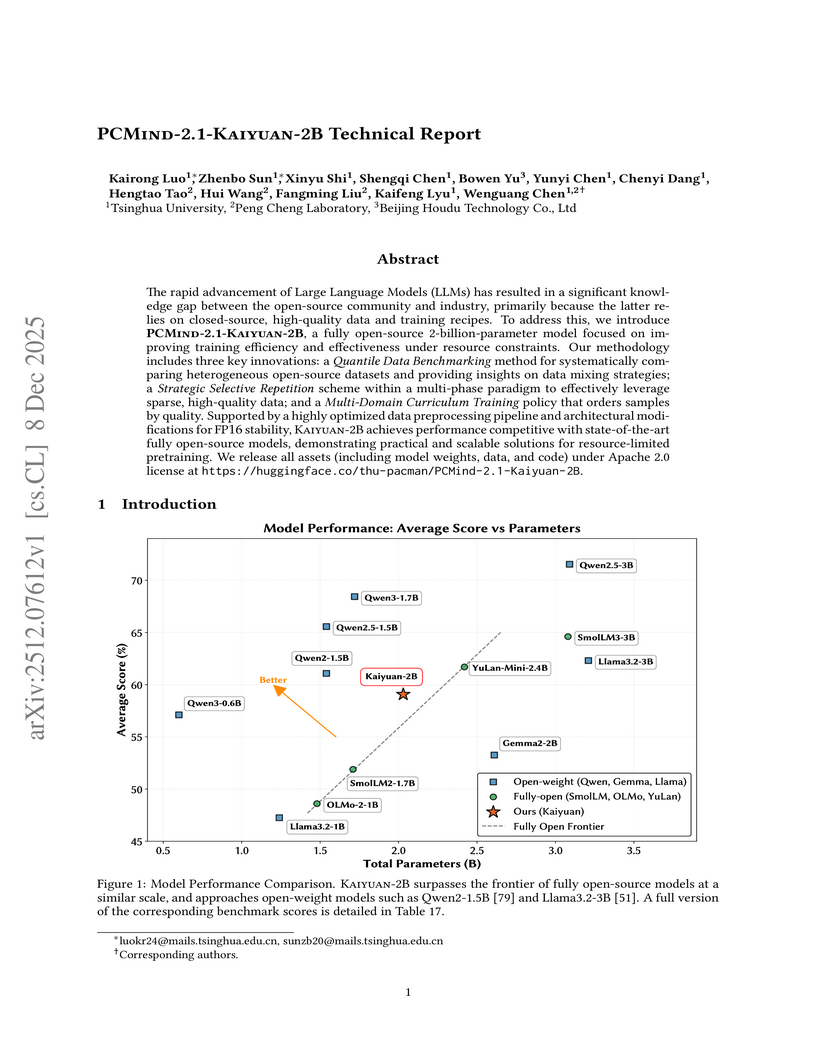
08 Dec 2025

Researchers from Tsinghua University and Peng Cheng Laboratory developed PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter language model. It achieves competitive performance in Chinese language understanding, mathematical reasoning, and code generation by employing a multi-phase curriculum training with strategic data repetition and architectural modifications for FP16 stability, attaining an overall average score of 59.07% across evaluated benchmarks and outperforming several existing open-source models in its class.

09 Dec 2025
EcomBench introduces a comprehensive benchmark for evaluating foundation agents in e-commerce, drawing on genuine user demands and expert curation to assess real-world capabilities. The evaluation demonstrates that leading models achieve strong performance on basic tasks but struggle significantly with complex, multi-step e-commerce reasoning and integrating knowledge from various sources.

08 Dec 2025

Researchers introduce the novel UAV-Anti-UAV tracking task, where a pursuer drone tracks an adversarial one, and create the first million-scale benchmark dataset for this challenging air-to-air scenario. They also propose MambaSTS, a new baseline tracker that integrates spatial, temporal, and semantic learning using Mamba and Transformer architectures, achieving a Mean Accuracy (mACC) of 0.443, which is 6.6 percentage points higher than the next best method on the new benchmark.

09 Dec 2025
Foundation models (FMs) are increasingly assuming the role of the "brain" of AI agents. While recent efforts have begun to equip FMs with native single-agent abilities -- such as GUI interaction or integrated tool use -- we argue that the next frontier is endowing FMs with native multi-agent intelligence. We identify four core capabilities of FMs in multi-agent contexts: understanding, planning, efficient communication, and adaptation. Contrary to assumptions about the spontaneous emergence of such abilities, we provide extensive empirical evidence across 41 large language models showing that strong single-agent performance alone does not automatically yield robust multi-agent intelligence. To address this gap, we outline key research directions -- spanning dataset construction, evaluation, training paradigms, and safety considerations -- for building FMs with native multi-agent intelligence.

10 Dec 2025
Time awareness is a fundamental ability of omni large language models, especially for understanding long videos and answering complex questions. Previous approaches mainly target vision-language scenarios and focus on the explicit temporal grounding questions, such as identifying when a visual event occurs or determining what event happens at aspecific time. However, they often make insufficient use of the audio modality, and overlook implicit temporal grounding across modalities--for example, identifying what is visually present when a character speaks, or determining what is said when a visual event occurs--despite such cross-modal temporal relations being prevalent in real-world scenarios. In this paper, we propose ChronusOmni, an omni large language model designed to enhance temporal awareness for both explicit and implicit audiovisual temporal grounding. First, we interleave text-based timestamp tokens with visual and audio representations at each time unit, enabling unified temporal modeling across modalities. Second, to enforce correct temporal ordering and strengthen fine-grained temporal reasoning, we incorporate reinforcement learning with specially designed reward functions. Moreover, we construct ChronusAV, a temporally-accurate, modality-complete, and cross-modal-aligned dataset to support the training and evaluation on audiovisual temporal grounding task. Experimental results demonstrate that ChronusOmni achieves state-of-the-art performance on ChronusAV with more than 30% improvement and top results on most metrics upon other temporal grounding benchmarks. This highlights the strong temporal awareness of our model across modalities, while preserving general video and audio understanding capabilities.

09 Dec 2025
Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at this https URL.

09 Dec 2025
Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at this https URL.

07 Dec 2025
The challenge of \textbf{imbalanced regression} arises when standard Empirical Risk Minimization (ERM) biases models toward high-frequency regions of the data distribution, causing severe degradation on rare but high-impact ``tail'' events. Existing strategies uch as loss re-weighting or synthetic over-sampling often introduce noise, distort the underlying distribution, or add substantial algorithmic complexity.
We introduce \textbf{PARIS} (Pruning Algorithm via the Representer theorem for Imbalanced Scenarios), a principled framework that mitigates imbalance by \emph{optimizing the training set itself}. PARIS leverages the representer theorem for neural networks to compute a \textbf{closed-form representer deletion residual}, which quantifies the exact change in validation loss caused by removing a single training point \emph{without retraining}. Combined with an efficient Cholesky rank-one downdating scheme, PARIS performs fast, iterative pruning that eliminates uninformative or performance-degrading samples.
We use a real-world space weather example, where PARIS reduces the training set by up to 75\% while preserving or improving overall RMSE, outperforming re-weighting, synthetic oversampling, and boosting baselines. Our results demonstrate that representer-guided dataset pruning is a powerful, interpretable, and computationally efficient approach to rare-event regression.

08 Dec 2025


Researchers from Zhejiang University and ByteDance introduced OpenVE-3M, a large-scale, high-quality dataset of 3 million instruction-guided video editing pairs, and OpenVE-Bench, a unified evaluation benchmark. They also developed OpenVE-Edit, a 5B parameter model trained on OpenVE-3M, which achieved state-of-the-art performance with an overall score of 2.49 on OpenVE-Bench, outperforming larger existing models.

10 Dec 2025

Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.
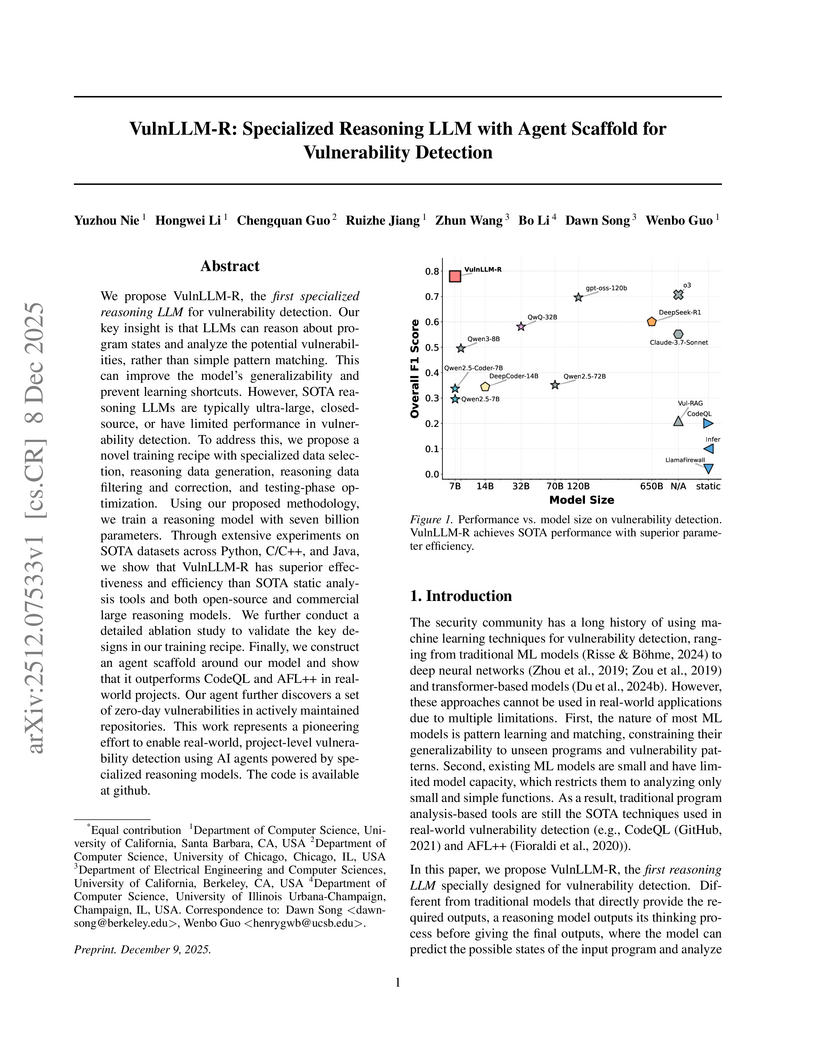
08 Dec 2025
Researchers from the University of California, Santa Barbara, University of Chicago, University of California, Berkeley, and University of Illinois Urbana-Champaign developed VulnLLM-R, a 7-billion parameter specialized reasoning large language model for vulnerability detection. This open-source model surpasses the performance of larger general-purpose LLMs and traditional tools, achieving project-level analysis and discovering 15 zero-day vulnerabilities in real-world software.

08 Dec 2025
Recent advances in large reasoning models (LRMs) have enabled agentic search systems to perform complex multi-step reasoning across multiple sources. However, most studies focus on general information retrieval and rarely explores vertical domains with unique challenges. In this work, we focus on local life services and introduce LocalSearchBench, which encompass diverse and complex business scenarios. Real-world queries in this domain are often ambiguous and require multi-hop reasoning across merchants and products, remaining challenging and not fully addressed. As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types. We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps. We also developed LocalPlayground, a unified environment integrating multiple tools for agent interaction. Experiments show that even state-of-the-art LRMs struggle on LocalSearchBench: the best model (DeepSeek-V3.1) achieves only 34.34% correctness, and most models have issues with completeness (average 77.33%) and faithfulness (average 61.99%). This highlights the need for specialized benchmarks and domain-specific agent training in local life services. Code, Benchmark, and Leaderboard are available at this http URL.

07 Dec 2025


The DoGe framework from Shanghai Artificial Intelligence Laboratory and collaborators introduces a context-first self-evolving learning approach that decouples cognitive processes for data-scarce vision-language reasoning. It achieves stable performance improvements of 5.7% for 3B-series models and 2.3% for 7B-series models across seven benchmarks, while enhancing policy exploration and mitigating reward hacking.

10 Dec 2025
Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.

06 Dec 2025
The Nanbeige4-3B model family from the Nanbeige LLM Lab at Boss Zhipin introduces a 3-billion-parameter language model that consistently outperforms much larger open-source models, setting new state-of-the-art averages in mathematical and scientific reasoning. This performance is achieved through a multi-stage training pipeline incorporating advanced data filtering, a fine-grained learning rate scheduler, dual-level preference distillation, and multi-stage reinforcement learning.
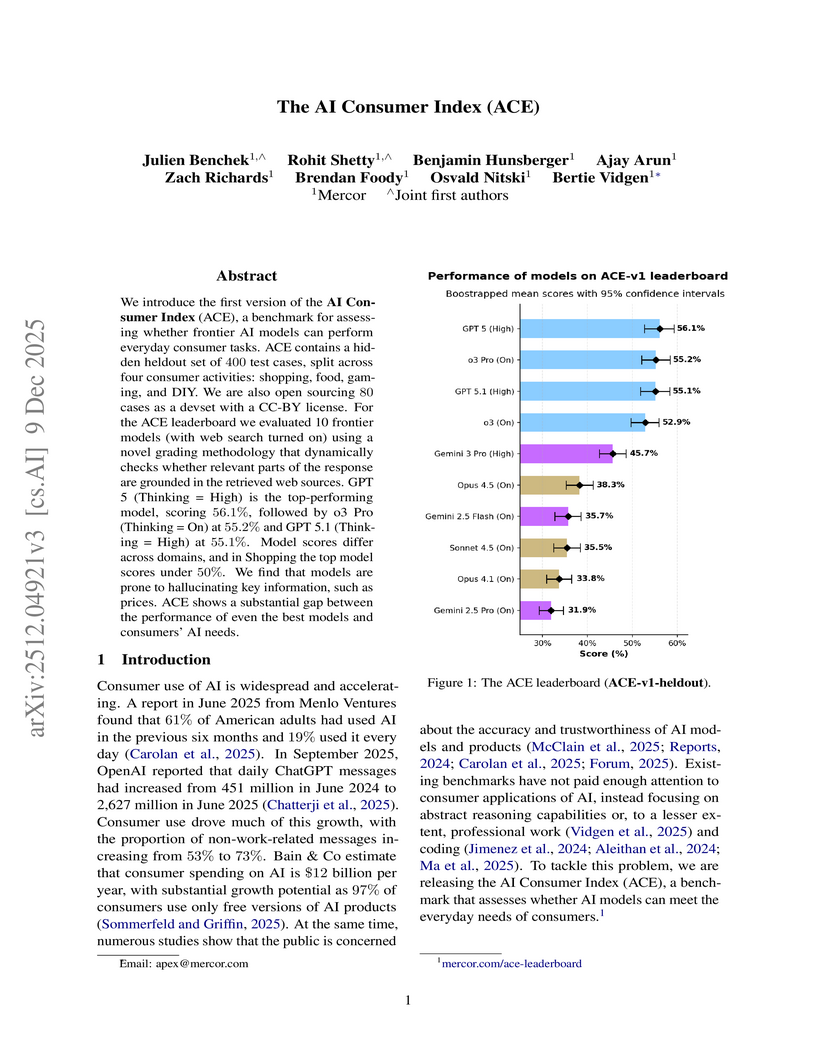
09 Dec 2025
We introduce the first version of the AI Consumer Index (ACE), a benchmark for assessing whether frontier AI models can perform everyday consumer tasks. ACE contains a hidden heldout set of 400 test cases, split across four consumer activities: shopping, food, gaming, and DIY. We are also open sourcing 80 cases as a devset with a CC-BY license. For the ACE leaderboard we evaluated 10 frontier models (with websearch turned on) using a novel grading methodology that dynamically checks whether relevant parts of the response are grounded in the retrieved web sources. GPT 5 (Thinking = High) is the top-performing model, scoring 56.1%, followed by o3 Pro (Thinking = On) at 55.2% and GPT 5.1 (Thinking = High) at 55.1%. Model scores differ across domains, and in Shopping the top model scores under 50\%. We find that models are prone to hallucinating key information, such as prices. ACE shows a substantial gap between the performance of even the best models and consumers' AI needs.

07 Dec 2025


OXTAL introduces an all-atom diffusion transformer model that generates organic crystal structures directly from a 2D molecular graph, learning both molecular conformations and periodic packing from over 600,000 experimental structures. The method demonstrates competitive accuracy against traditional DFT-based approaches in CCDC blind tests while offering significantly reduced computational inference costs.
There are no more papers matching your filters at the moment.
