
28 Feb 2024
IBM researchers successfully deployed a large-scale generative AI system to automate real-time text content production for major sports and music events, leveraging various large language models and adaptation techniques. The system achieved a 15x speed improvement in content generation, supporting 90 million fans globally across events like The Masters, Wimbledon, US Open, ESPN Fantasy Football, and the GRAMMY Awards.

01 Oct 2025

The paper introduces TOUCAN, a dataset of 1.5 million tool-agentic trajectories synthesized from real-world Model Context Protocol environments to address the scarcity of high-quality, open-source training data. Models fine-tuned on TOUCAN demonstrated enhanced agentic capabilities, outperforming larger closed-source models on complex benchmarks like BFCL V3 (achieving 70.45% overall) and MCP-Universe.

15 Jan 2025

Researchers from MIT and MIT-IBM Watson AI Lab developed a hardware-efficient, parallelized training algorithm for DeltaNet, a linear transformer model that uses the delta rule for improved associative recall. This advancement enables DeltaNet to achieve competitive language modeling performance, surpass other linear models on specific recall tasks, and demonstrate further improvements in hybrid architectures combining it with traditional attention.

27 Aug 2024
A Gated Linear Attention (GLA) Transformer is introduced, leveraging FLASHLINEARATTENTION for hardware-efficient training and inference. This approach achieves competitive language modeling performance with LLaMA-like Transformers and other efficient models, while demonstrating higher training throughput and stronger length generalization to sequences over 20,000 tokens.

14 Mar 2024




3D-VLA introduces a generative world model that integrates 3D scene understanding with language and action generation, enabling embodied AI systems to predict future states and plan actions in 3D environments. It leverages a new 3D embodied instruction dataset and demonstrates improved performance in 3D reasoning, goal generation, and action planning compared to 2D vision-language models.

07 Oct 2025

DeepEvolve, developed by the University of Notre Dame and MIT-IBM Watson AI Lab, integrates external knowledge retrieval with algorithm evolution to automate scientific algorithm discovery, consistently improving initial algorithms across nine diverse scientific benchmarks with performance gains up to 666.02%. This agent also introduces robust capabilities for cross-file code editing and systematic debugging, enhancing the practical implementation of complex algorithmic ideas.

02 Jun 2025



AdaWorld introduces a novel approach to world model learning that extracts context-invariant latent actions from unlabeled videos, enabling efficient adaptation to new environments. This method achieves superior action transfer (e.g., 70.5% human success rate on LIBERO vs. 20% for baseline) and faster world model adaptation with limited data, improving visual planning success rates in game and robotic tasks.
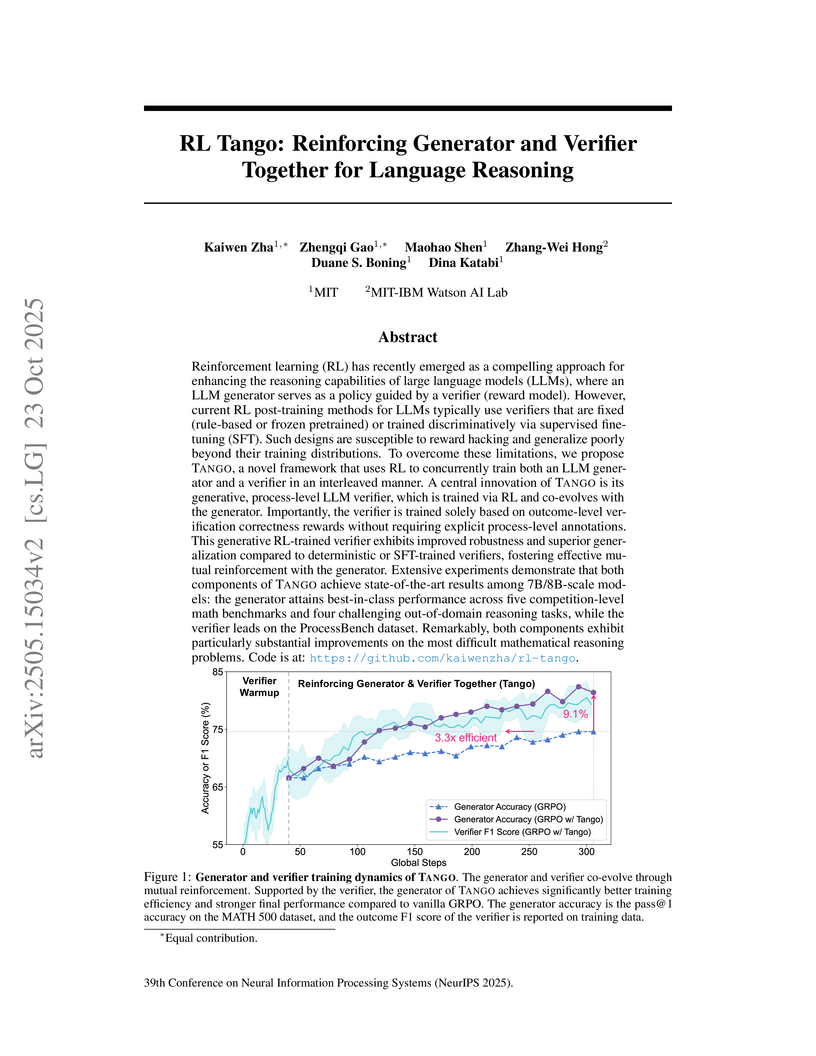
23 Oct 2025
TANGO introduces a framework that concurrently trains an LLM generator and a generative, process-level verifier using reinforcement learning. This approach enhances the reasoning capabilities of 7B/8B-scale models, achieving an average relative improvement of 25.5% on math benchmarks and a 3.3x increase in training efficiency without requiring process-level annotations.

01 May 2025

QServe introduces a W4A8KV4 quantization scheme and an optimized inference system to enhance large language model serving efficiency. It achieves 1.2-3.5x higher throughput than TensorRT-LLM and enables a 3x reduction in GPU dollar cost for LLM serving on L40S GPUs.

24 Jul 2023

The 3D-LLM framework from a collaboration including MIT and UMass Amherst enables large language models to understand and reason about the 3D physical world. It achieves this by generating large-scale 3D-language data and deriving 3D features from multi-view 2D images, demonstrating improved performance across tasks like 3D question answering and object grounding compared to prior methods.

22 May 2025


This paper introduces PaTH (Position encoding via Accumulating Householder Transformations), a data-dependent position encoding scheme for Transformers that dynamically adapts to input sequences. PaTH significantly outperforms existing methods like Rotary Position Embedding (RoPE) on sequential reasoning tasks requiring sophisticated state tracking and demonstrates superior length extrapolation capabilities on language modeling and long-context benchmarks.

04 Dec 2025
Existing methods for extracting reward signals in Reinforcement Learning typically rely on labeled data and dedicated training splits, a setup that contrasts with how humans learn directly from their environment. In this work, we propose TTRV to enhance vision language understanding by adapting the model on the fly at inference time, without the need for any labeled data. Concretely, we enhance the Group Relative Policy Optimization (GRPO) framework by designing rewards based on the frequency of the base model's output, while inferring on each test sample multiple times. Further, we also propose to control the diversity of the model's output by simultaneously rewarding the model for obtaining low entropy of the output empirical distribution. Our approach delivers consistent gains across both object recognition and visual question answering (VQA), with improvements of up to 52.4% and 29.8%, respectively, and average boosts of 24.6% and 10.0% across 16 datasets. Remarkably, on image recognition, TTRV applied to InternVL 8B surpasses GPT-4o by an average of 2.3% over 8 benchmarks, while remaining highly competitive on VQA, demonstrating that test-time reinforcement learning can match or exceed the strongest proprietary models. Finally, we find many interesting properties of test-time RL for VLMs: for example, even in extremely data-constrained scenarios, where adaptation is performed on a single randomly chosen unlabeled test example, TTRV still yields non-trivial improvements of up to 5.5% in recognition tasks.

05 Jun 2023
Label-free CBM introduces a framework that converts any deep neural network into a Concept Bottleneck Model without requiring labeled concept data, thereby enhancing interpretability. The method leverages large language models for automated concept generation and achieves high accuracy comparable to standard models on complex datasets like ImageNet, while providing transparent decision rules.

17 Dec 2024


This paper conducts an empirical study on supervised fine-tuning of small language models (3B-7B parameters), demonstrating that simpler training strategies, such as stacked training and larger batch sizes (e.g., 8K) with constant learning rates, can achieve higher performance on benchmarks like MMLU and MTBench compared to conventional phased training approaches. It also shows that early-stage training dynamics, specifically lower gradient norms, can predict better final model performance, enabling computational savings.

02 Feb 2025

LSceneLLM, developed by researchers from South China University of Technology, Tencent Robotics X, and others, presents an adaptive framework for large 3D scene understanding that mimics human visual processing by focusing on task-relevant regions. The approach achieves state-of-the-art performance across large indoor (XR-Scene), single-room indoor (ScanQA), and large outdoor (NuscenesQA) benchmarks, significantly improving fine-grained detail recognition and setting a new standard for embodied AI applications.

26 Nov 2025
A video reasoning agent, Video-R4, is presented, enabling large multimodal models to perform "visual rumination" by iteratively selecting and refining visual evidence in text-rich videos. This approach achieves state-of-the-art results on video question answering benchmarks and exhibits robust zero-shot generalization across diverse multimodal tasks.
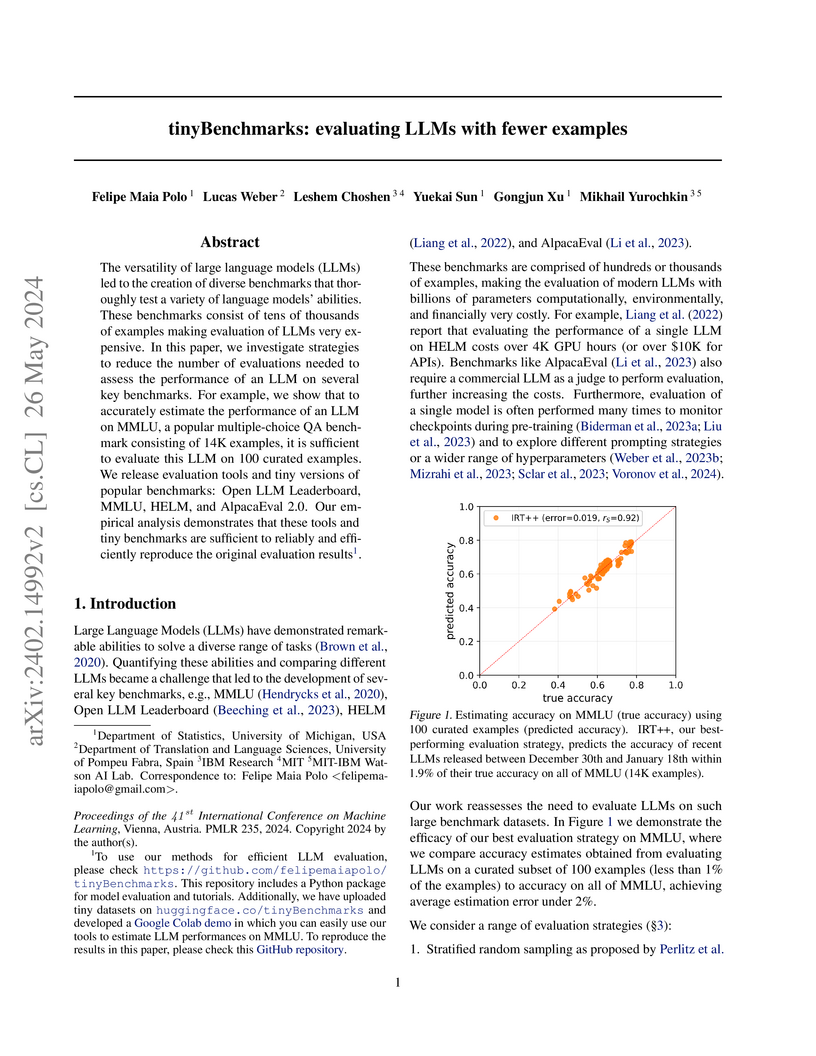
26 May 2024


Researchers from the University of Michigan, University of Pompeu Fabra, IBM Research, and MIT developed "tinyBenchmarks," a framework that reduces the number of examples needed for Large Language Model (LLM) evaluation by leveraging Item Response Theory. Their approach achieves an average performance estimation error of within 2% using as few as 100 examples per scenario, representing a reduction factor of up to 160 on common benchmarks like the Open LLM Leaderboard.

26 Nov 2025
MIRA, a multimodal iterative reasoning agent, significantly enhances the ability of open-source diffusion models to perform complex instruction-guided image editing. It achieves this by employing a closed-loop perception–reasoning–action cycle, leading to improved semantic consistency and perceptual quality often comparable to or surpassing proprietary systems.

25 Sep 2023

Researchers from UC Berkeley, CMU, UW-Madison, and other institutions successfully adapt Reinforcement Learning from Human Feedback (RLHF) to large multimodal models (LMMs), introducing Factually Augmented RLHF (Fact-RLHF) to mitigate hallucinations and improve alignment with human preferences. The resulting LLaVA-RLHF model shows a 60% improvement in hallucination reduction on a new benchmark, MMHAL-BENCH, and achieves 95.6% of GPT-4's performance on LLaVA-Bench for general alignment.

24 May 2025


TextArena, from A*STAR and collaborators, introduces an open-source framework featuring 74 competitive text-based games to evaluate and train agentic behavior in Large Language Models. It provides a dynamic, relative skill ranking system for LLMs against each other and humans, and supports reinforcement learning, addressing current benchmark limitations.
There are no more papers matching your filters at the moment.
