
05 Nov 2025
 CNRS
CNRS University of CambridgeHeidelberg University
University of CambridgeHeidelberg University Imperial College LondonUniversity of Zurich
Imperial College LondonUniversity of Zurich University College London
University College London The Chinese University of Hong Kong
The Chinese University of Hong Kong University of PennsylvaniaTUD Dresden University of Technology
University of PennsylvaniaTUD Dresden University of Technology Sorbonne Université
Sorbonne Université InriaHelmholtz-Zentrum Dresden-Rossendorf (HZDR)INSERMHelmholtz-Zentrum Dresden-RossendorfUniversity Hospital CologneWestern UniversityGerman Cancer Research CenterHeidelberg University HospitalUniversity of StrasbourgNational Center for Tumor Diseases (NCT)Lawson Health Research InstituteHelmholtz ImagingAP-HPInstitut du Cerveau – Paris Brain Institute - ICMBalgrist University HospitalChildren’s National HospitalReutlingen UniversityGerman Cancer Research Center (DKFZ) HeidelbergUCL Hawkes InstituteUniversity College London HospitalNational Center for Tumor DiseasesEnAcuity Ltd.University Hospital LeipzigHIDSS4Health - Helmholtz Information and Data Science School for HealthHôpital de la Pitié SalpêtrièreHI Helmholtz ImagingElse Kröner Fresenius Center for Digital HealthFaculty of Medicine and University Hospital Carl Gustav CarusAI Health Innovation ClusterUniversity Medical Center HeidelbergAP-HP, Hôpital de la Pitié-SalpêtrièreScialyticsDZHK Partnersite Heidelberg-MannheimVerb Surgical Inc.Children
DANQueens
’ University
InriaHelmholtz-Zentrum Dresden-Rossendorf (HZDR)INSERMHelmholtz-Zentrum Dresden-RossendorfUniversity Hospital CologneWestern UniversityGerman Cancer Research CenterHeidelberg University HospitalUniversity of StrasbourgNational Center for Tumor Diseases (NCT)Lawson Health Research InstituteHelmholtz ImagingAP-HPInstitut du Cerveau – Paris Brain Institute - ICMBalgrist University HospitalChildren’s National HospitalReutlingen UniversityGerman Cancer Research Center (DKFZ) HeidelbergUCL Hawkes InstituteUniversity College London HospitalNational Center for Tumor DiseasesEnAcuity Ltd.University Hospital LeipzigHIDSS4Health - Helmholtz Information and Data Science School for HealthHôpital de la Pitié SalpêtrièreHI Helmholtz ImagingElse Kröner Fresenius Center for Digital HealthFaculty of Medicine and University Hospital Carl Gustav CarusAI Health Innovation ClusterUniversity Medical Center HeidelbergAP-HP, Hôpital de la Pitié-SalpêtrièreScialyticsDZHK Partnersite Heidelberg-MannheimVerb Surgical Inc.Children
DANQueens
’ UniversitySurgical data science (SDS) is rapidly advancing, yet clinical adoption of artificial intelligence (AI) in surgery remains severely limited, with inadequate validation emerging as a key obstacle. In fact, existing validation practices often neglect the temporal and hierarchical structure of intraoperative videos, producing misleading, unstable, or clinically irrelevant results. In a pioneering, consensus-driven effort, we introduce the first comprehensive catalog of validation pitfalls in AI-based surgical video analysis that was derived from a multi-stage Delphi process with 91 international experts. The collected pitfalls span three categories: (1) data (e.g., incomplete annotation, spurious correlations), (2) metric selection and configuration (e.g., neglect of temporal stability, mismatch with clinical needs), and (3) aggregation and reporting (e.g., clinically uninformative aggregation, failure to account for frame dependencies in hierarchical data structures). A systematic review of surgical AI papers reveals that these pitfalls are widespread in current practice, with the majority of studies failing to account for temporal dynamics or hierarchical data structure, or relying on clinically uninformative metrics. Experiments on real surgical video datasets provide the first empirical evidence that ignoring temporal and hierarchical data structures can lead to drastic understatement of uncertainty, obscure critical failure modes, and even alter algorithm rankings. This work establishes a framework for the rigorous validation of surgical video analysis algorithms, providing a foundation for safe clinical translation, benchmarking, regulatory review, and future reporting standards in the field.

23 Oct 2023
Despite the growing body of work on explainable machine learning in time
series classification (TSC), it remains unclear how to evaluate different
explainability methods. Resorting to qualitative assessment and user studies to
evaluate explainers for TSC is difficult since humans have difficulties
understanding the underlying information contained in time series data.
Therefore, a systematic review and quantitative comparison of explanation
methods to confirm their correctness becomes crucial. While steps to
standardized evaluations were taken for tabular, image, and textual data,
benchmarking explainability methods on time series is challenging due to a)
traditional metrics not being directly applicable, b) implementation and
adaption of traditional metrics for time series in the literature vary, and c)
varying baseline implementations. This paper proposes XTSC-Bench, a
benchmarking tool providing standardized datasets, models, and metrics for
evaluating explanation methods on TSC. We analyze 3 perturbation-, 6 gradient-
and 2 example-based explanation methods to TSC showing that improvements in the
explainers' robustness and reliability are necessary, especially for
multivariate data.

21 Feb 2024
RESTful APIs based on HTTP are one of the most important ways to make data and functionality available to applications and software services. However, the quality of the API design strongly impacts API understandability and usability, and many rules have been specified for this. While we have evidence for the effectiveness of many design rules, it is still difficult for practitioners to identify rule violations in their design. We therefore present RESTRuler, a Java-based open-source tool that uses static analysis to detect design rule violations in OpenAPI descriptions. The current prototype supports 14 rules that go beyond simple syntactic checks and partly rely on natural language processing. The modular architecture also makes it easy to implement new rules. To evaluate RESTRuler, we conducted a benchmark with over 2,300 public OpenAPI descriptions and asked 7 API experts to construct 111 complicated rule violations. For robustness, RESTRuler successfully analyzed 99% of the used real-world OpenAPI definitions, with some failing due to excessive size. For performance efficiency, the tool performed well for the majority of files and could analyze 84% in less than 23 seconds with low CPU and RAM usage. Lastly, for effectiveness, RESTRuler achieved a precision of 91% (ranging from 60% to 100% per rule) and recall of 68% (ranging from 46% to 100%). Based on these variations between rule implementations, we identified several opportunities for improvements. While RESTRuler is still a research prototype, the evaluation suggests that the tool is quite robust to errors, resource-efficient for most APIs, and shows good precision and decent recall. Practitioners can use it to improve the quality of their API design.

20 Jan 2021
Among the multitude of software development processes available, hardly any is used by the book. Regardless of company size or industry sector, a majority of project teams and companies use customized processes that combine different development methods -- so-called hybrid development methods. Even though such hybrid development methods are highly individualized, a common understanding of how to systematically construct synergetic practices is missing. In this paper, we make a first step towards devising such guidelines. Grounded in 1,467 data points from a large-scale online survey among practitioners, we study the current state of practice in process use to answer the question: What are hybrid development methods made of? Our findings reveal that only eight methods and few practices build the core of modern software development. This small set allows for statistically constructing hybrid development methods. Using an 85% agreement level in the participants' selections, we provide two examples illustrating how hybrid development methods are characterized by the practices they are made of. Our evidence-based analysis approach lays the foundation for devising hybrid development methods.

19 Dec 2022

Automatic segmentation is essential for the brain tumor diagnosis, disease prognosis, and follow-up therapy of patients with gliomas. Still, accurate detection of gliomas and their sub-regions in multimodal MRI is very challenging due to the variety of scanners and imaging protocols. Over the last years, the BraTS Challenge has provided a large number of multi-institutional MRI scans as a benchmark for glioma segmentation algorithms. This paper describes our contribution to the BraTS 2022 Continuous Evaluation challenge. We propose a new ensemble of multiple deep learning frameworks namely, DeepSeg, nnU-Net, and DeepSCAN for automatic glioma boundaries detection in pre-operative MRI. It is worth noting that our ensemble models took first place in the final evaluation on the BraTS testing dataset with Dice scores of 0.9294, 0.8788, and 0.8803, and Hausdorf distance of 5.23, 13.54, and 12.05, for the whole tumor, tumor core, and enhancing tumor, respectively. Furthermore, the proposed ensemble method ranked first in the final ranking on another unseen test dataset, namely Sub-Saharan Africa dataset, achieving mean Dice scores of 0.9737, 0.9593, and 0.9022, and HD95 of 2.66, 1.72, 3.32 for the whole tumor, tumor core, and enhancing tumor, respectively. The docker image for the winning submission is publicly available at (this https URL).

06 Mar 2018
SLAM systems are mainly applied for robot navigation while research on
feasibility for motion planning with SLAM for tasks like bin-picking, is
scarce. Accurate 3D reconstruction of objects and environments is important for
planning motion and computing optimal gripper pose to grasp objects. In this
work, we propose the methods to analyze the accuracy of a 3D environment
reconstructed using a LSD-SLAM system with a monocular camera mounted onto the
gripper of a collaborative robot. We discuss and propose a solution to the pose
space conversion problem. Finally, we present several criteria to analyze the
3D reconstruction accuracy. These could be used as guidelines to improve the
accuracy of 3D reconstructions with monocular LSD-SLAM and other SLAM based
solutions.

12 May 2019
Near-Data Processing refers to an architectural hardware and software
paradigm, based on the co-location of storage and compute units. Ideally, it
will allow to execute application-defined data- or compute-intensive operations
in-situ, i.e. within (or close to) the physical data storage. Thus, Near-Data
Processing seeks to minimize expensive data movement, improving performance,
scalability, and resource-efficiency. Processing-in-Memory is a sub-class of
Near-Data processing that targets data processing directly within memory (DRAM)
chips. The effective use of Near-Data Processing mandates new architectures,
algorithms, interfaces, and development toolchains.

17 Oct 2019
Modern mixed (HTAP) workloads execute fast update-transactions and
long-running analytical queries on the same dataset and system. In
multi-version (MVCC) systems, such workloads result in many short-lived
versions and long version-chains as well as in increased and frequent
maintenance overhead. Consequently, the index pressure increases significantly.
Firstly, the frequent modifications cause frequent creation of new versions,
yielding a surge in index maintenance overhead. Secondly and more importantly,
index-scans incur extra I/O overhead to determine, which of the resulting
tuple-versions are visible to the executing transaction (visibility-check) as
current designs only store version/timestamp information in the base table --
not in the index. Such index-only visibility-check is critical for HTAP
workloads on large datasets. In this paper we propose the Multi-Version
Partitioned B-Tree (MV-PBT) as a version-aware index structure, supporting
index-only visibility checks and flash-friendly I/O patterns. The experimental
evaluation indicates a 2x improvement for analytical queries and 15% higher
transactional throughput under HTAP workloads (CH-Benchmark). MV-PBT offers 40%
higher transactional throughput compared to WiredTiger's LSM-Tree
implementation under YCSB.

22 May 2016
We present a fully automatic approach to real-time 3D face reconstruction from monocular in-the-wild videos. With the use of a cascaded-regressor based face tracking and a 3D Morphable Face Model shape fitting, we obtain a semi-dense 3D face shape. We further use the texture information from multiple frames to build a holistic 3D face representation from the video frames. Our system is able to capture facial expressions and does not require any person-specific training. We demonstrate the robustness of our approach on the challenging 300 Videos in the Wild (300-VW) dataset. Our real-time fitting framework is available as an open source library at this http URL.

09 Nov 2021
Facial beauty prediction (FBP) aims to develop a machine that automatically makes facial attractiveness assessment. In the past those results were highly correlated with human ratings, therefore also with their bias in annotating. As artificial intelligence can have racist and discriminatory tendencies, the cause of skews in the data must be identified. Development of training data and AI algorithms that are robust against biased information is a new challenge for scientists. As aesthetic judgement usually is biased, we want to take it one step further and propose an Unbiased Convolutional Neural Network for FBP. While it is possible to create network models that can rate attractiveness of faces on a high level, from an ethical point of view, it is equally important to make sure the model is unbiased. In this work, we introduce AestheticNet, a state-of-the-art attractiveness prediction network, which significantly outperforms competitors with a Pearson Correlation of 0.9601. Additionally, we propose a new approach for generating a bias-free CNN to improve fairness in machine learning.

18 Apr 2023
Software development teams have to face stress caused by deadlines, staff
turnover, or individual differences in commitment, expertise, and time zones.
While students are typically taught the theory of software project management,
their exposure to such stress factors is usually limited. However, preparing
students for the stress they will have to endure once they work in project
teams is important for their own sake, as well as for the sake of team
performance in the face of stress. Team performance has been linked to the
diversity of software development teams, but little is known about how
diversity influences the stress experienced in teams. In order to shed light on
this aspect, we provided students with the opportunity to self-experience the
basics of project management in self-organizing teams, and studied the impact
of six diversity dimensions on team performance, coping with stressors, and
positive perceived learning effects. Three controlled experiments at two
universities with a total of 65 participants suggest that the social background
impacts the perceived stressors the most, while age and work experience have
the highest impact on perceived learnings. Most diversity dimensions have a
medium correlation with the quality of work, yet no significant relation to the
team performance. This lays the foundation to improve students' training for
software engineering teamwork based on their diversity-related needs and to
create diversity-sensitive awareness among educators, employers and
researchers.

20 Jul 2023
Context: Web APIs are one of the most used ways to expose application
functionality on the Web, and their understandability is important for
efficiently using the provided resources. While many API design rules exist,
empirical evidence for the effectiveness of most rules is lacking.
Objective: We therefore wanted to study 1) the impact of RESTful API design
rules on understandability, 2) if rule violations are also perceived as more
difficult to understand, and 3) if demographic attributes like REST-related
experience have an influence on this.
Method: We conducted a controlled Web-based experiment with 105 participants,
from both industry and academia and with different levels of experience. Based
on a hybrid between a crossover and a between-subjects design, we studied 12
design rules using API snippets in two complementary versions: one that adhered
to a "rule" and one that was a "violation" of this rule. Participants answered
comprehension questions and rated the perceived difficulty.
Results: For 11 of the 12 rules, we found that "violation" performed
significantly worse than "rule" for the comprehension tasks. Regarding the
subjective ratings, we found significant differences for 9 of the 12 rules,
meaning that most violations were subjectively rated as more difficult to
understand. Demographics played no role in the comprehension performance for
"violation".
Conclusions: Our results provide first empirical evidence for the importance
of following design rules to improve the understandability of Web APIs, which
is important for researchers, practitioners, and educators.

17 Aug 2023
Transaction processing is of growing importance for mobile and web applications. Booking tickets, flight reservation, e-Banking, e-Payment, and booking holiday arrangements are just a few examples. Due to temporarily disconnected situations the synchronization and consistent transaction processing are key issues. To avoid difficulties with blocked transactions or communication loss several authors and technology providers have recommended to use Optimistic Concurrency Control (OCC) to solve the problem. However most vendors of Relational Database Management Systems (DBMS) implemented only locking schemes for concurrency control which prohibit the immediate use of OCC. We propose Row Version Verifying (RVV) discipline to avoid lost updates and achieve a kind of OCC for those DBMS not providing an adequate non-blocking concurrency control. Moreover, the different mechanisms are categorized as access pattern in order to provide programmers with a general guideline for SQL databases. The proposed SQL access patterns are relevant for all transactional applications with unreliable communication and low conflicting situations. We demonstrate the proposed solution using mainstream database systems like Oracle, DB2, and SQLServer.

25 Apr 2022
PedRecNet integrates 2D pose, camera-independent 3D pose, and body and head orientation estimation into a single multi-task neural network. The model achieves competitive performance on 3D pose estimation and demonstrates strong body orientation estimation, significantly benefiting from the inclusion of custom-created simulation data to address the scarcity of real-world orientation labels.

06 May 2024
Wave-like partial differential equations occur in many engineering applications. Here the engineering setup is embedded into the Hilbert space framework of functional analysis of modern mathematical physics. The notion wave-like is a generalization of the primary wave (partial) differential equation.
A short overview over three wave-like problems in physics and engineering is presented. The mathematical procedure for achieving positive, selfadjoint differential operators in an -Hilbert space is described, operators which then may be taken for wave-like differential equations. Also some general results from the functional analytic literature are summarized.
The main part concerns the investigation of the free Euler--Bernoulli bending vibrations of a slender, straight, elastic beam in one spatial dimension in the -Hilbert space setup. Taking suitable Sobolev spaces we perform the mathematically exact introduction and analysis of the corresponding (spatial) positive, selfadjoint differential operators of -th order, which belong to the different boundary conditions arising as supports in statics. A comparison with free wave swinging of a string is added, using a Laplacian as differential operator.

06 Jul 2024
This paper reviews the changes for database technology represented by the
current development of the draft international standard ISO 39075 (Database
Languages - GQL), which seeks a unified specification for property graphs and
knowledge graphs. This paper examines these current developments as part of our
review of the evolution of database technology, and their relation to the
longer-term goal of supporting the Semantic Web using relational technology.

06 Jul 2024
Recent standardization work for database languages has reflected the growing
use of typed graph models (TGM) in application development. Such data models
are frequently only used early in the design process, and not reflected
directly in underlying physical database. In previous work, we have added
support to a relational database management system (RDBMS) with role-based
structures to ensure that relevant data models are not separately declared in
each application but are an important part of the database implementation. In
this work, we implement this approach for the TGM: the resulting database
implementation is novel in retaining the best features of the graph-based and
relational database technologies.

17 Feb 2025
In large-scale projects operated in regulated environments, standard
development processes are employed to meet strict compliance demands. Since
such processes are usually complex, providing process users with access to
their required process, which should be tailored to a project's needs is a
challenging task that requires proper tool support. In this paper, we present a
process ecosystem in which software processes are provided as web-based
services. We outline the general idea, describe the modeling approach, and we
illustrate the concept's realization using a proof-of-concept case based on a
large software process line that is mandatory to use for IT projects in the
German public sector. The suitability is evaluated with three experts that
valued the improved accessibly and usability of the process and the end-user
support tool.
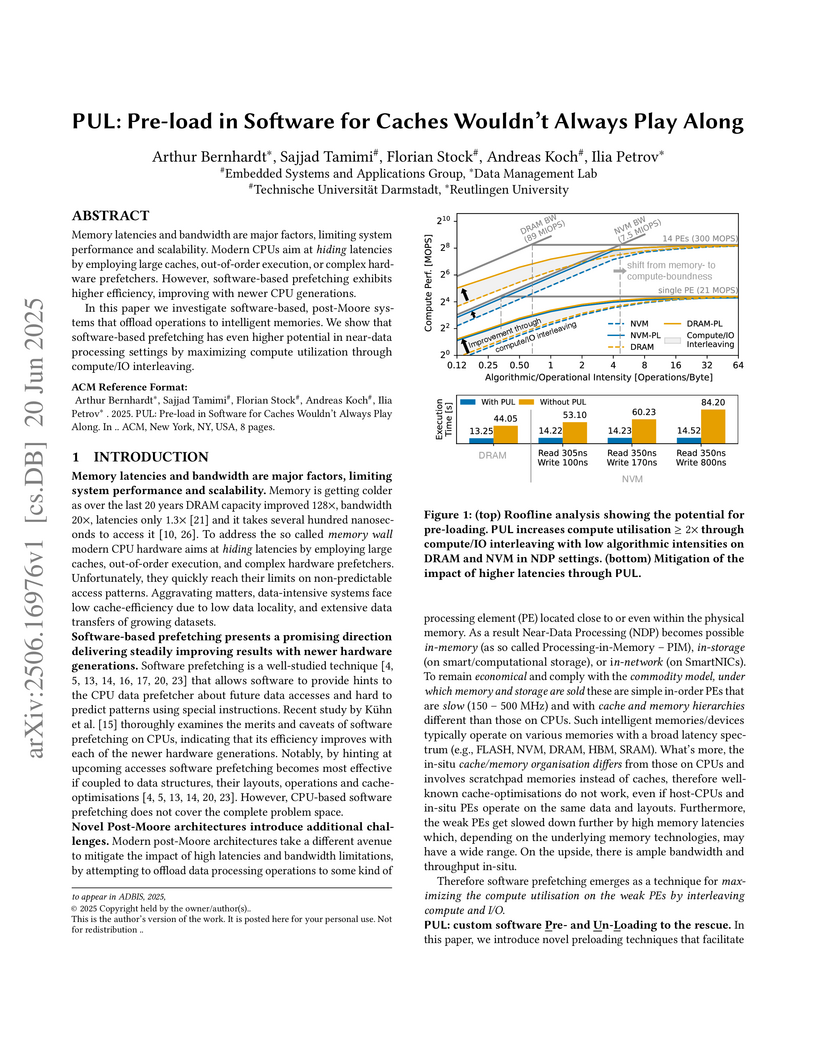
20 Jun 2025
Memory latencies and bandwidth are major factors, limiting system performance and scalability. Modern CPUs aim at hiding latencies by employing large caches, out-of-order execution, or complex hardware prefetchers. However, software-based prefetching exhibits higher efficiency, improving with newer CPU generations.
In this paper we investigate software-based, post-Moore systems that offload operations to intelligent memories. We show that software-based prefetching has even higher potential in near-data processing settings by maximizing compute utilization through compute/IO interleaving.

20 Nov 2022
Reliable and accurate registration of patient-specific brain magnetic resonance imaging (MRI) scans containing pathologies is challenging due to tissue appearance changes. This paper describes our contribution to the Registration of the longitudinal brain MRI task of the Brain Tumor Sequence Registration Challenge 2022 (BraTS-Reg 2022). We developed an enhanced unsupervised learning-based method that extends the iRegNet. In particular, incorporating an unsupervised learning-based paradigm as well as several minor modifications to the network pipeline, allows the enhanced iRegNet method to achieve respectable results. Experimental findings show that the enhanced self-supervised model is able to improve the initial mean median registration absolute error (MAE) from 8.20 (7.62) mm to the lowest value of 3.51 (3.50) for the training set while achieving an MAE of 2.93 (1.63) mm for the validation set. Additional qualitative validation of this study was conducted through overlaying pre-post MRI pairs before and after the de-formable registration. The proposed method scored 5th place during the testing phase of the MICCAI BraTS-Reg 2022 challenge. The docker image to reproduce our BraTS-Reg submission results will be publicly available.
There are no more papers matching your filters at the moment.
