
07 Dec 2025
Large Language Model (LLM) agents are emerging to transform daily life. However, existing LLM agents primarily follow a reactive paradigm, relying on explicit user instructions to initiate services, which increases both physical and cognitive workload. In this paper, we propose ProAgent, the first end-to-end proactive agent system that harnesses massive sensory contexts and LLM reasoning to deliver proactive assistance. ProAgent first employs a proactive-oriented context extraction approach with on-demand tiered perception to continuously sense the environment and derive hierarchical contexts that incorporate both sensory and persona cues. ProAgent then adopts a context-aware proactive reasoner to map these contexts to user needs and tool calls, providing proactive assistance. We implement ProAgent on Augmented Reality (AR) glasses with an edge server and extensively evaluate it on a real-world testbed, a public dataset, and through a user study. Results show that ProAgent achieves up to 33.4% higher proactive prediction accuracy, 16.8% higher tool-calling F1 score, and notable improvements in user satisfaction over state-of-the-art baselines, marking a significant step toward proactive assistants. A video demonstration of ProAgent is available at this https URL.

09 Dec 2025
CLINICALTRIALSHUB unifies clinical trial data from structured registries and unstructured scientific literature, expanding access to structured trial information by 83.8% and providing evidence-grounded, interactive question answering. This platform, developed at The Ohio State University, leverages advanced Large Language Models to streamline information discovery and synthesis for medical professionals and researchers.
09 Dec 2025
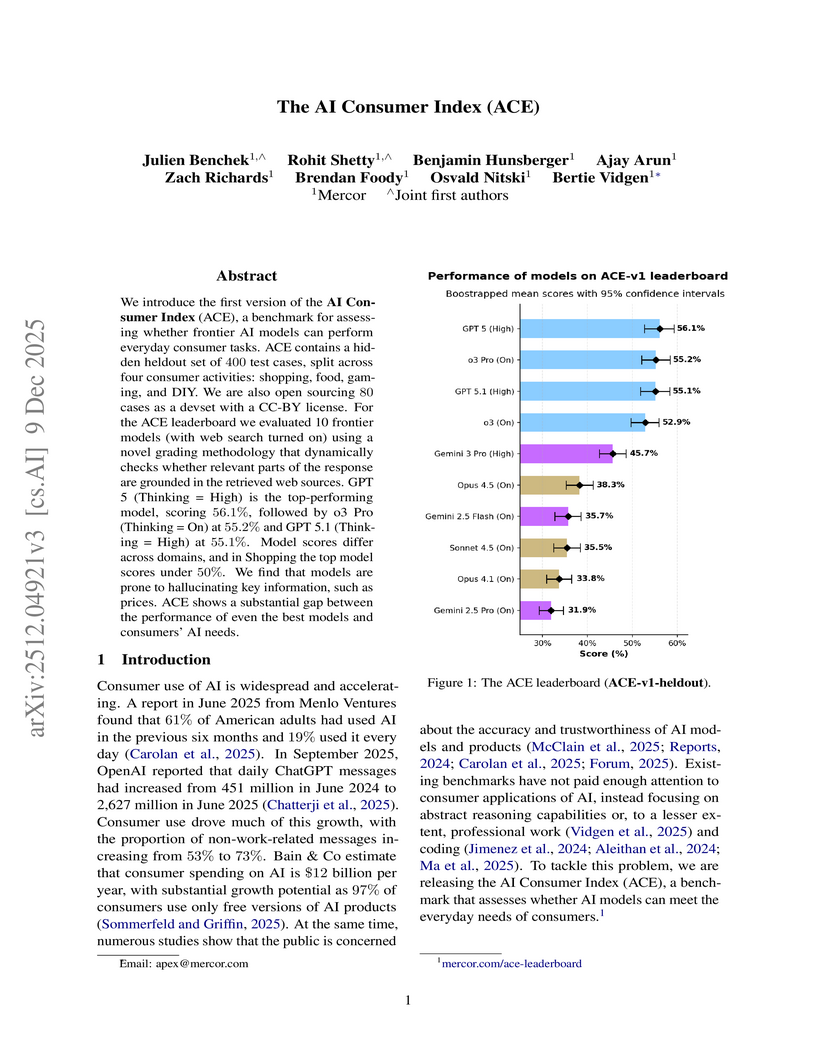
We introduce the first version of the AI Consumer Index (ACE), a benchmark for assessing whether frontier AI models can perform everyday consumer tasks. ACE contains a hidden heldout set of 400 test cases, split across four consumer activities: shopping, food, gaming, and DIY. We are also open sourcing 80 cases as a devset with a CC-BY license. For the ACE leaderboard we evaluated 10 frontier models (with websearch turned on) using a novel grading methodology that dynamically checks whether relevant parts of the response are grounded in the retrieved web sources. GPT 5 (Thinking = High) is the top-performing model, scoring 56.1%, followed by o3 Pro (Thinking = On) at 55.2% and GPT 5.1 (Thinking = High) at 55.1%. Model scores differ across domains, and in Shopping the top model scores under 50\%. We find that models are prone to hallucinating key information, such as prices. ACE shows a substantial gap between the performance of even the best models and consumers' AI needs.

09 Dec 2025
Recent advances in Multimodal Large Language Models (MLLMs) have enabled their use as intelligent agents for smartphone operation. However, existing methods depend on the Android Debug Bridge (ADB) for data transmission and action execution, limiting their applicability to Android devices. In this work, we introduce the novel Embodied Smartphone Operation (ESO) task and present See-Control, a framework that enables smartphone operation via direct physical interaction with a low-DoF robotic arm, offering a platform-agnostic solution. See-Control comprises three key components: (1) an ESO benchmark with 155 tasks and corresponding evaluation metrics; (2) an MLLM-based embodied agent that generates robotic control commands without requiring ADB or system back-end access; and (3) a richly annotated dataset of operation episodes, offering valuable resources for future research. By bridging the gap between digital agents and the physical world, See-Control provides a concrete step toward enabling home robots to perform smartphone-dependent tasks in realistic environments.

09 Dec 2025
Collective memory -- community members' interconnected memories and impressions of the group -- is essential to the community's culture and identity. Its development requires members' continuous participatory contribution and sensemaking. However, existing works mainly adopt a holistic sociological perspective to analyze well-developed collective memory, less focusing on member-level conceptualization of this possession or what the co-contribution practices can be. Therefore, this work alternatively adopts the latter perspective and probes such interpretative and interactional patterns with two mobile systems. With one being a locative narrative and exploration system condensed from existing literature's design frameworks, and the other being a conventional online forum representing current practices, they served as the anchors of observation for our two-week, mixed-methods field study (n=38) on a university campus. A core debate we have identified was to retrospectively contemplate or document the presence as a history for the future. This also subsequently impacted the narrative focuses, expectations of collective memory constituents, and the ways participants seek inspiration from the group. We further extracted design considerations that could better embrace the diverse conceptualizations of collective memory and bond different community members together. Lastly, revisiting and reflecting on our design, we provided extra insights on designing devoted locative narrative experiences for community-driven UGC platforms.

05 Dec 2025
What if users could meet their future selves today? AI-generated future selves simulate meaningful encounters with a digital twin decades in the future. As AI systems advance, combining cloned voices, age-progressed facial rendering, and autobiographical narratives, a central question emerges: Does the modality of these future selves alter their psychological and affective impact? How might a text-based chatbot, a voice-only system, or a photorealistic avatar shape present-day decisions and our feeling of connection to the future? We report a randomized controlled study (N=92) evaluating three modalities of AI-generated future selves (text, voice, avatar) against a neutral control condition. We also report a systematic model evaluation between Claude 4 and three other Large Language Models (LLMs), assessing Claude 4 across psychological and interaction dimensions and establishing conversational AI quality as a critical determinant of intervention effectiveness. All personalized modalities strengthened Future Self-Continuity (FSC), emotional well-being, and motivation compared to control, with avatar producing the largest vividness gains, yet with no significant differences between formats. Interaction quality metrics, particularly persuasiveness, realism, and user engagement, emerged as robust predictors of psychological and affective outcomes, indicating that how compelling the interaction feels matters more than the form it takes. Content analysis found thematic patterns: text emphasized career planning, while voice and avatar facilitated personal reflection. Claude 4 outperformed ChatGPT 3.5, Llama 4, and Qwen 3 in enhancing psychological, affective, and FSC outcomes.

08 Dec 2025
Adversaries (hackers) attempting to infiltrate networks frequently face uncertainty in their operational environments. This research explores the ability to model and detect when they exhibit ambiguity aversion, a cognitive bias reflecting a preference for known (versus unknown) probabilities. We introduce a novel methodological framework that (1) leverages rich, multi-modal data from human-subjects red-team experiments, (2) employs a large language model (LLM) pipeline to parse unstructured logs into MITRE ATT&CK-mapped action sequences, and (3) applies a new computational model to infer an attacker's ambiguity aversion level in near-real time. By operationalizing this cognitive trait, our work provides a foundational component for developing adaptive cognitive defense strategies.

10 Dec 2025
We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.

05 Dec 2025
While commendable progress has been made in user-centric research on mobile assistive systems for blind and low-vision (BLV) individuals, references that directly inform robot navigation design remain rare. To bridge this gap, we conducted a comprehensive human study involving interviews with 26 guide dog handlers, four white cane users, nine guide dog trainers, and one O\&M trainer, along with 15+ hours of observing guide dog-assisted walking. After de-identification, we open-sourced the dataset to promote human-centered development and informed decision-making for assistive systems for BLV people. Building on insights from this formative study, we developed GuideNav, a vision-only, teach-and-repeat navigation system. Inspired by how guide dogs are trained and assist their handlers, GuideNav autonomously repeats a path demonstrated by a sighted person using a robot. Specifically, the system constructs a topological representation of the taught route, integrates visual place recognition with temporal filtering, and employs a relative pose estimator to compute navigation actions - all without relying on costly, heavy, power-hungry sensors such as LiDAR. In field tests, GuideNav consistently achieved kilometer-scale route following across five outdoor environments, maintaining reliability despite noticeable scene variations between teach and repeat runs. A user study with 3 guide dog handlers and 1 guide dog trainer further confirmed the system's feasibility, marking (to our knowledge) the first demonstration of a quadruped mobile system retrieving a path in a manner comparable to guide dogs.

08 Dec 2025
LLM-based agents are rapidly being plugged into expert decision-support, yet in messy, high-stakes settings they rarely make the team smarter: human-AI teams often underperform the best individual, experts oscillate between verification loops and over-reliance, and the promised complementarity does not materialise. We argue this is not just a matter of accuracy, but a fundamental gap in how we conceive AI assistance: expert decisions are made through collaborative cognitive processes where mental models, goals, and constraints are continually co-constructed, tested, and revised between human and AI. We propose Collaborative Causal Sensemaking (CCS) as a research agenda and organizing framework for decision-support agents: systems designed as partners in cognitive work, maintaining evolving models of how particular experts reason, helping articulate and revise goals, co-constructing and stress-testing causal hypotheses, and learning from the outcomes of joint decisions so that both human and agent improve over time. We sketch challenges around training ecologies that make collaborative thinking instrumentally valuable, representations and interaction protocols for co-authored models, and evaluation centred on trust and complementarity. These directions can reframe MAS research around agents that participate in collaborative sensemaking and act as AI teammates that think with their human partners.

08 Dec 2025
Deep learning models have achieved remarkable success across various domains, yet their learned representations and decision-making processes remain largely opaque and hard to interpret. This work introduces HOLE (Homological Observation of Latent Embeddings), a method for analyzing and interpreting deep neural networks through persistent homology. HOLE extracts topological features from neural activations and presents them using a suite of visualization techniques, including Sankey diagrams, heatmaps, dendrograms, and blob graphs. These tools facilitate the examination of representation structure and quality across layers. We evaluate HOLE on standard datasets using a range of discriminative models, focusing on representation quality, interpretability across layers, and robustness to input perturbations and model compression. The results indicate that topological analysis reveals patterns associated with class separation, feature disentanglement, and model robustness, providing a complementary perspective for understanding and improving deep learning systems.

09 Dec 2025
Image captioning is essential in many fields including assisting visually impaired individuals, improving content management systems, and enhancing human-computer interaction. However, a recent challenge in this domain is dealing with low-resolution image (LRI). While performance can be improved by using larger models like transformers for encoding, these models are typically heavyweight, demanding significant computational resources and memory, leading to challenges in retraining. To address this, the proposed SOLI (Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning) approach presents a solution specifically designed for lightweight, low-resolution images captioning. It employs a Siamese network architecture to optimize latent embeddings, enhancing the efficiency and accuracy of the image-to-text translation process. By focusing on a dual-pathway neural network structure, SOLI minimizes computational overhead without sacrificing performance, making it an ideal choice for training on resource-constrained scenarios.

08 Dec 2025
Researchers at MIT Media Lab and collaborators developed an AI system that generates personalized, multimodal future self avatars to help individuals explore major life decisions. The system demonstrates that interacting with these AI-generated digital twins can influence decision outcomes, expand the consideration of previously unthought-of choices, and highlights the importance of cognitive and meaning-making aspects over visual realism for effective decision support.

05 Dec 2025
Large language models (LLMs) are promising tools for scaffolding students' English writing skills, but their effectiveness in real-time K-12 classrooms remains underexplored. Addressing this gap, our study examines the benefits and limitations of using LLMs as real-time learning support, considering how classroom constraints, such as diverse proficiency levels and limited time, affect their effectiveness. We conducted a deployment study with 157 eighth-grade students in a South Korean middle school English class over six weeks. Our findings reveal that while scaffolding improved students' ability to compose grammatically correct sentences, this step-by-step approach demotivated lower-proficiency students and increased their system reliance. We also observed challenges to classroom dynamics, where extroverted students often dominated the teacher's attention, and the system's assistance made it difficult for teachers to identify struggling students. Based on these findings, we discuss design guidelines for integrating LLMs into real-time writing classes as inclusive educational tools.

28 Nov 2025
Access to justice remains a global challenge, with many citizens still finding it difficult to seek help from the justice system when facing legal issues. Although the internet provides abundant legal information and services, navigating complex websites, understanding legal terminology, and filling out procedural forms continue to pose barriers to accessing justice. This paper introduces the LegalWebAgent framework that employs a web agent powered by multimodal large language models to bridge the gap in access to justice for ordinary citizens. The framework combines the natural language understanding capabilities of large language models with multimodal perception, enabling a complete process from user query to concrete action. It operates in three stages: the Ask Module understands user needs through natural language processing; the Browse Module autonomously navigates webpages, interacts with page elements (including forms and calendars), and extracts information from HTML structures and webpage screenshots; the Act Module synthesizes information for users or performs direct actions like form completion and schedule booking. To evaluate its effectiveness, we designed a benchmark test covering 15 real-world tasks, simulating typical legal service processes relevant to Québec civil law users, from problem identification to procedural operations. Evaluation results show LegalWebAgent achieved a peak success rate of 86.7%, with an average of 84.4% across all tested models, demonstrating high autonomy in complex real-world scenarios.

29 Nov 2025

Imitation learning provides a promising approach to dexterous hand manipulation, but its effectiveness is limited by the lack of large-scale, high-fidelity data. Existing data-collection pipelines suffer from inaccurate motion retargeting, low data-collection efficiency, and missing high-resolution fingertip tactile sensing. We address this gap with MILE, a mechanically isomorphic teleoperation and data-collection system co-designed from human hand to exoskeleton to robotic hand. The exoskeleton is anthropometrically derived from the human hand, and the robotic hand preserves one-to-one joint-position isomorphism, eliminating nonlinear retargeting and enabling precise, natural control. The exoskeleton achieves a multi-joint mean absolute angular error below one degree, while the robotic hand integrates compact fingertip visuotactile modules that provide high-resolution tactile observations. Built on this retargeting-free interface, we teleoperate complex, contact-rich in-hand manipulation and efficiently collect a multimodal dataset comprising high-resolution fingertip visuotactile signals, RGB-D images, and joint positions. The teleoperation pipeline achieves a mean success rate improvement of 64%. Incorporating fingertip tactile observations further increases the success rate by an average of 25% over the vision-only baseline, validating the fidelity and utility of the dataset. Further details are available at: this https URL.

02 Dec 2025
Developing and validating psychometric scales requires large samples, multiple testing phases, and substantial resources. Recent advances in Large Language Models (LLMs) enable the generation of synthetic participant data by prompting models to answer items while impersonating individuals of specific demographic profiles, potentially allowing in silico piloting before real data collection. Across four preregistered studies (N = circa 300 each), we tested whether LLM-simulated datasets can reproduce the latent structures and measurement properties of human responses. In Studies 1-2, we compared LLM-generated data with real datasets for two validated scales; in Studies 3-4, we created new scales using EFA on simulated data and then examined whether these structures generalized to newly collected human samples. Simulated datasets replicated the intended factor structures in three of four studies and showed consistent configural and metric invariance, with scalar invariance achieved for the two newly developed scales. However, correlation-based tests revealed substantial differences between real and synthetic datasets, and notable discrepancies appeared in score distributions and variances. Thus, while LLMs capture group-level latent structures, they do not approximate individual-level data properties. Simulated datasets also showed full internal invariance across gender. Overall, LLM-generated data appear useful for early-stage, group-level psychometric prototyping, but not as substitutes for individual-level validation. We discuss methodological limitations, risks of bias and data pollution, and ethical considerations related to in silico psychometric simulations.

03 Dec 2025

YOLOA introduces a real-time system that unifies object detection and affordance learning, leveraging an LLM Adapter for language-guided cross-modal refinement. This approach achieved a mAP of 52.8 on ADG-Det and 73.1 on IIT-Heat, while its lightweight variant reached up to 846.24 FPS.

01 Dec 2025
Large language models (LLMs) are increasingly used for persuasion, such as in political communication and marketing, where they affect how people think, choose, and act. Yet, empirical findings on the effectiveness of LLMs in persuasion compared to humans remain inconsistent. The aim of this study was to systematically review and meta-analytically assess whether LLMs differ from humans in persuasive effectiveness. We identified studies with 17,422 participants primarily recruited from English-speaking countries and effect size estimates. Egger's test indicated potential small-study effects (), but the trim-and-fill analysis did not impute any missing studies, suggesting a low risk of publication bias. We then compute the standardized effect sizes based on Hedges' . The results show no significant overall difference in persuasive performance between LLMs and humans (, ). However, we observe substantial heterogeneity across studies (), suggesting that persuasiveness strongly depends on contextual factors. In separate exploratory moderator analyses, no individual factor (e.g., LLM model, conversation design, or domain) reached statistical significance, which may be due to the limited number of studies. When considered jointly in a combined model, these factors explained a large proportion of the between-study variance (), and residual heterogeneity is low (). Although based on a small number of studies, this suggests that differences in LLM model, conversation design, and domain are important contextual factors in shaping persuasive performance, and that single-factor tests may understate their influence. Our results highlight that LLMs can match human performance in persuasion, but their success depends strongly on how they are implemented and embedded in communication contexts.

25 Nov 2025
Patients frequently seek information during their medical journeys, but the rising volume of digital patient messages has strained healthcare systems. Large language models (LLMs) offer promise in generating draft responses for clinicians, yet how physicians refine these drafts remains underexplored. We present a mixed-methods study with nine ophthalmologists answering 144 cataract surgery questions across three conditions: writing from scratch, directly editing LLM drafts, and instruction-based indirect editing. Our quantitative and qualitative analyses reveal that while LLM outputs were generally accurate, occasional errors and automation bias revealed the need for human oversight. Contextualization--adapting generic answers to local practices and patient expectations--emerged as a dominant form of editing. Editing workflows revealed trade-offs: indirect editing reduced effort but introduced errors, while direct editing ensured precision but with higher workload. We conclude with design and policy implications for building safe, scalable LLM-assisted clinical communication systems.
There are no more papers matching your filters at the moment.
