
07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

08 Dec 2025

Researchers from Alibaba Group and Wuhan University developed MUSE, a multimodal search-based framework for lifelong user interest modeling that integrates rich semantic information across both retrieval and fine-grained modeling stages. Deployed in Taobao's display advertising system, MUSE achieved a +12.6% CTR, +5.1% RPM, and +11.4% ROI in online A/B tests.

09 Dec 2025
Although existing multimodal recommendation models have shown promising performance, their effectiveness continues to be limited by the pervasive data sparsity problem. This problem arises because users typically interact with only a small subset of available items, leading existing models to arbitrarily treat unobserved items as negative samples. To this end, we propose VI-MMRec, a model-agnostic and training cost-free framework that enriches sparse user-item interactions via similarity-aware virtual user-item interactions. These virtual interactions are constructed based on modality-specific feature similarities of user-interacted items. Specifically, VI-MMRec introduces two different strategies: (1) Overlay, which independently aggregates modality-specific similarities to preserve modality-specific user preferences, and (2) Synergistic, which holistically fuses cross-modal similarities to capture complementary user preferences. To ensure high-quality augmentation, we design a statistically informed weight allocation mechanism that adaptively assigns weights to virtual user-item interactions based on dataset-specific modality relevance. As a plug-and-play framework, VI-MMRec seamlessly integrates with existing models to enhance their performance without modifying their core architecture. Its flexibility allows it to be easily incorporated into various existing models, maximizing performance with minimal implementation effort. Moreover, VI-MMRec introduces no additional overhead during training, making it significantly advantageous for practical deployment. Comprehensive experiments conducted on six real-world datasets using seven state-of-the-art multimodal recommendation models validate the effectiveness of our VI-MMRec.
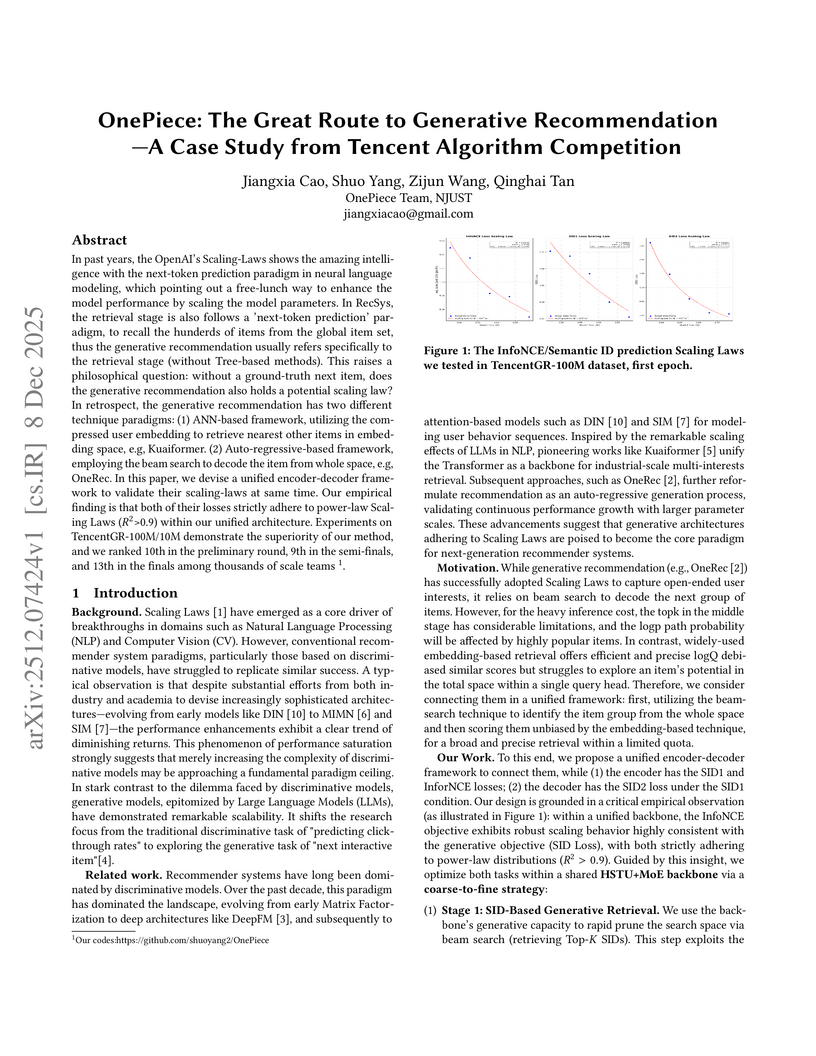
08 Dec 2025
In past years, the OpenAI's Scaling-Laws shows the amazing intelligence with the next-token prediction paradigm in neural language modeling, which pointing out a free-lunch way to enhance the model performance by scaling the model parameters. In RecSys, the retrieval stage is also follows a 'next-token prediction' paradigm, to recall the hunderds of items from the global item set, thus the generative recommendation usually refers specifically to the retrieval stage (without Tree-based methods). This raises a philosophical question: without a ground-truth next item, does the generative recommendation also holds a potential scaling law? In retrospect, the generative recommendation has two different technique paradigms: (1) ANN-based framework, utilizing the compressed user embedding to retrieve nearest other items in embedding space, e.g, Kuaiformer. (2) Auto-regressive-based framework, employing the beam search to decode the item from whole space, e.g, OneRec. In this paper, we devise a unified encoder-decoder framework to validate their scaling-laws at same time. Our empirical finding is that both of their losses strictly adhere to power-law Scaling Laws (>0.9) within our unified architecture.

08 Dec 2025


Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.

09 Dec 2025
Ontology-based knowledge graph (KG) construction is a core technology that enables multidimensional understanding and advanced reasoning over domain knowledge. Industrial standards, in particular, contain extensive technical information and complex rules presented in highly structured formats that combine tables, scopes of application, constraints, exceptions, and numerical calculations, making KG construction especially challenging. In this study, we propose a method that organizes such documents into a hierarchical semantic structure, decomposes sentences and tables into atomic propositions derived from conditional and numerical rules, and integrates them into an ontology-knowledge graph through LLM-based triple extraction. Our approach captures both the hierarchical and logical structures of documents, effectively representing domain-specific semantics that conventional methods fail to reflect. To verify its effectiveness, we constructed rule, table, and multi-hop QA datasets, as well as a toxic clause detection dataset, from industrial standards, and implemented an ontology-aware KG-RAG framework for comparative evaluation. Experimental results show that our method achieves significant performance improvements across all QA types compared to existing KG-RAG approaches. This study demonstrates that reliable and scalable knowledge representation is feasible even for industrial documents with intertwined conditions, constraints, and scopes, contributing to future domain-specific RAG development and intelligent document management.

08 Dec 2025
Increasingly, attorneys are interested in moving beyond keyword and semantic search to improve the efficiency of how they find key information during a document review task. Large language models (LLMs) are now seen as tools that attorneys can use to ask natural language questions of their data during document review to receive accurate and concise answers. This study evaluates retrieval strategies within Microsoft Azure's Retrieval-Augmented Generation (RAG) framework to identify effective approaches for Early Case Assessment (ECA) in eDiscovery. During ECA, legal teams analyze data at the outset of a matter to gain a general understanding of the data and attempt to determine key facts and risks before beginning full-scale review. In this paper, we compare the performance of Azure AI Search's keyword, semantic, vector, hybrid, and hybrid-semantic retrieval methods. We then present the accuracy, relevance, and consistency of each method's AI-generated responses. Legal practitioners can use the results of this study to enhance how they select RAG configurations in the future.

06 Dec 2025
Scientists have always used the studies and research of other researchers to achieve new objectives and perspectives. In particular, employing and operating the measured data in previous studies is so practical. Searching the content of other scientists' articles is a challenge that researchers have always struggled with. Nowadays, the use of knowledge graphs as a semantic database has helped a lot in saving and retrieving scholarly knowledge. Such technologies are crucial to upgrading traditional search systems to smart knowledge retrieval, which is crucial to getting the most relevant answers for a user query, especially in information and knowledge management. However, in most cases, only the metadata of a paper is searchable, and it is still cumbersome for scientists to have access to the content of the papers. In this paper, we present a novel method of faceted search \emph{structured content} for comparing and filtering measured data in scholarly knowledge graphs while different units of measurement are used in different studies. This search system proposes applicable units as facets to the user and would dynamically integrate content from further remote knowledge graphs to materialize the scholarly knowledge graph and achieve a higher order of exploration usability on scholarly content, which can be filtered to better satisfy the user's information needs. The state of the art is that, by using our faceted search system, users can not only search the contents of scientific articles, but also compare and filter heterogeneous data.

08 Dec 2025
In legal matters, text classification models are most often used to filter through large datasets in search of documents that meet certain pre-selected criteria like relevance to a certain subject matter, such as legally privileged communications and attorney-directed documents. In this context, large language models have demonstrated strong performance. This paper presents an empirical study investigating the role of randomness in LLM-based classification for attorney-client privileged document detection, focusing on four key dimensions: (1) the effectiveness of LLMs in identifying legally privileged documents, (2) the influence of randomness control parameters on classification outputs, (3) their impact on overall classification performance, and (4) a methodology for leveraging randomness to enhance accuracy. Experimental results showed that LLMs can identify privileged documents effectively, randomness control parameters have minimal impact on classification performance, and importantly, our developed methodology for leveraging randomness can have a significant impact on improving accuracy. Notably, this methodology that leverages randomness could also enhance a corporation's confidence in an LLM's output when incorporated into its sanctions-compliance processes. As organizations increasingly rely on LLMs to augment compliance workflows, reducing output variability helps build internal and regulatory confidence in LLM-derived sanctions-screening decisions.

08 Dec 2025
The rapid increase in digital image creation and retention presents substantial challenges during legal discovery, digital archive, and content management. Corporations and legal teams must organize, analyze, and extract meaningful insights from large image collections under strict time pressures, making manual review impractical and costly. These demands have intensified interest in automated methods that can efficiently organize and describe large-scale image datasets. This paper presents a systematic investigation of automated cluster description generation through the integration of image clustering, image captioning, and large language models (LLMs). We apply K-means clustering to group images into 20 visually coherent clusters and generate base captions using the Azure AI Vision API. We then evaluate three critical dimensions of the cluster description process: (1) image sampling strategies, comparing random, centroid-based, stratified, hybrid, and density-based sampling against using all cluster images; (2) prompting techniques, contrasting standard prompting with chain-of-thought prompting; and (3) description generation methods, comparing LLM-based generation with traditional TF-IDF and template-based approaches. We assess description quality using semantic similarity and coverage metrics. Results show that strategic sampling with 20 images per cluster performs comparably to exhaustive inclusion while significantly reducing computational cost, with only stratified sampling showing modest degradation. LLM-based methods consistently outperform TF-IDF baselines, and standard prompts outperform chain-of-thought prompts for this task. These findings provide practical guidance for deploying scalable, accurate cluster description systems that support high-volume workflows in legal discovery and other domains requiring automated organization of large image collections.

09 Dec 2025
We present ClinicalTrialsHub, an interactive search-focused platform that consolidates all data from this http URL and augments it by automatically extracting and structuring trial-relevant information from PubMed research articles. Our system effectively increases access to structured clinical trial data by 83.8% compared to relying on this http URL alone, with potential to make access easier for patients, clinicians, researchers, and policymakers, advancing evidence-based medicine. ClinicalTrialsHub uses large language models such as GPT-5.1 and Gemini-3-Pro to enhance accessibility. The platform automatically parses full-text research articles to extract structured trial information, translates user queries into structured database searches, and provides an attributed question-answering system that generates evidence-grounded answers linked to specific source sentences. We demonstrate its utility through a user study involving clinicians, clinical researchers, and PhD students of pharmaceutical sciences and nursing, and a systematic automatic evaluation of its information extraction and question answering capabilities.

04 Dec 2025
Alibaba Group researchers developed LORE, a large generative model framework for e-commerce search relevance, which systematically deconstructs the relevance task and employs a two-stage training paradigm. The framework successfully integrates knowledge, multi-modal understanding, and rule adherence, leading to a cumulative +27% improvement in the online GoodRate metric and outperforming state-of-the-art LLMs on a custom e-commerce benchmark.
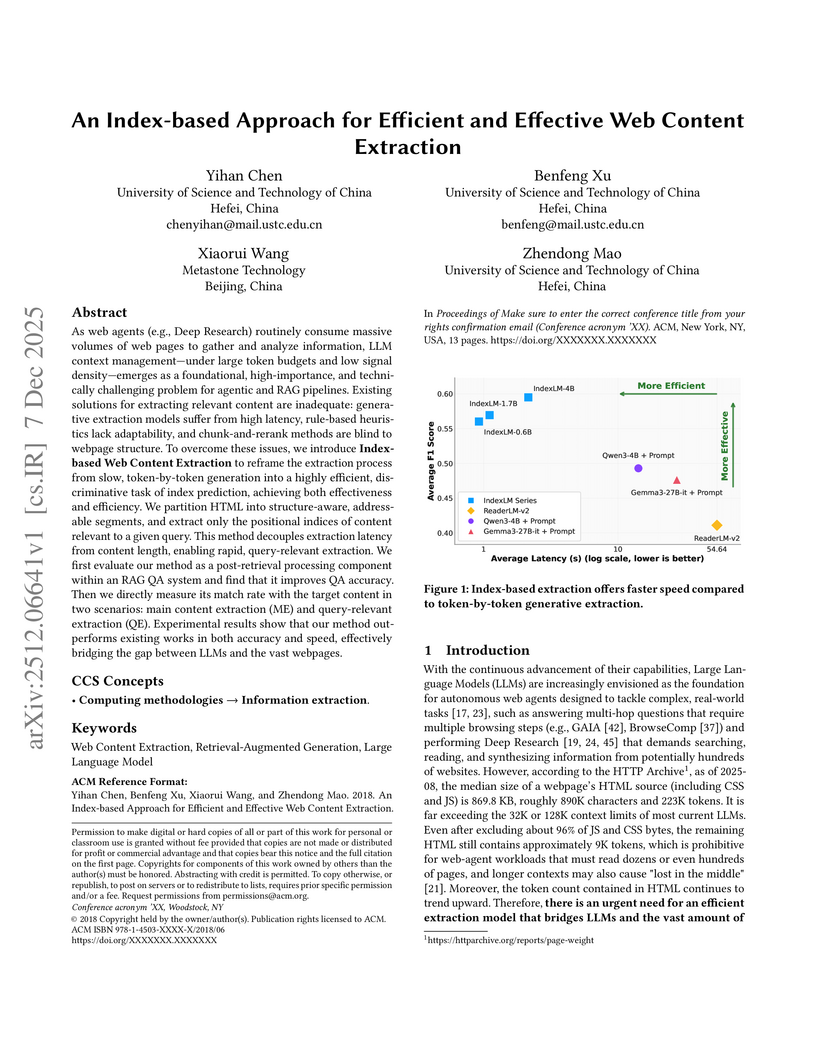
07 Dec 2025
As web agents (e.g., Deep Research) routinely consume massive volumes of web pages to gather and analyze information, LLM context management -- under large token budgets and low signal density -- emerges as a foundational, high-importance, and technically challenging problem for agentic and RAG pipelines. Existing solutions for extracting relevant content are inadequate: generative extraction models suffer from high latency, rule-based heuristics lack adaptability, and chunk-and-rerank methods are blind to webpage structure. To overcome these issues, we introduce Index-based Web Content Extraction to reframe the extraction process from slow, token-by-token generation into a highly efficient, discriminative task of index prediction, achieving both effectiveness and efficiency. We partition HTML into structure-aware, addressable segments, and extract only the positional indices of content relevant to a given query. This method decouples extraction latency from content length, enabling rapid, query-relevant extraction. We first evaluate our method as a post-retrieval processing component within an RAG QA system and find that it improves QA accuracy. Then we directly measure its match rate with the target content in two scenarios: main content extraction (ME) and query-relevant extraction (QE). Experimental results show that our method outperforms existing works in both accuracy and speed, effectively bridging the gap between LLMs and the vast webpages.

02 Dec 2025


WorldMM, developed by researchers at KAIST, NTU, and DeepAuto.ai, introduces a dynamic multimodal memory agent for reasoning over ultra-long videos. The system achieved an average accuracy of 69.5% across five long video question-answering benchmarks, representing an 8.4% performance gain over the strongest prior baseline by adaptively integrating textual and visual memories across multiple temporal scales.

04 Dec 2025
AIVisor, an agentic retrieval-augmented LLM for student advising, was used to examine how personalization affects system performance across multiple evaluation dimensions. Using twelve authentic advising questions intentionally designed to stress lexical precision, we compared ten personalized and non-personalized system configurations and analyzed outcomes with a Linear Mixed-Effects Model across lexical (BLEU, ROUGE-L), semantic (METEOR, BERTScore), and grounding (RAGAS) metrics. Results showed a consistent trade-off: personalization reliably improved reasoning quality and grounding, yet introduced a significant negative interaction on semantic similarity, driven not by poorer answers but by the limits of current metrics, which penalize meaningful personalized deviations from generic reference texts. This reveals a structural flaw in prevailing LLM evaluation methods, which are ill-suited for assessing user-specific responses. The fully integrated personalized configuration produced the highest overall gains, suggesting that personalization can enhance system effectiveness when evaluated with appropriate multidimensional metrics. Overall, the study demonstrates that personalization produces metric-dependent shifts rather than uniform improvements and provides a methodological foundation for more transparent and robust personalization in agentic AI.

06 Dec 2025
Interpretability is central to trustworthy machine learning, yet existing metrics rarely quantify how effectively data support an interpretive representation. We propose Interpretive Efficiency, a normalized, task-aware functional that measures the fraction of task-relevant information transmitted through an interpretive channel. The definition is grounded in five axioms ensuring boundedness, Blackwell-style monotonicity, data-processing stability, admissible invariance, and asymptotic consistency. We relate the functional to mutual information and derive a local Fisher-geometric expansion, then establish asymptotic and finite-sample estimation guarantees using standard empirical-process tools. Experiments on controlled image and signal tasks demonstrate that the measure recovers theoretical orderings, exposes representational redundancy masked by accuracy, and correlates with robustness, making it a practical, theory-backed diagnostic for representation design.

03 Dec 2025
Researchers from Carnegie Mellon University developed a hybrid framework utilizing a Large Language Model (LLM) as an explainable re-ranker for recommendation systems. This approach refines initial candidate lists from traditional models, improving ranking accuracy while generating explanations rated at an average of 4.3 for persuasiveness, significantly outperforming zero-shot explanations (3.6 average).

07 Dec 2025
Retrieval-Augmented Generation (RAG) systems have significantly reduced hallucinations in Large Language Models (LLMs) by grounding responses in external context. However, standard RAG architectures suffer from a critical vulnerability: Retrieval Sycophancy. When presented with a query based on a false premise or a common misconception, vector-based retrievers tend to fetch documents that align with the user's bias rather than objective truth, leading the model to "hallucinate with citations."
In this work, we introduce Falsification-Verification Alignment RAG (FVA-RAG), a framework that shifts the retrieval paradigm from Inductive Verification (seeking support) to Deductive Falsification (seeking disproof). Unlike existing "Self-Correction" methods that rely on internal consistency, FVA-RAG deploys a distinct Adversarial Retrieval Policy that actively generates "Kill Queries"-targeted search terms designed to surface contradictory evidence. We introduce a dual-verification mechanism that explicitly weighs the draft answer against this "Anti-Context." Preliminary experiments on a dataset of common misconceptions demonstrate that FVA-RAG significantly improves robustness against sycophantic hallucinations compared to standard RAG baselines, effectively acting as an inference-time "Red Team" for factual generation.

07 Dec 2025
Researchers at Kuaishou Technology developed a system that predicts future live-streaming content segments using multi-modal semantic understanding and a Transformer-based model to enhance recommendations. This approach improved core platform metrics in A/B tests, including a +0.457% increase in Exposure and a +2.480% increase in Gift Count.

08 Dec 2025
In recommender systems, user-item interactions can be modeled as a bipartite graph, where user and item nodes are connected by undirected edges. This graph-based view has motivated the rapid adoption of graph neural networks (GNNs), which often outperform collaborative filtering (CF) methods such as latent factor models, deep neural networks, and generative strategies. Yet, despite their empirical success, the reasons why GNNs offer systematic advantages over other CF approaches remain only partially understood. This monograph advances a topology-centered perspective on GNN-based recommendation. We argue that a comprehensive understanding of these models' performance should consider the structural properties of user-item graphs and their interaction with GNN architectural design. To support this view, we introduce a formal taxonomy that distills common modeling patterns across eleven representative GNN-based recommendation approaches and consolidates them into a unified conceptual pipeline. We further formalize thirteen classical and topological characteristics of recommendation datasets and reinterpret them through the lens of graph machine learning. Using these definitions, we analyze the considered GNN-based recommender architectures to assess how and to what extent they encode such properties. Building on this analysis, we derive an explanatory framework that links measurable dataset characteristics to model behavior and performance. Taken together, this monograph re-frames GNN-based recommendation through its topological underpinnings and outlines open theoretical, data-centric, and evaluation challenges for the next generation of topology-aware recommender systems.
There are no more papers matching your filters at the moment.
