
07 Dec 2025
Researchers from Microsoft Research Asia, Xi'an Jiaotong University, and Fudan University developed VideoVLA, a robot manipulator that repurposes large pre-trained video generation models. This system jointly predicts future video states and corresponding actions, achieving enhanced generalization capabilities for novel objects and skills in both simulated and real-world environments.

09 Dec 2025
Astribot's Lumo-1 introduces a generalist Vision-Language-Action model that explicitly unifies robot reasoning with physical control, demonstrating superior performance in generalizable pick-and-place, out-of-distribution scenarios, and complex long-horizon dexterous tasks on a bimanual mobile manipulator. The system shows improved embodied reasoning and robustness, partly through a novel spatial action tokenizer and multi-stage training.
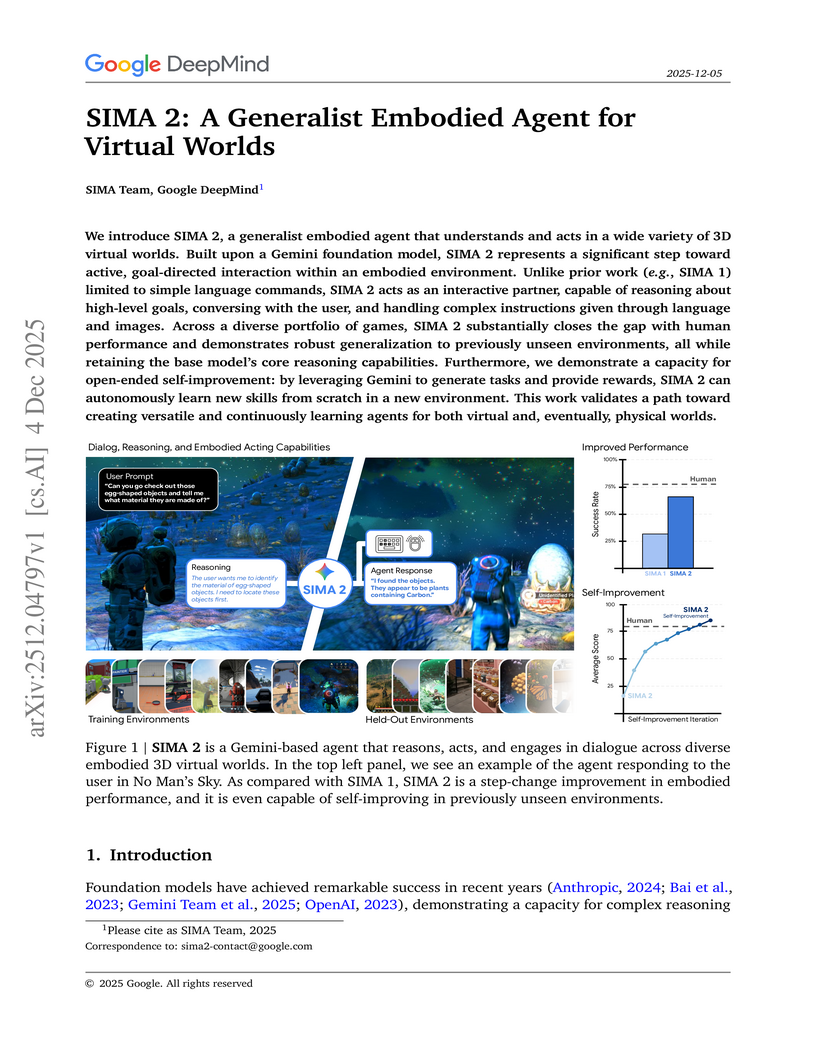
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

09 Dec 2025
Researchers at Physical Intelligence optimized Real-Time Chunking for Vision-Language-Action models by introducing training-time action conditioning, moving computationally intensive prefix conditioning from inference to training. This approach maintained task performance and execution speed, notably reducing latency from 135ms to 108ms and improving robustness at higher inference delays compared to prior methods.

09 Dec 2025

RETAIN, developed at UC Berkeley, introduces a parameter merging strategy for generalist robot policies, interpolating pre-trained and finetuned weights to enable robust adaptation to new tasks. This approach enhances out-of-distribution generalization by approximately 40% on real-world robotic tasks while preserving the policy's existing broad capabilities in low-data scenarios.

09 Dec 2025



While recent large vision-language models (VLMs) have improved generalization in vision-language navigation (VLN), existing methods typically rely on end-to-end pipelines that map vision-language inputs directly to short-horizon discrete actions. Such designs often produce fragmented motions, incur high latency, and struggle with real-world challenges like dynamic obstacle avoidance. We propose DualVLN, the first dual-system VLN foundation model that synergistically integrates high-level reasoning with low-level action execution. System 2, a VLM-based global planner, "grounds slowly" by predicting mid-term waypoint goals via image-grounded reasoning. System 1, a lightweight, multi-modal conditioning Diffusion Transformer policy, "moves fast" by leveraging both explicit pixel goals and latent features from System 2 to generate smooth and accurate trajectories. The dual-system design enables robust real-time control and adaptive local decision-making in complex, dynamic environments. By decoupling training, the VLM retains its generalization, while System 1 achieves interpretable and effective local navigation. DualVLN outperforms prior methods across all VLN benchmarks and real-world experiments demonstrate robust long-horizon planning and real-time adaptability in dynamic environments.

07 Dec 2025
An independent research team secured 1st place in the 2025 BEHAVIOR Challenge, achieving a 26% q-score by enhancing a Vision-Language-Action model (Pi0.5) with innovations like correlated noise for flow matching, "System 2" stage tracking, and practical inference-time heuristics. The approach demonstrated emergent recovery behaviors and addressed challenges in long-horizon, complex manipulation tasks.

09 Dec 2025


World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at this https URL .

08 Dec 2025
A Vision-Language-Action (VLA) model named ViVLA enables robots to acquire novel manipulation skills from single expert video demonstrations at test time. Developed by Beijing Institute of Technology and LimX Dynamics, it achieves over 30% higher success rates on unseen tasks by leveraging a unified latent action space and a scalable data generation pipeline from human videos.

07 Dec 2025
Researchers at the University of Bonn and TU Delft developed a monocular visual SLAM system that accurately estimates camera poses and provides scale-consistent dense 3D reconstruction in dynamic settings. The method integrates a deep learning model for moving object segmentation and depth estimation with a geometric bundle adjustment framework, achieving superior tracking and depth accuracy on challenging datasets.

07 Dec 2025
The Khalasi framework implements an end-to-end reinforcement learning pipeline, enabling autonomous surface vehicles (ASVs) to navigate energy-efficiently in complex, vortical flow fields using only local sensor data. This approach achieves a 43.37% energy saving over baselines and demonstrates robust generalization to unseen synthetic and real-world ocean currents.

05 Dec 2025

Researchers at Princeton University introduce C³, a novel framework for continuous-scale, calibrated uncertainty quantification in controllable video generation models. This method empowers models to assess their confidence in generated frames at a subpatch level, enhancing reliability for applications like robotics by localizing hallucinations and detecting out-of-distribution inputs.

09 Dec 2025
Human video demonstrations provide abundant training data for learning robot policies, but video alone cannot capture the rich contact signals critical for mastering manipulation. We introduce OSMO, an open-source wearable tactile glove designed for human-to-robot skill transfer. The glove features 12 three-axis tactile sensors across the fingertips and palm and is designed to be compatible with state-of-the-art hand-tracking methods for in-the-wild data collection. We demonstrate that a robot policy trained exclusively on human demonstrations collected with OSMO, without any real robot data, is capable of executing a challenging contact-rich manipulation task. By equipping both the human and the robot with the same glove, OSMO minimizes the visual and tactile embodiment gap, enabling the transfer of continuous shear and normal force feedback while avoiding the need for image inpainting or other vision-based force inference. On a real-world wiping task requiring sustained contact pressure, our tactile-aware policy achieves a 72% success rate, outperforming vision-only baselines by eliminating contact-related failure modes. We release complete hardware designs, firmware, and assembly instructions to support community adoption.

09 Dec 2025
MPDiffuser is a model-based diffusion framework that addresses dynamic infeasibility in offline decision-making by employing an alternating sampling scheme between a planner and a forward dynamics model. This approach generates dynamically feasible, task-aligned, and constraint-compliant trajectories, demonstrating improved performance across D4RL and DSRL benchmarks and successful real-world robot deployment.

09 Dec 2025


We introduce Zero-Splat TeleAssist, a zero-shot sensor-fusion pipeline that transforms commodity CCTV streams into a shared, 6-DoF world model for multilateral teleoperation. By integrating vision-language segmentation, monocular depth, weighted-PCA pose extraction, and 3D Gaussian Splatting (3DGS), TeleAssist provides every operator with real-time global positions and orientations of multiple robots without fiducials or depth sensors in an interaction-centric teleoperation setup.

08 Dec 2025

Mimir introduces a hierarchical dual-system for end-to-end autonomous driving that incorporates Laplace distribution-based uncertainty propagation for goal points and a multi-rate guidance mechanism. This framework achieves a 20% improvement in the EPDMS driving score on the Navhard benchmark and a 1.6x speedup for its high-level guidance module.

09 Dec 2025
Model-based planning in robotic domains is fundamentally challenged by the hybrid nature of physical dynamics, where continuous motion is punctuated by discrete events such as contacts and impacts. Conventional latent world models typically employ monolithic neural networks that enforce global continuity, inevitably over-smoothing the distinct dynamic modes (e.g., sticking vs. sliding, flight vs. stance). For a planner, this smoothing results in catastrophic compounding errors during long-horizon lookaheads, rendering the search process unreliable at physical boundaries. To address this, we introduce the Prismatic World Model (PRISM-WM), a structured architecture designed to decompose complex hybrid dynamics into composable primitives. PRISM-WM leverages a context-aware Mixture-of-Experts (MoE) framework where a gating mechanism implicitly identifies the current physical mode, and specialized experts predict the associated transition dynamics. We further introduce a latent orthogonalization objective to ensure expert diversity, effectively preventing mode collapse. By accurately modeling the sharp mode transitions in system dynamics, PRISM-WM significantly reduces rollout drift. Extensive experiments on challenging continuous control benchmarks, including high-dimensional humanoids and diverse multi-task settings, demonstrate that PRISM-WM provides a superior high-fidelity substrate for trajectory optimization algorithms (e.g., TD-MPC), proving its potential as a powerful foundational model for next-generation model-based agents.

09 Dec 2025
We propose Synchronous Dual-Arm Rearrange- ment Planner (SDAR), a task and motion planning (TAMP) framework for tabletop rearrangement, where two robot arms equipped with 2-finger grippers must work together in close proximity to rearrange objects whose start and goal config- urations are strongly entangled. To tackle such challenges, SDAR tightly knit together its dependency-driven task planner (SDAR-T) and synchronous dual-arm motion planner (SDAR- M), to intelligently sift through a large number of possible task and motion plans. Specifically, SDAR-T applies a simple yet effective strategy to decompose the global object dependency graph induced by the rearrangement task, to produce more optimal dual-arm task plans than solutions derived from optimal task plans for a single arm. Leveraging state-of-the-art GPU SIMD-based motion planning tools, SDAR-M employs a layered motion planning strategy to sift through many task plans for the best synchronous dual-arm motion plan while ensuring high levels of success rate. Comprehensive evaluation demonstrates that SDAR delivers a 100% success rate in solving complex, non-monotone, long-horizon tabletop rearrangement tasks with solution quality far exceeding the previous state- of-the-art. Experiments on two UR-5e arms further confirm SDAR directly and reliably transfers to robot hardware.

07 Dec 2025


MIND-V introduces a hierarchical video generation framework for long-horizon robotic manipulation, autonomously synthesizing physically plausible and logically coherent operation videos. It employs a multi-stage architecture with reinforcement learning for physical alignment, providing a scalable method for generating robot training data.

09 Dec 2025
World models have demonstrated impressive performance on robotic learning tasks. Many such tasks inherently demand multimodal reasoning; for example, filling a bottle with water will lead to visual information alone being ambiguous or incomplete, thereby requiring reasoning over the temporal evolution of audio, accounting for its underlying physical properties and pitch patterns. In this paper, we propose a generative latent flow matching model to anticipate future audio observations, enabling the system to reason about long-term consequences when integrated into a robot policy. We demonstrate the superior capabilities of our system through two manipulation tasks that require perceiving in-the-wild audio or music signals, compared to methods without future lookahead. We further emphasize that successful robot action learning for these tasks relies not merely on multi-modal input, but critically on the accurate prediction of future audio states that embody intrinsic rhythmic patterns.
There are no more papers matching your filters at the moment.
