
07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

08 Dec 2025

Researchers from Harvard University and Perplexity conducted a large-scale field study on the real-world adoption and usage of general-purpose AI agents, leveraging hundreds of millions of user interactions with Perplexity's Comet AI-powered browser and its integrated Comet Assistant. The study provides foundational evidence on who uses these agents, their usage intensity, and a detailed breakdown of use cases via a novel hierarchical taxonomy.

08 Dec 2025
Researchers at OpenAI developed a method to train large language models (LLMs) to self-report their non-compliance or shortcomings through a structured "confession" output. This approach uses a disentangled reward system to incentivize honesty, demonstrating that models confess to undesired behaviors in 74.3% of cases and are more likely to be truthful in confessions than in their primary answers, with minimal impact on main task performance.

07 Dec 2025
Large Language Model (LLM) agents are emerging to transform daily life. However, existing LLM agents primarily follow a reactive paradigm, relying on explicit user instructions to initiate services, which increases both physical and cognitive workload. In this paper, we propose ProAgent, the first end-to-end proactive agent system that harnesses massive sensory contexts and LLM reasoning to deliver proactive assistance. ProAgent first employs a proactive-oriented context extraction approach with on-demand tiered perception to continuously sense the environment and derive hierarchical contexts that incorporate both sensory and persona cues. ProAgent then adopts a context-aware proactive reasoner to map these contexts to user needs and tool calls, providing proactive assistance. We implement ProAgent on Augmented Reality (AR) glasses with an edge server and extensively evaluate it on a real-world testbed, a public dataset, and through a user study. Results show that ProAgent achieves up to 33.4% higher proactive prediction accuracy, 16.8% higher tool-calling F1 score, and notable improvements in user satisfaction over state-of-the-art baselines, marking a significant step toward proactive assistants. A video demonstration of ProAgent is available at this https URL.

07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

09 Dec 2025
CLINICALTRIALSHUB unifies clinical trial data from structured registries and unstructured scientific literature, expanding access to structured trial information by 83.8% and providing evidence-grounded, interactive question answering. This platform, developed at The Ohio State University, leverages advanced Large Language Models to streamline information discovery and synthesis for medical professionals and researchers.
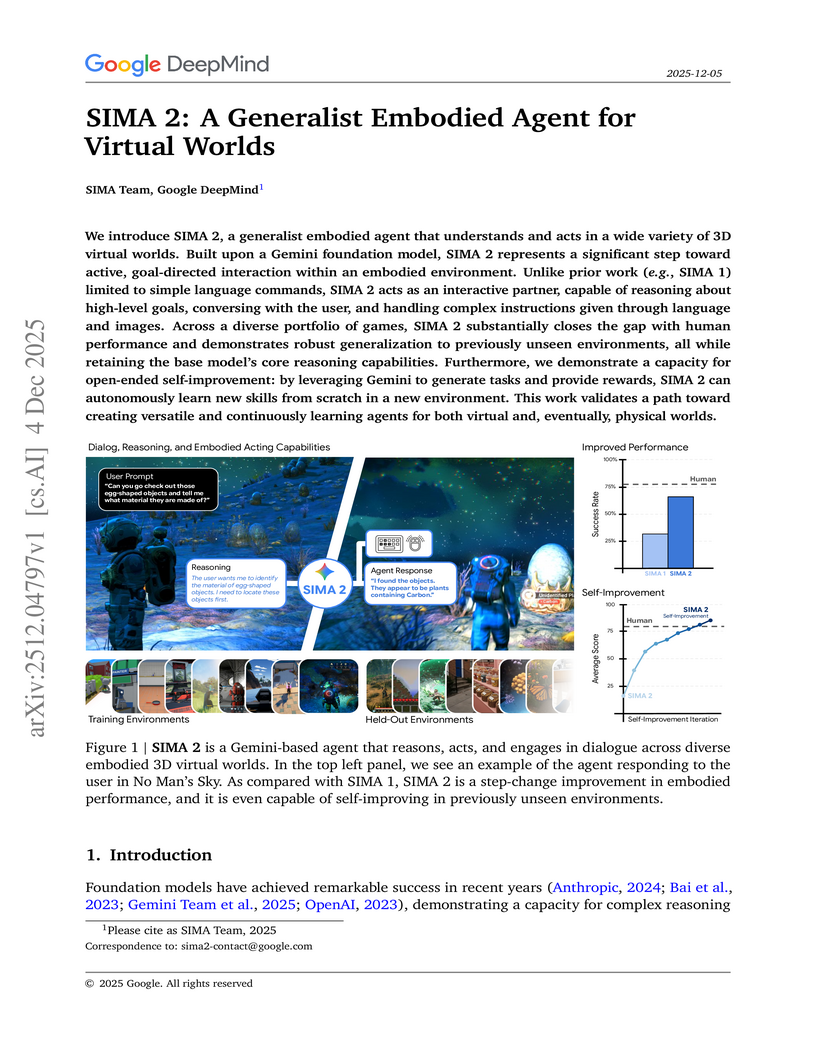
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

10 Dec 2025
Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.

09 Dec 2025


Large language model (LLM) agents often rely on external demonstrations or retrieval-augmented planning, leading to brittleness, poor generalization, and high computational overhead. Inspired by human problem-solving, we propose DuSAR (Dual-Strategy Agent with Reflecting) - a demonstration-free framework that enables a single frozen LLM to perform co-adaptive reasoning via two complementary strategies: a high-level holistic plan and a context-grounded local policy. These strategies interact through a lightweight reflection mechanism, where the agent continuously assesses progress via a Strategy Fitness Score and dynamically revises its global plan when stuck or refines it upon meaningful advancement, mimicking human metacognitive behavior. On ALFWorld and Mind2Web, DuSAR achieves state-of-the-art performance with open-source LLMs (7B-70B), reaching 37.1% success on ALFWorld (Llama3.1-70B) - more than doubling the best prior result (13.0%) - and 4.02% on Mind2Web, also more than doubling the strongest baseline. Remarkably, it reduces per-step token consumption by 3-9X while maintaining strong performance. Ablation studies confirm the necessity of dual-strategy coordination. Moreover, optional integration of expert demonstrations further boosts results, highlighting DuSAR's flexibility and compatibility with external knowledge.

09 Dec 2025
A modular neural image signal processing framework was developed to transform raw sensor data into high-quality sRGB images, addressing the limitations of "black-box" neural ISPs by offering fine-grained control and enhanced interpretability. This system achieves state-of-the-art performance, supports diverse photographic styles, and generalizes robustly to various cameras, demonstrated by quantitative metrics and user preferences.

09 Dec 2025

The MVP framework introduces a training-free, two-stage approach that significantly improves the reliability and accuracy of GUI grounding models by addressing coordinate prediction instability. It achieves this by aggregating predictions from multiple attention-guided, enlarged views, leading to new state-of-the-art performance on challenging benchmarks like ScreenSpot-Pro and UI-Vision.
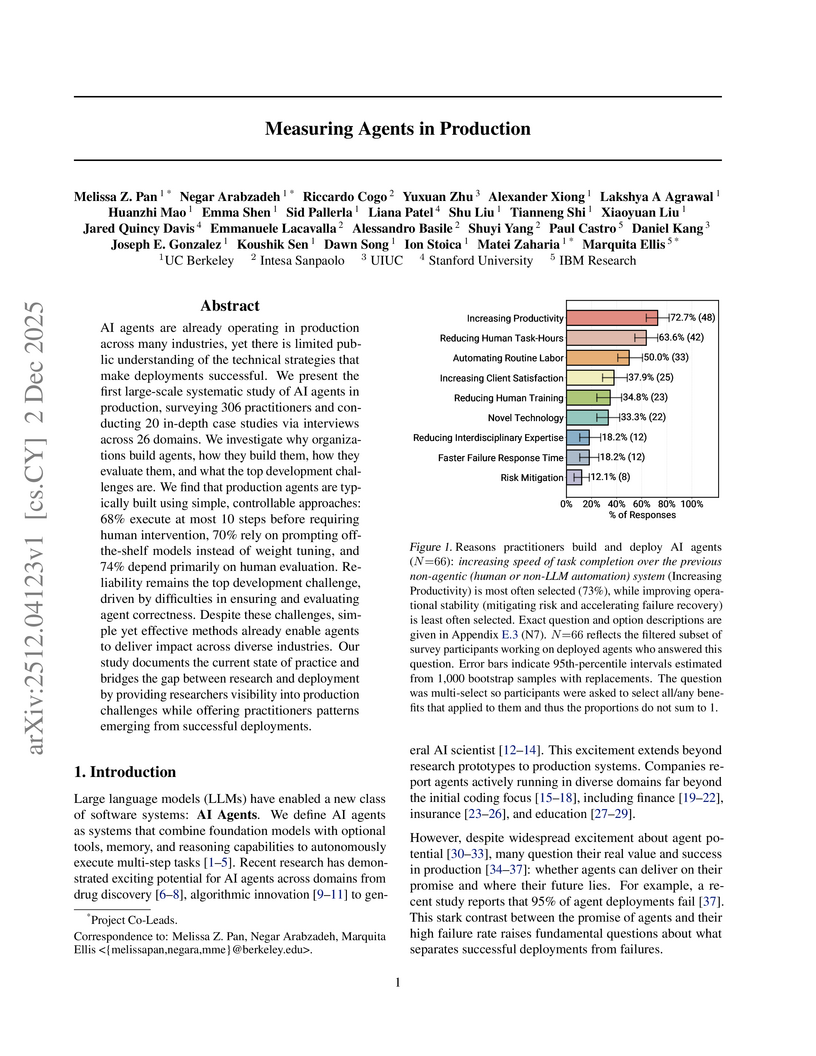
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

10 Dec 2025

Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.

09 Dec 2025
Recent advancements in Gaussian Splatting have enabled increasingly accurate reconstruction of photorealistic head avatars, opening the door to numerous applications in visual effects, videoconferencing, and virtual reality. This, however, comes with the lack of intuitive editability offered by traditional triangle mesh-based methods. In contrast, we propose a method that combines the accuracy and fidelity of 2D Gaussian Splatting with the intuitiveness of UV texture mapping. By embedding each canonical Gaussian primitive's local frame into a patch in the UV space of a template mesh in a computationally efficient manner, we reconstruct continuous editable material head textures from a single monocular video on a conventional UV domain. Furthermore, we leverage an efficient physically based reflectance model to enable relighting and editing of these intrinsic material maps. Through extensive comparisons with state-of-the-art methods, we demonstrate the accuracy of our reconstructions, the quality of our relighting results, and the ability to provide intuitive controls for modifying an avatar's appearance and geometry via texture mapping without additional optimization.

04 Dec 2025


Researchers from UC Berkeley and ByteDance Seed developed Natural Language Actor-Critic (NLAC), an off-policy reinforcement learning algorithm that trains LLM agents using a generative natural language critic to provide rich, explanatory feedback. NLAC demonstrated superior performance and enhanced sample efficiency on multi-turn dialogue and tool-use tasks compared to existing RL methods and strong prompting baselines.

08 Dec 2025

Image fusion aims to blend complementary information from multiple sensing modalities, yet existing approaches remain limited in robustness, adaptability, and controllability. Most current fusion networks are tailored to specific tasks and lack the ability to flexibly incorporate user intent, especially in complex scenarios involving low-light degradation, color shifts, or exposure imbalance. Moreover, the absence of ground-truth fused images and the small scale of existing datasets make it difficult to train an end-to-end model that simultaneously understands high-level semantics and performs fine-grained multimodal alignment. We therefore present DiTFuse, instruction-driven Diffusion-Transformer (DiT) framework that performs end-to-end, semantics-aware fusion within a single model. By jointly encoding two images and natural-language instructions in a shared latent space, DiTFuse enables hierarchical and fine-grained control over fusion dynamics, overcoming the limitations of pre-fusion and post-fusion pipelines that struggle to inject high-level semantics. The training phase employs a multi-degradation masked-image modeling strategy, so the network jointly learns cross-modal alignment, modality-invariant restoration, and task-aware feature selection without relying on ground truth images. A curated, multi-granularity instruction dataset further equips the model with interactive fusion capabilities. DiTFuse unifies infrared-visible, multi-focus, and multi-exposure fusion-as well as text-controlled refinement and downstream tasks-within a single architecture. Experiments on public IVIF, MFF, and MEF benchmarks confirm superior quantitative and qualitative performance, sharper textures, and better semantic retention. The model also supports multi-level user control and zero-shot generalization to other multi-image fusion scenarios, including instruction-conditioned segmentation.

07 Dec 2025
Preference alignment has enabled large language models (LLMs) to better reflect human expectations, but current methods mostly optimize for population-level preferences, overlooking individual users. Personalization is essential, yet early approaches-such as prompt customization or fine-tuning-struggle to reason over implicit preferences, limiting real-world effectiveness. Recent "think-then-generate" methods address this by reasoning before response generation. However, they face challenges in long-form generation: their static one-shot reasoning must capture all relevant information for the full response generation, making learning difficult and limiting adaptability to evolving content. To address this issue, we propose FlyThinker, an efficient "think-while-generating" framework for personalized long-form generation. FlyThinker employs a separate reasoning model that generates latent token-level reasoning in parallel, which is fused into the generation model to dynamically guide response generation. This design enables reasoning and generation to run concurrently, ensuring inference efficiency. In addition, the reasoning model is designed to depend only on previous responses rather than its own prior outputs, which preserves training parallelism across different positions-allowing all reasoning tokens for training data to be produced in a single forward pass like standard LLM training, ensuring training efficiency. Extensive experiments on real-world benchmarks demonstrate that FlyThinker achieves better personalized generation while keeping training and inference efficiency.

08 Dec 2025


Lang3D-XL introduces a method for embedding language features into 3D Gaussian Splatting models of large-scale "in-the-wild" scenes. It enables interactive, text-based semantic understanding, achieving comparable semantic segmentation performance to HaLo-NeRF while accelerating inference speed by orders of magnitude (under 0.1 seconds per query vs. two hours) and outperforming other feature-based methods with an mAP of 0.59 on the HolyScenes dataset.

10 Dec 2025
Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.

09 Dec 2025
Understanding human personality is crucial for web applications such as personalized recommendation and mental health assessment. Existing studies on personality detection predominantly adopt a "posts -> user vector -> labels" modeling paradigm, which encodes social media posts into user representations for predicting personality labels (e.g., MBTI labels). While recent advances in large language models (LLMs) have improved text encoding capacities, these approaches remain constrained by limited supervision signals due to label scarcity, and under-specified semantic mappings between user language and abstract psychological constructs. We address these challenges by proposing ROME, a novel framework that explicitly injects psychological knowledge into personality detection. Inspired by standardized self-assessment tests, ROME leverages LLMs' role-play capability to simulate user responses to validated psychometric questionnaires. These generated question-level answers transform free-form user posts into interpretable, questionnaire-grounded evidence linking linguistic cues to personality labels, thereby providing rich intermediate supervision to mitigate label scarcity while offering a semantic reasoning chain that guides and simplifies the text-to-personality mapping learning. A question-conditioned Mixture-of-Experts module then jointly routes over post and question representations, learning to answer questionnaire items under explicit supervision. The predicted answers are summarized into an interpretable answer vector and fused with the user representation for final prediction within a multi-task learning framework, where question answering serves as a powerful auxiliary task for personality detection. Extensive experiments on two real-world datasets demonstrate that ROME consistently outperforms state-of-the-art baselines, achieving improvements (15.41% on Kaggle dataset).
There are no more papers matching your filters at the moment.
