
07 Dec 2025
Researchers at the University of Bonn and TU Delft developed a monocular visual SLAM system that accurately estimates camera poses and provides scale-consistent dense 3D reconstruction in dynamic settings. The method integrates a deep learning model for moving object segmentation and depth estimation with a geometric bundle adjustment framework, achieving superior tracking and depth accuracy on challenging datasets.

10 Dec 2025

Recent advances in diffusion models have greatly improved image generation and editing, yet generating or reconstructing layered PSD files with transparent alpha channels remains highly challenging. We propose OmniPSD, a unified diffusion framework built upon the Flux ecosystem that enables both text-to-PSD generation and image-to-PSD decomposition through in-context learning. For text-to-PSD generation, OmniPSD arranges multiple target layers spatially into a single canvas and learns their compositional relationships through spatial attention, producing semantically coherent and hierarchically structured layers. For image-to-PSD decomposition, it performs iterative in-context editing, progressively extracting and erasing textual and foreground components to reconstruct editable PSD layers from a single flattened image. An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning. Extensive experiments on our new RGBA-layered dataset demonstrate that OmniPSD achieves high-fidelity generation, structural consistency, and transparency awareness, offering a new paradigm for layered design generation and decomposition with diffusion transformers.

08 Dec 2025


Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.

09 Dec 2025
Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at this https URL.

10 Dec 2025

Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.

08 Dec 2025

Image fusion aims to blend complementary information from multiple sensing modalities, yet existing approaches remain limited in robustness, adaptability, and controllability. Most current fusion networks are tailored to specific tasks and lack the ability to flexibly incorporate user intent, especially in complex scenarios involving low-light degradation, color shifts, or exposure imbalance. Moreover, the absence of ground-truth fused images and the small scale of existing datasets make it difficult to train an end-to-end model that simultaneously understands high-level semantics and performs fine-grained multimodal alignment. We therefore present DiTFuse, instruction-driven Diffusion-Transformer (DiT) framework that performs end-to-end, semantics-aware fusion within a single model. By jointly encoding two images and natural-language instructions in a shared latent space, DiTFuse enables hierarchical and fine-grained control over fusion dynamics, overcoming the limitations of pre-fusion and post-fusion pipelines that struggle to inject high-level semantics. The training phase employs a multi-degradation masked-image modeling strategy, so the network jointly learns cross-modal alignment, modality-invariant restoration, and task-aware feature selection without relying on ground truth images. A curated, multi-granularity instruction dataset further equips the model with interactive fusion capabilities. DiTFuse unifies infrared-visible, multi-focus, and multi-exposure fusion-as well as text-controlled refinement and downstream tasks-within a single architecture. Experiments on public IVIF, MFF, and MEF benchmarks confirm superior quantitative and qualitative performance, sharper textures, and better semantic retention. The model also supports multi-level user control and zero-shot generalization to other multi-image fusion scenarios, including instruction-conditioned segmentation.
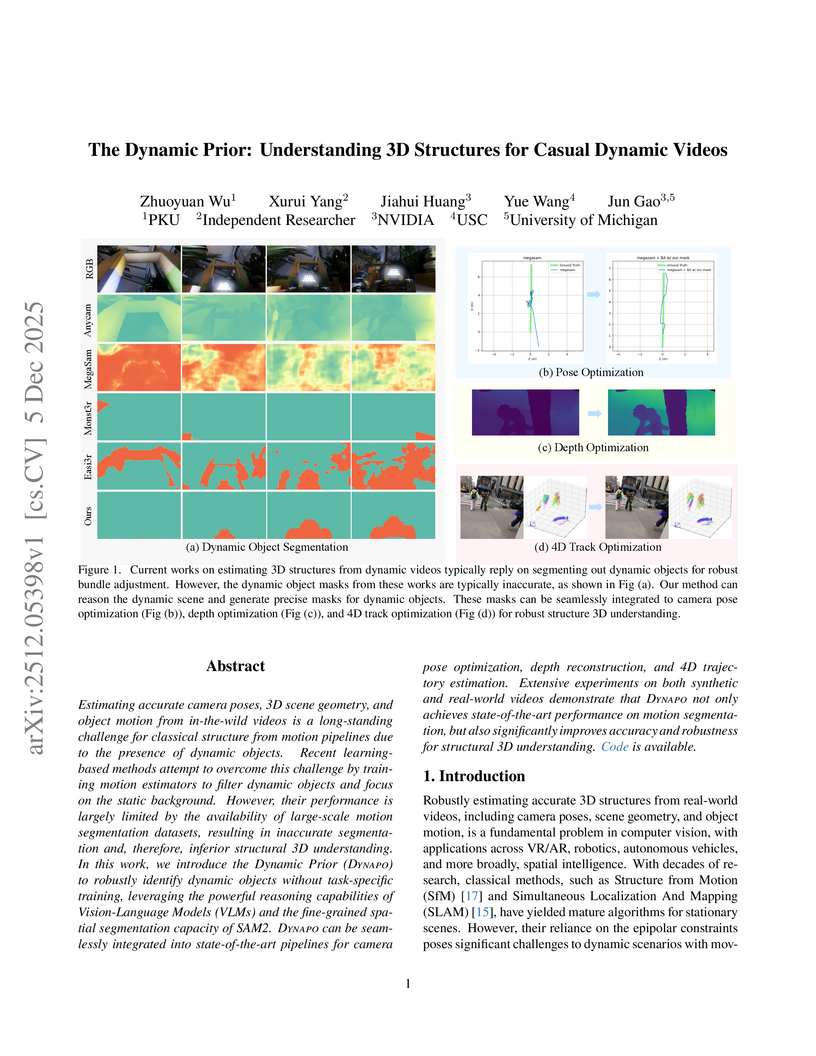
05 Dec 2025




Researchers at Peking University, NVIDIA, USC, and the University of Michigan developed Dynapo, a training-free framework that leverages large vision-language models and advanced segmentation models to robustly identify dynamic objects in casual videos. This approach significantly enhances the accuracy of camera pose estimation, depth reconstruction, and 4D trajectory optimization in dynamic scenes.

07 Dec 2025
Video Instance Segmentation (VIS) faces significant annotation challenges due to its dual requirements of pixel-level masks and temporal consistency labels. While recent unsupervised methods like VideoCutLER eliminate optical flow dependencies through synthetic data, they remain constrained by the synthetic-to-real domain gap. We present AutoQ-VIS, a novel unsupervised framework that bridges this gap through quality-guided self-training. Our approach establishes a closed-loop system between pseudo-label generation and automatic quality assessment, enabling progressive adaptation from synthetic to real videos. Experiments demonstrate state-of-the-art performance with 52.6 on YouTubeVIS-2019 set, surpassing the previous state-of-the-art VideoCutLER by 4.4%, while requiring no human annotations. This demonstrates the viability of quality-aware self-training for unsupervised VIS. We will release the code at this https URL.

08 Dec 2025
AutoSeg3D introduces a tracking-centric framework for online, real-time 3D instance segmentation, leveraging Long-Term Memory, Short-Term Memory, and Spatial Consistency Learning. This method achieves 45.5 AP on ScanNet200, a 2.8 AP improvement over the previous state-of-the-art ESAM, while operating at real-time speeds.

09 Dec 2025
Accurate segmentation of cancerous lesions from 3D computed tomography (CT) scans is essential for automated treatment planning and response assessment. However, even state-of-the-art models combining self-supervised learning (SSL) pretrained transformers with convolutional decoders are susceptible to out-of-distribution (OOD) inputs, generating confidently incorrect tumor segmentations, posing risks for safe clinical deployment. Existing logit-based methods suffer from task-specific model biases, while architectural enhancements to explicitly detect OOD increase parameters and computational costs. Hence, we introduce a plug-and-play and lightweight post-hoc random forests-based OOD detection framework called RF-Deep that leverages deep features with limited outlier exposure. RF-Deep enhances generalization to imaging variations by repurposing the hierarchical features from the pretrained-then-finetuned backbone encoder, providing task-relevant OOD detection by extracting the features from multiple regions of interest anchored to the predicted tumor segmentations. Hence, it scales to images of varying fields-of-view. We compared RF-Deep against existing OOD detection methods using 1,916 CT scans across near-OOD (pulmonary embolism, negative COVID-19) and far-OOD (kidney cancer, healthy pancreas) datasets. RF-Deep achieved AUROC > 93.50 for the challenging near-OOD datasets and near-perfect detection (AUROC > 99.00) for the far-OOD datasets, substantially outperforming logit-based and radiomics approaches. RF-Deep maintained similar performance consistency across networks of different depths and pretraining strategies, demonstrating its effectiveness as a lightweight, architecture-agnostic approach to enhance the reliability of tumor segmentation from CT volumes.

09 Dec 2025
Coronary angiography is the main tool for assessing coronary artery disease, but visual grading of stenosis is variable and only moderately related to ischaemia. Wire based fractional flow reserve (FFR) improves lesion selection but is not used systematically. Angiography derived indices such as quantitative flow ratio (QFR) offer wire free physiology, yet many tools are workflow intensive and separate from automated anatomy analysis and virtual PCI planning. We developed AngioAI-QFR, an end to end angiography only pipeline combining deep learning stenosis detection, lumen segmentation, centreline and diameter extraction, per millimetre Relative Flow Capacity profiling, and virtual stenting with automatic recomputation of angiography derived QFR. The system was evaluated in 100 consecutive vessels with invasive FFR as reference. Primary endpoints were agreement with FFR (correlation, mean absolute error) and diagnostic performance for FFR <= 0.80. On held out frames, stenosis detection achieved precision 0.97 and lumen segmentation Dice 0.78. Across 100 vessels, AngioAI-QFR correlated strongly with FFR (r = 0.89, MAE 0.045). The AUC for detecting FFR <= 0.80 was 0.93, with sensitivity 0.88 and specificity 0.86. The pipeline completed fully automatically in 93 percent of vessels, with median time to result 41 s. RFC profiling distinguished focal from diffuse capacity loss, and virtual stenting predicted larger QFR gain in focal than in diffuse disease. AngioAI-QFR provides a practical, near real time pipeline that unifies computer vision, functional profiling, and virtual PCI with automated angiography derived physiology.

10 Dec 2025
We present NordFKB, a fine-grained benchmark dataset for geospatial AI in Norway, derived from the authoritative, highly accurate, national Felles KartdataBase (FKB). The dataset contains high-resolution orthophotos paired with detailed annotations for 36 semantic classes, including both per-class binary segmentation masks in GeoTIFF format and COCO-style bounding box annotations. Data is collected from seven geographically diverse areas, ensuring variation in climate, topography, and urbanization. Only tiles containing at least one annotated object are included, and training/validation splits are created through random sampling across areas to ensure representative class and context distributions. Human expert review and quality control ensures high annotation accuracy. Alongside the dataset, we release a benchmarking repository with standardized evaluation protocols and tools for semantic segmentation and object detection, enabling reproducible and comparable research. NordFKB provides a robust foundation for advancing AI methods in mapping, land administration, and spatial planning, and paves the way for future expansions in coverage, temporal scope, and data modalities.

10 Dec 2025
Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.

08 Dec 2025
Text as signs, labels, or instructions is a critical element of real-world scenes as they can convey important contextual information. 3D representations such as 3D Gaussian Splatting (3DGS) struggle to preserve fine-grained text details, while achieving high visual fidelity. Small errors in textual element reconstruction can lead to significant semantic loss. We propose STRinGS, a text-aware, selective refinement framework to address this issue for 3DGS reconstruction. Our method treats text and non-text regions separately, refining text regions first and merging them with non-text regions later for full-scene optimization. STRinGS produces sharp, readable text even in challenging configurations. We introduce a text readability measure OCR Character Error Rate (CER) to evaluate the efficacy on text regions. STRinGS results in a 63.6% relative improvement over 3DGS at just 7K iterations. We also introduce a curated dataset STRinGS-360 with diverse text scenarios to evaluate text readability in 3D reconstruction. Our method and dataset together push the boundaries of 3D scene understanding in text-rich environments, paving the way for more robust text-aware reconstruction methods.

08 Dec 2025
Neural networks are frequently used in medical diagnosis. However, due to their black-box nature, model explainers are used to help clinicians understand better and trust model outputs. This paper introduces an explainer method for classifying Retinopathy of Prematurity (ROP) from fundus images. Previous methods fail to generate explanations that preserve input image structures such as smoothness and sparsity. We introduce Sparse and Smooth Explainer (SSplain), a method that generates pixel-wise explanations while preserving image structures by enforcing smoothness and sparsity. This results in realistic explanations to enhance the understanding of the given black-box model. To achieve this goal, we define an optimization problem with combinatorial constraints and solve it using the Alternating Direction Method of Multipliers (ADMM). Experimental results show that SSplain outperforms commonly used explainers in terms of both post-hoc accuracy and smoothness analyses. Additionally, SSplain identifies features that are consistent with domain-understandable features that clinicians consider as discriminative factors for ROP. We also show SSplain's generalization by applying it to additional publicly available datasets. Code is available at this https URL.

08 Dec 2025
Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.

10 Dec 2025
Occlusions in robotic bin picking compromise accurate and reliable grasp planning. We present ViTA-Seg, a class-agnostic Vision Transformer framework for real-time amodal segmentation that leverages global attention to recover complete object masks, including hidden regions. We proposte two architectures: a) Single-Head for amodal mask prediction; b) Dual-Head for amodal and occluded mask prediction. We also introduce ViTA-SimData, a photo-realistic synthetic dataset tailored to industrial bin-picking scenario. Extensive experiments on two amodal benchmarks, COOCA and KINS, demonstrate that ViTA-Seg Dual Head achieves strong amodal and occlusion segmentation accuracy with computational efficiency, enabling robust, real-time robotic manipulation.

01 Dec 2025


Insta360 Research and its collaborators developed AirSim360, a panoramic simulation platform for drones, which generates high-fidelity 360-degree aerial data with rich, render-aligned annotations. The platform's synthetic data notably improved monocular pedestrian distance estimation by reducing average angular error from 21.21° to 17.02° and enhanced performance in panoramic depth and segmentation tasks.

05 Dec 2025

COOPER, developed by researchers from Chinese Academy of Sciences and Baidu Inc., introduces a unified multimodal large language model that intrinsically generates auxiliary visual cues, such as depth and segmentation maps, and adaptively integrates them with textual reasoning. The model achieves an average 6.91% improvement in spatial reasoning and a 4.47% gain on general multimodal benchmarks, surpassing several larger and proprietary models on specific spatial tasks.

04 Dec 2025

Researchers from the University of Hong Kong, Beijing Institute of Technology, and the University of Delaware developed UniTS, a unified time series generative model based on flow matching, capable of performing four distinct remote sensing tasks: reconstruction, cloud removal, semantic change detection, and forecasting. UniTS demonstrated superior performance across these tasks, achieving over 1.88 dB PSNR improvement for cloud removal on a new challenging dataset with 84.02% average cloud coverage, and the best mIoU scores for semantic change detection.
There are no more papers matching your filters at the moment.
