
08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

09 Dec 2025
Terrain Diffusion introduces a diffusion-based framework for generating infinite, real-time procedural terrain, delivering highly realistic, boundless virtual worlds with seed-consistency and constant-time random access. The system achieves competitive FID scores and real-time generation latency on consumer hardware, demonstrating its practical applicability.
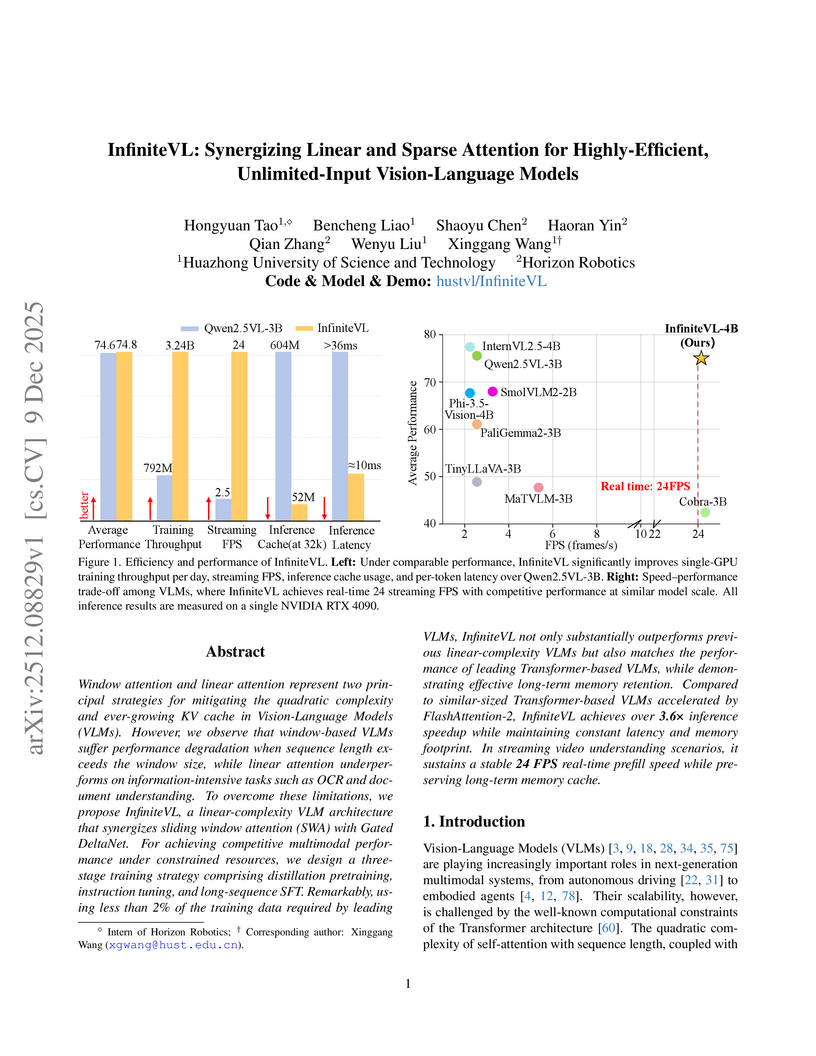
09 Dec 2025

InfiniteVL, a collaboration between Huazhong University of Science and Technology and Horizon Robotics, introduces a hybrid Vision-Language Model that synergizes linear and sparse attention to enable unlimited multimodal input processing with constant latency and memory footprint. The model achieves performance competitive with Transformer-based VLMs on diverse benchmarks, including information-intensive tasks, while demonstrating significant inference speedups and robust real-time streaming capabilities.

09 Dec 2025



Researchers from Google DeepMind, University College London, and the University of Oxford developed D4RT, a unified feedforward model for reconstructing dynamic 4D scenes, encompassing depth, spatio-temporal correspondence, and camera parameters, from video using a single, flexible querying interface. The model achieved state-of-the-art accuracy across various 4D reconstruction and tracking benchmarks, with 3D tracking throughput 18-300 times faster and pose estimation over 100 times faster than prior methods.

07 Dec 2025




MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

09 Dec 2025
Visionary introduces a WebGPU-powered platform for 3D Gaussian Splatting (3DGS) that enables real-time, client-side rendering and inference for dynamic and generative 3DGS models. The platform demonstrates up to 135x speedup compared to WebGL-based viewers, while maintaining or improving visual quality and ensuring robust depth-aware composition.
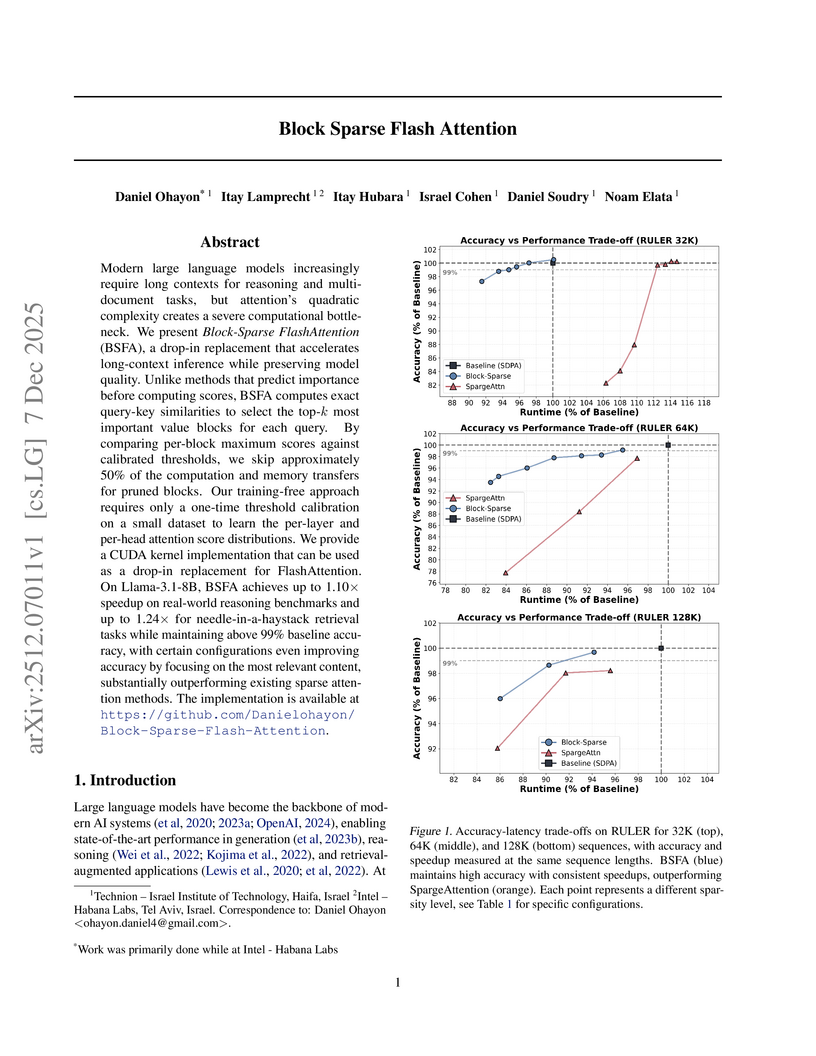
07 Dec 2025
Block Sparse Flash Attention (BSFA) accelerates large language model inference for long input sequences by intelligently skipping computations for negligible value blocks based on exact attention scores. This training-free method maintains high accuracy while achieving speedups up to 1.24x on retrieval tasks and 1.10x for general reasoning.

09 Dec 2025
SAM-Body4D introduces a training-free framework for 4D human body mesh recovery from videos, synergistically combining promptable video object segmentation and image-based human mesh recovery models with an occlusion-aware mask refinement module. The system produces temporally consistent and robust mesh trajectories, effectively handling occlusions and maintaining identity across frames.

07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.

07 Dec 2025
Researchers from Peking University and Huawei Technologies developed a principled framework for adapting pre-trained autoregressive (AR) models into Block-Diffusion Language Models (DLMs). The adapted 7B-class model, NBDIFF-7B, achieved state-of-the-art performance among diffusion LLMs, with a macro average of 64.3 for its base version and 78.8 for its instruct version across diverse benchmarks.

07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

09 Dec 2025


Researchers from Peking University, Nanchang University, and Tsinghua University developed the first on-the-fly 3D reconstruction framework for multi-camera rigs, enabling calibration-free, large-scale, and high-fidelity scene reconstruction. The system generates drift-free trajectories and photorealistic novel views, reconstructing 100 meters of road or 100,000 m² of aerial scenes in two minutes.

10 Dec 2025

Recent research has developed several LLM architectures suitable for inference on end-user devices, such as the Mixture of Lookup Experts (MoLE)~\parencite{jie_mixture_2025}. A key feature of MoLE is that each token id is associated with a dedicated group of experts. For a given input, only the experts corresponding to the input token id will be activated. Since the communication overhead of loading this small number of activated experts into RAM during inference is negligible, expert parameters can be offloaded to storage, making MoLE suitable for resource-constrained devices. However, MoLE's context-independent expert selection mechanism, based solely on input ids, may limit model performance. To address this, we propose the \textbf{M}ixture \textbf{o}f \textbf{L}ookup \textbf{K}ey-\textbf{V}alue Experts (\textbf{MoLKV}) model. In MoLKV, each expert is structured as a key-value pair. For a given input, the input-derived query interacts with the cached key-value experts from the current sequence, generating a context-aware expert output. This context-aware mechanism alleviates the limitation of MoLE, and experimental results demonstrate that MoLKV achieves significantly lower validation loss in small-scale evaluations.

10 Dec 2025


Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at this https URL.

09 Dec 2025

Fast-ARDiff introduces an entropy-informed acceleration framework for continuous-space AR-Diffusion hybrid generative models. This framework achieves up to a 4.88x speedup in inference latency with minimal quality degradation by addressing challenges like entropy mismatch in visual speculative decoding and instability in diffusion distillation.

09 Dec 2025

NoisyCLIP offers a method for assessing language-to-latent alignment during the reverse diffusion process in conditional diffusion models, facilitating early detection of misalignments. This approach reduces computational costs in image generation by up to 50% while maintaining high semantic fidelity.

08 Dec 2025
Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: this https URL
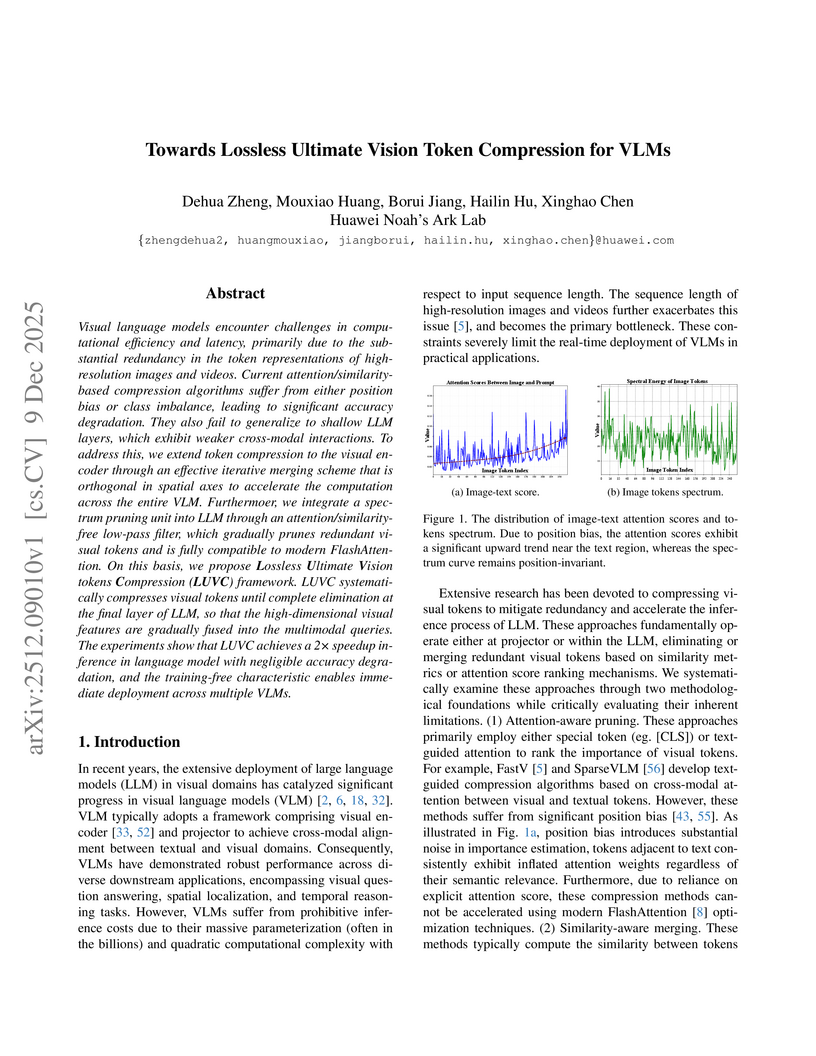
09 Dec 2025
Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

08 Dec 2025


Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.
There are no more papers matching your filters at the moment.
