06 Dec 2025
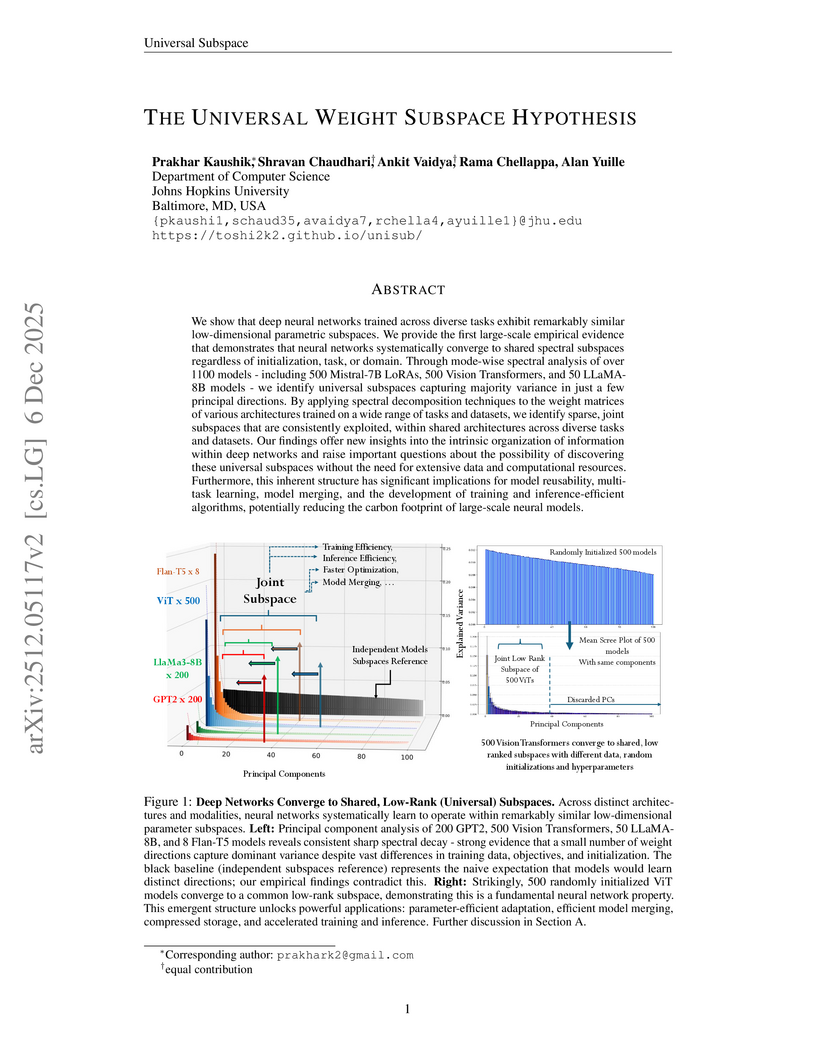
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

08 Dec 2025

Apple researchers introduced FAE (Feature Auto-Encoder), a minimalist framework using a single attention layer and a double-decoder architecture to adapt high-dimensional self-supervised visual features into compact, generation-friendly latent spaces. FAE achieves competitive FID scores on ImageNet (1.29) and MS-COCO (6.90) for image generation while preserving semantic understanding capabilities of the original pre-trained encoders.

09 Dec 2025



Researchers from Google DeepMind, University College London, and the University of Oxford developed D4RT, a unified feedforward model for reconstructing dynamic 4D scenes, encompassing depth, spatio-temporal correspondence, and camera parameters, from video using a single, flexible querying interface. The model achieved state-of-the-art accuracy across various 4D reconstruction and tracking benchmarks, with 3D tracking throughput 18-300 times faster and pose estimation over 100 times faster than prior methods.

07 Dec 2025




MeshSplatting generates connected, opaque, and colored triangle meshes from images using differentiable rendering, enabling direct integration of neurally reconstructed scenes into traditional 3D graphics pipelines. The method achieves a +0.69 dB PSNR improvement over MiLo on the Mip-NeRF360 dataset and trains 2x faster while requiring 2.5x less memory.

07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.
08 Dec 2025

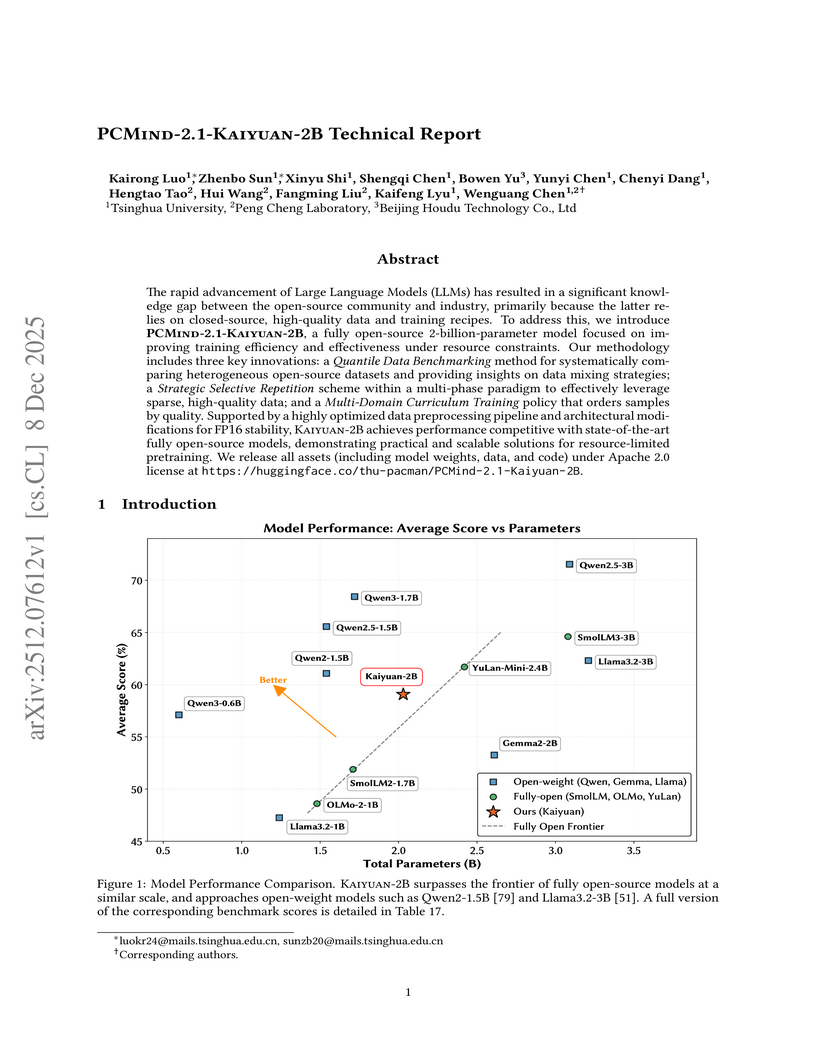
Researchers from Tsinghua University and Peng Cheng Laboratory developed PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter language model. It achieves competitive performance in Chinese language understanding, mathematical reasoning, and code generation by employing a multi-phase curriculum training with strategic data repetition and architectural modifications for FP16 stability, attaining an overall average score of 59.07% across evaluated benchmarks and outperforming several existing open-source models in its class.

10 Dec 2025

Recent research has developed several LLM architectures suitable for inference on end-user devices, such as the Mixture of Lookup Experts (MoLE)~\parencite{jie_mixture_2025}. A key feature of MoLE is that each token id is associated with a dedicated group of experts. For a given input, only the experts corresponding to the input token id will be activated. Since the communication overhead of loading this small number of activated experts into RAM during inference is negligible, expert parameters can be offloaded to storage, making MoLE suitable for resource-constrained devices. However, MoLE's context-independent expert selection mechanism, based solely on input ids, may limit model performance. To address this, we propose the \textbf{M}ixture \textbf{o}f \textbf{L}ookup \textbf{K}ey-\textbf{V}alue Experts (\textbf{MoLKV}) model. In MoLKV, each expert is structured as a key-value pair. For a given input, the input-derived query interacts with the cached key-value experts from the current sequence, generating a context-aware expert output. This context-aware mechanism alleviates the limitation of MoLE, and experimental results demonstrate that MoLKV achieves significantly lower validation loss in small-scale evaluations.

09 Dec 2025
A Conditional Neural Cellular Automata (c-NCA) framework is introduced, enabling a single set of local rules to grow diverse structural digits from a single pixel, guided by a broadcasted class vector. The lightweight model achieves 96.30% recognition accuracy on generated digits by an external classifier and demonstrates robust emergent self-repair from significant damage without specific training.

08 Dec 2025
MOCA (Mixture-of-Components Attention) introduces a novel attention mechanism within a compositional Diffusion Transformer framework, enabling scalable and high-fidelity generation of 3D objects and scenes from images. This method effectively addresses the quadratic computational cost of previous approaches by intelligently routing attention based on component importance, successfully generating assets with up to 32 components per sample.
09 Dec 2025
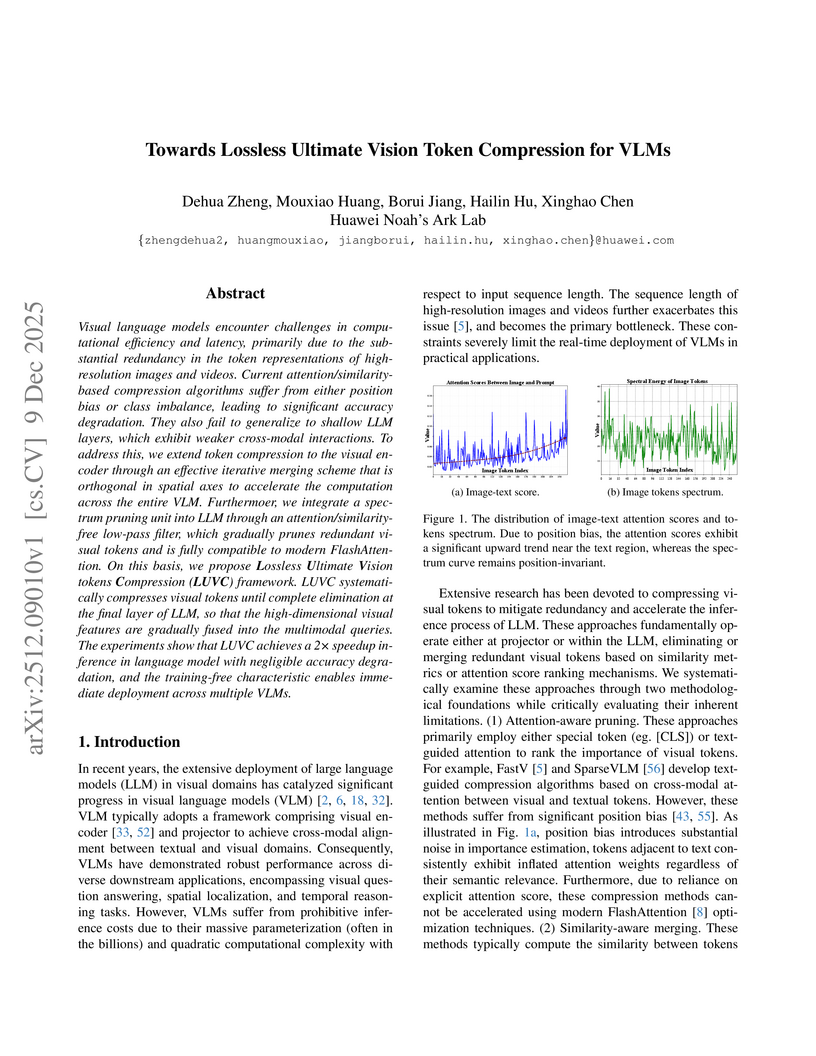
Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

08 Dec 2025
A two-stage self-supervised framework integrates the Joint-Embedding Predictive Architecture (JEPA) with Density Adaptive Attention Mechanisms (DAAM) to learn robust speech representations. This approach generates efficient, reversible discrete speech tokens at an ultra-low rate of 47.5 tokens/sec, designed for seamless integration with large language models.

09 Dec 2025
A modular neural image signal processing framework was developed to transform raw sensor data into high-quality sRGB images, addressing the limitations of "black-box" neural ISPs by offering fine-grained control and enhanced interpretability. This system achieves state-of-the-art performance, supports diverse photographic styles, and generalizes robustly to various cameras, demonstrated by quantitative metrics and user preferences.

09 Dec 2025
Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at this https URL.

10 Dec 2025

Researchers at Zhejiang University developed Video-QTR, a query-driven temporal reasoning framework for video understanding that dynamically allocates perceptual resources based on query intent. This system achieved state-of-the-art accuracy on long-video benchmarks while reducing input frame consumption by up to 73%.

09 Dec 2025


HybridToken-VLM (HTC-VLM) presents a hybrid token compression architecture for Vision-Language Models, disentangling high-level semantics and low-level details to achieve extreme compression. The method compresses 580 visual tokens into a single hybrid token, retaining 87.2% of the original model's performance on a suite of seven visual understanding benchmarks and achieving a 7.9x inference speedup.

08 Dec 2025

Researchers developed a metric to quantify visual token information in Vision Large Language Models, uncovering that information becomes uniform and diminishes in deeper layers. This insight led to a hybrid token pruning strategy that reduces inference latency by up to 73% and FLOPs by 74.4% in LLaVA-1.5-7B while maintaining performance.

07 Dec 2025


A training-free framework, DyToK, dynamically compresses visual tokens for Video Large Language Models by leveraging an LLM-guided keyframe prior to adaptively allocate per-frame token budgets. This approach significantly boosts inference speed and reduces memory while enhancing video understanding performance, especially under high compression.

05 Dec 2025
CompressARC, developed by researchers at Carnegie Mellon University, addresses the ARC-AGI benchmark by achieving 20% accuracy on evaluation puzzles without any pretraining, learning entirely at inference time from the target puzzle. It leverages a custom equivariant neural network and the Minimum Description Length principle to discover abstract reasoning patterns with extreme data efficiency.

09 Dec 2025
Huawei Inc. developed EMMA (Efficient Multimodal Understanding, Generation, and Editing), a unified architecture that reduces visual tokens by 80% compared to previous models by employing a 32x compression autoencoder and channel-wise concatenation. EMMA-4B surpasses leading unified multimodal models and achieves competitive performance against specialized expert models across understanding, generation, and editing benchmarks.
There are no more papers matching your filters at the moment.
