06 Dec 2025
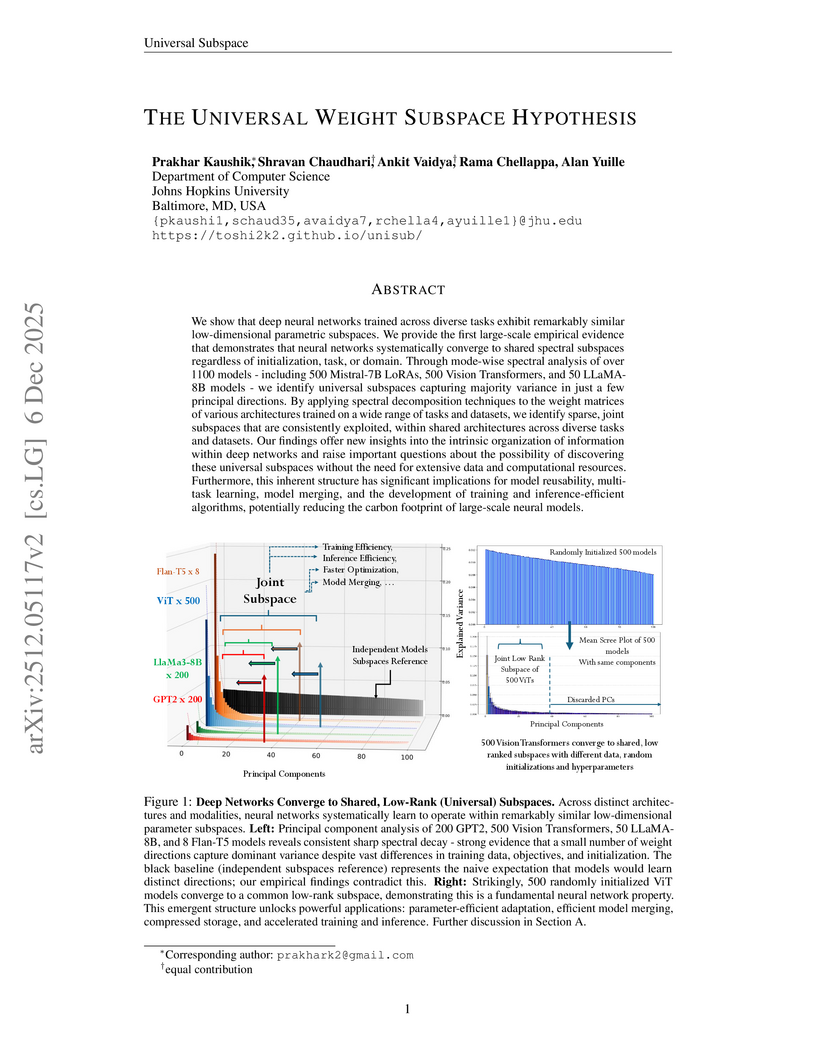
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

09 Dec 2025
Terrain Diffusion introduces a diffusion-based framework for generating infinite, real-time procedural terrain, delivering highly realistic, boundless virtual worlds with seed-consistency and constant-time random access. The system achieves competitive FID scores and real-time generation latency on consumer hardware, demonstrating its practical applicability.

09 Dec 2025


Researchers from Peking University, Nanchang University, and Tsinghua University developed the first on-the-fly 3D reconstruction framework for multi-camera rigs, enabling calibration-free, large-scale, and high-fidelity scene reconstruction. The system generates drift-free trajectories and photorealistic novel views, reconstructing 100 meters of road or 100,000 m² of aerial scenes in two minutes.

10 Dec 2025


Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at this https URL.

09 Dec 2025

Fast-ARDiff introduces an entropy-informed acceleration framework for continuous-space AR-Diffusion hybrid generative models. This framework achieves up to a 4.88x speedup in inference latency with minimal quality degradation by addressing challenges like entropy mismatch in visual speculative decoding and instability in diffusion distillation.
09 Dec 2025
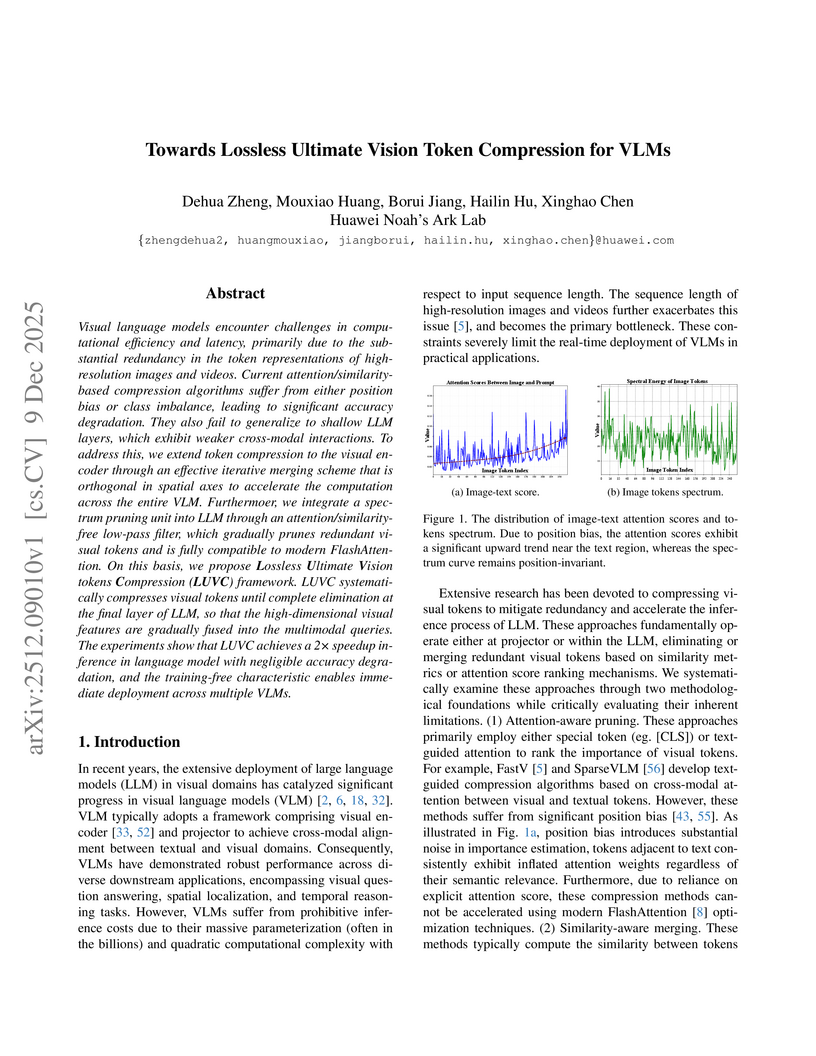
Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.

08 Dec 2025
A two-stage self-supervised framework integrates the Joint-Embedding Predictive Architecture (JEPA) with Density Adaptive Attention Mechanisms (DAAM) to learn robust speech representations. This approach generates efficient, reversible discrete speech tokens at an ultra-low rate of 47.5 tokens/sec, designed for seamless integration with large language models.

09 Dec 2025
Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at this https URL.

07 Dec 2025
The challenge of \textbf{imbalanced regression} arises when standard Empirical Risk Minimization (ERM) biases models toward high-frequency regions of the data distribution, causing severe degradation on rare but high-impact ``tail'' events. Existing strategies uch as loss re-weighting or synthetic over-sampling often introduce noise, distort the underlying distribution, or add substantial algorithmic complexity.
We introduce \textbf{PARIS} (Pruning Algorithm via the Representer theorem for Imbalanced Scenarios), a principled framework that mitigates imbalance by \emph{optimizing the training set itself}. PARIS leverages the representer theorem for neural networks to compute a \textbf{closed-form representer deletion residual}, which quantifies the exact change in validation loss caused by removing a single training point \emph{without retraining}. Combined with an efficient Cholesky rank-one downdating scheme, PARIS performs fast, iterative pruning that eliminates uninformative or performance-degrading samples.
We use a real-world space weather example, where PARIS reduces the training set by up to 75\% while preserving or improving overall RMSE, outperforming re-weighting, synthetic oversampling, and boosting baselines. Our results demonstrate that representer-guided dataset pruning is a powerful, interpretable, and computationally efficient approach to rare-event regression.

09 Dec 2025


HybridToken-VLM (HTC-VLM) presents a hybrid token compression architecture for Vision-Language Models, disentangling high-level semantics and low-level details to achieve extreme compression. The method compresses 580 visual tokens into a single hybrid token, retaining 87.2% of the original model's performance on a suite of seven visual understanding benchmarks and achieving a 7.9x inference speedup.

08 Dec 2025

Researchers developed a metric to quantify visual token information in Vision Large Language Models, uncovering that information becomes uniform and diminishes in deeper layers. This insight led to a hybrid token pruning strategy that reduces inference latency by up to 73% and FLOPs by 74.4% in LLaVA-1.5-7B while maintaining performance.

07 Dec 2025


A training-free framework, DyToK, dynamically compresses visual tokens for Video Large Language Models by leveraging an LLM-guided keyframe prior to adaptively allocate per-frame token budgets. This approach significantly boosts inference speed and reduces memory while enhancing video understanding performance, especially under high compression.
09 Dec 2025


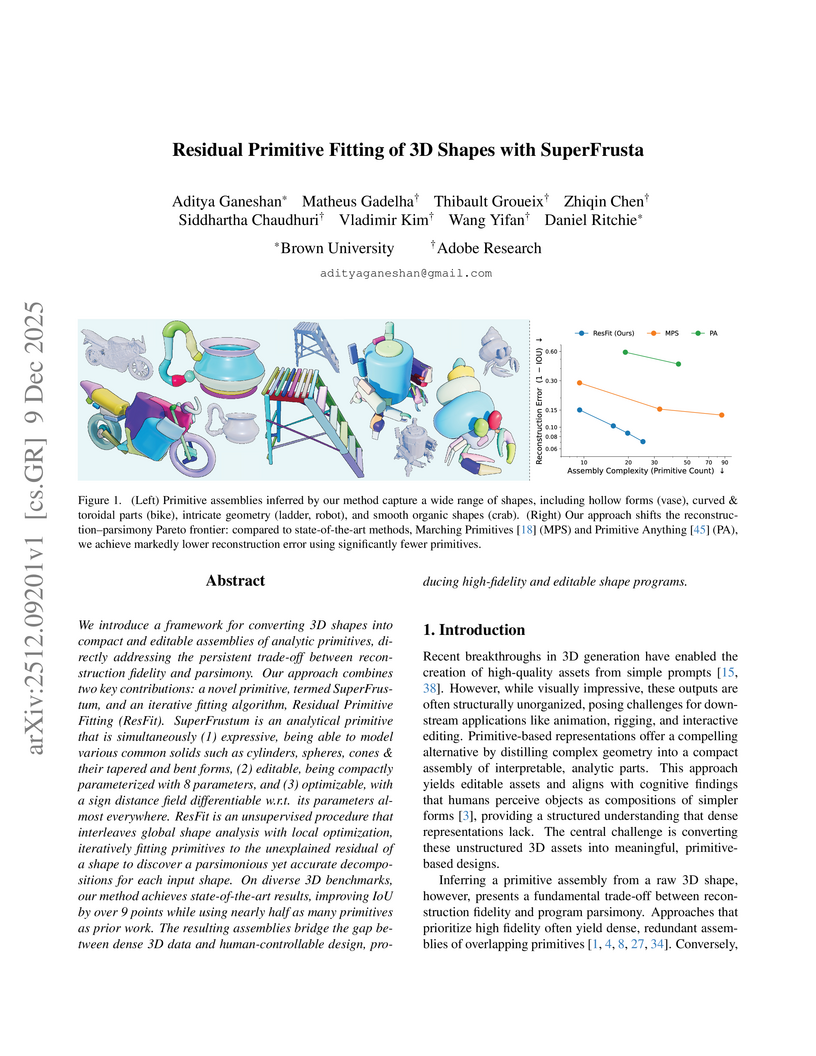
We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.

09 Dec 2025
Huawei Inc. developed EMMA (Efficient Multimodal Understanding, Generation, and Editing), a unified architecture that reduces visual tokens by 80% compared to previous models by employing a 32x compression autoencoder and channel-wise concatenation. EMMA-4B surpasses leading unified multimodal models and achieves competitive performance against specialized expert models across understanding, generation, and editing benchmarks.

08 Dec 2025
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [this https URL](this https URL).

08 Dec 2025
SkipKV optimizes Large Reasoning Model inference by selectively managing KV cache storage and generation at the sentence level, using a training-free approach. The method reduces KV memory by up to 6.7x, lowers generation length by 28%, and improves throughput by 9.6x while maintaining or enhancing reasoning accuracy.

02 Dec 2025
Researchers from Carnegie Mellon University and Peking University introduce Fast Flow Joint Distillation (F2D2), a framework that simultaneously achieves accurate, few-step log-likelihood evaluation and efficient sampling in flow-based generative models. F2D2 produces calibrated negative log-likelihoods with as few as 1-8 neural function evaluations (NFEs) while maintaining high sample quality and can even improve FID over high-NFE teacher models through maximum likelihood self-guidance.

08 Dec 2025
Convolutional Neural Networks (CNNs) have proven highly effective for edge and mobile vision tasks due to their computational efficiency. While many recent works seek to enhance CNNs with global contextual understanding via self-attention-based Vision Transformers, these approaches often introduce significant computational overhead. In this work, we demonstrate that it is possible to retain strong global perception without relying on computationally expensive components. We present GlimmerNet, an ultra-lightweight convolutional network built on the principle of separating receptive field diversity from feature recombination. GlimmerNet introduces Grouped Dilated Depthwise Convolutions(GDBlocks), which partition channels into groups with distinct dilation rates, enabling multi-scale feature extraction at no additional parameter cost. To fuse these features efficiently, we design a novel Aggregator module that recombines cross-group representations using grouped pointwise convolution, significantly lowering parameter overhead. With just 31K parameters and 29% fewer FLOPs than the most recent baseline, GlimmerNet achieves a new state-of-the-art weighted F1-score of 0.966 on the UAV-focused AIDERv2 dataset. These results establish a new accuracy-efficiency trade-off frontier for real-time emergency monitoring on resource-constrained UAV platforms. Our implementation is publicly available at this https URL.

07 Dec 2025
As Large Language Models (LLMs) scale in size and context length, the memory requirements of the key value (KV) cache have emerged as a major bottleneck during autoregressive decoding. The KV cache grows with sequence length and embedding dimension, often exceeding the memory footprint of the model itself and limiting achievable batch sizes and context windows. To address this challenge, we present KV CAR, a unified and architecture agnostic framework that significantly reduces KV cache storage while maintaining model fidelity. KV CAR combines two complementary techniques. First, a lightweight autoencoder learns compact representations of key and value tensors along the embedding dimension, compressing them before they are stored in the KV cache and restoring them upon retrieval. Second, a similarity driven reuse mechanism identifies opportunities to reuse KV tensors of specific attention heads across adjacent layers. Together, these methods reduce the dimensional and structural redundancy in KV tensors without requiring changes to the transformer architecture. Evaluations on GPT 2 and TinyLLaMA models across Wikitext, C4, PIQA, and Winogrande datasets demonstrate that KV CAR achieves up to 47.85 percent KV cache memory reduction with minimal impact on perplexity and zero shot accuracy. System level measurements on an NVIDIA A40 GPU show that the reduced KV footprint directly translates into longer sequence lengths and larger batch sizes during inference. These results highlight the effectiveness of KV CAR in enabling memory efficient LLM inference.

05 Dec 2025
Researchers at MPI-IS, University of Oxford, and ETH Zürich developed a post-training method that makes Transformer attention layers sparse by retaining only 0.2-0.3% of active attention edges. This approach maintains the original model's performance while drastically simplifying its internal computational graphs for enhanced mechanistic interpretability.
There are no more papers matching your filters at the moment.
