
10 Dec 2025
Domain Name System (DNS) tunneling remains a covert channel for data exfiltration and command-and-control communication. Although graph-based methods such as GraphTunnel achieve strong accuracy, they introduce significant latency and computational overhead due to recursive parsing and graph construction, limiting their suitability for real-time deployment. This work presents DNS-HyXNet, a lightweight extended Long Short-Term Memory (xLSTM) hybrid framework designed for efficient sequence-based DNS tunnel detection. DNS-HyXNet integrates tokenized domain embeddings with normalized numerical DNS features and processes them through a two-layer xLSTM network that directly learns temporal dependencies from packet sequences, eliminating the need for graph reconstruction and enabling single-stage multi-class classification. The model was trained and evaluated on two public benchmark datasets with carefully tuned hyperparameters to ensure low memory consumption and fast inference. Across all experimental splits of the DNS-Tunnel-Datasets, DNS-HyXNet achieved up to 99.99% accuracy, with macro-averaged precision, recall, and F1-scores exceeding 99.96%, and demonstrated a per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. These results show that sequential modeling with xLSTM can effectively replace computationally expensive recursive graph generation, offering a deployable and energy-efficient alternative for real-time DNS tunnel detection on commodity hardware.

21 Nov 2025
Generative AI is reshaping offensive cybersecurity by enabling autonomous red team agents that can plan, execute, and adapt during penetration tests. However, existing approaches face trade-offs between generality and specialization, and practical deployments reveal challenges such as hallucinations, context limitations, and ethical concerns. In this work, we introduce a novel command & control (C2) architecture leveraging the Model Context Protocol (MCP) to coordinate distributed, adaptive reconnaissance agents covertly across networks. Notably, we find that our architecture not only improves goal-directed behavior of the system as whole, but also eliminates key host and network artifacts that can be used to detect and prevent command & control behavior altogether. We begin with a comprehensive review of state-of-the-art generative red teaming methods, from fine-tuned specialist models to modular or agentic frameworks, analyzing their automation capabilities against task-specific accuracy. We then detail how our MCP-based C2 can overcome current limitations by enabling asynchronous, parallel operations and real-time intelligence sharing without periodic beaconing. We furthermore explore advanced adversarial capabilities of this architecture, its detection-evasion techniques, and address dual-use ethical implications, proposing defensive measures and controlled evaluation in lab settings. Experimental comparisons with traditional C2 show drastic reductions in manual effort and detection footprint. We conclude with future directions for integrating autonomous exploitation, defensive LLM agents, predictive evasive maneuvers, and multi-agent swarms. The proposed MCP-enabled C2 framework demonstrates a significant step toward realistic, AI-driven red team operations that can simulate advanced persistent threats while informing the development of next-generation defensive systems.
14 Nov 2025
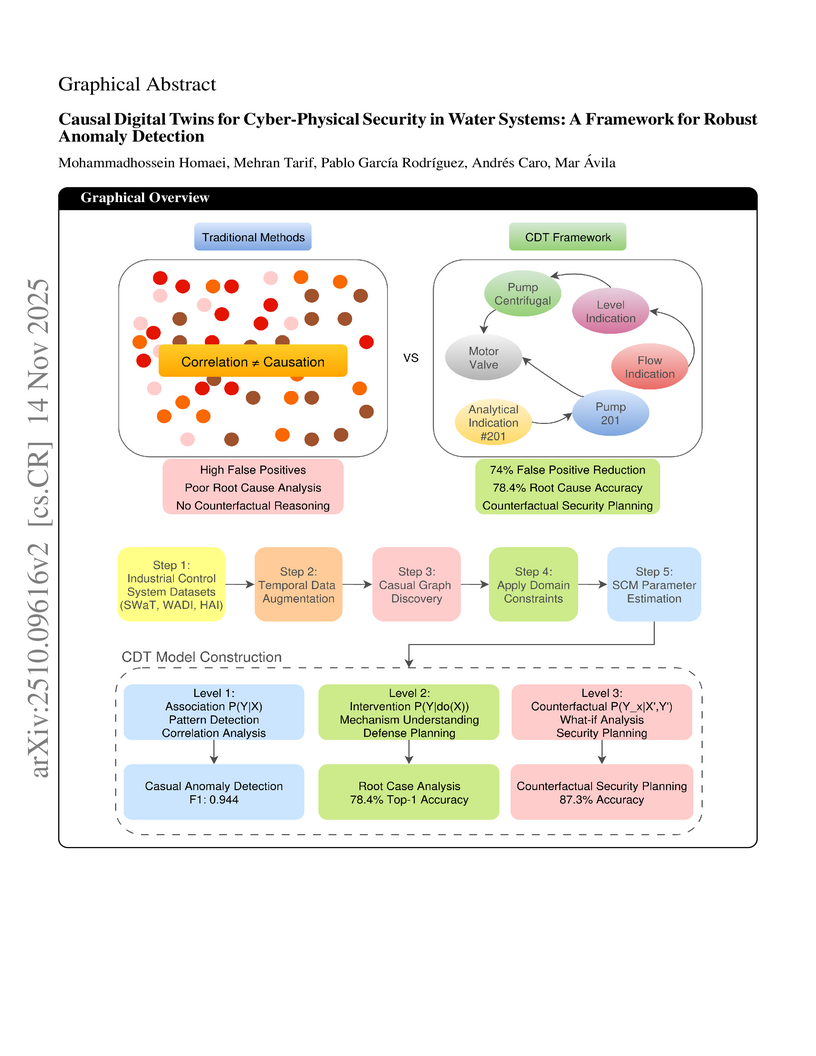
Industrial Control Systems (ICS) in water distribution and treatment face cyber-physical attacks exploiting network and physical vulnerabilities. Current water system anomaly detection methods rely on correlations, yielding high false alarms and poor root cause analysis. We propose a Causal Digital Twin (CDT) framework for water infrastructures, combining causal inference with digital twin modeling. CDT supports association for pattern detection, intervention for system response, and counterfactual analysis for water attack prevention. Evaluated on water-related datasets SWaT, WADI, and HAI, CDT shows 90.8\% compliance with physical constraints and structural Hamming distance 0.133 0.02. F1-scores are (SWaT), (WADI), (HAI, p<0.0024). CDT reduces false positives by 74\%, achieves 78.4\% root cause accuracy, and enables counterfactual defenses reducing attack success by 73.2\%. Real-time performance at 3.2 ms latency ensures safe and interpretable operation for medium-scale water systems.

28 Aug 2025
Cross-chain bridges play a vital role in enabling blockchain interoperability. However, due to the inherent design flaws and the enormous value they hold, they have become prime targets for hacker attacks. Existing detection methods show progress yet remain limited, as they mainly address single-chain behaviors and fail to capture cross-chain semantics. To address this gap, we leverage heterogeneous graph attention networks, which are well-suited for modeling multi-typed entities and relations, to capture the complex execution semantics of cross-chain behaviors. We propose BridgeShield, a detection framework that jointly models the source chain, off-chain coordination, and destination chain within a unified heterogeneous graph representation. BridgeShield incorporates intra-meta-path attention to learn fine-grained dependencies within cross-chain paths and inter-meta-path attention to highlight discriminative cross-chain patterns, thereby enabling precise identification of attack behaviors. Extensive experiments on 51 real-world cross-chain attack events demonstrate that BridgeShield achieves an average F1-score of 92.58%, representing a 24.39% improvement over state-of-the-art baselines. These results validate the effectiveness of BridgeShield as a practical solution for securing cross-chain bridges and enhancing the resilience of multi-chain ecosystems.

03 Sep 2025
We show that Web and Research Agents (WRAs) -- language model-based systems that investigate complex topics on the Internet -- are vulnerable to inference attacks by passive network adversaries such as ISPs. These agents could be deployed locally by organizations and individuals for privacy, legal, or financial purposes. Unlike sporadic web browsing by humans, WRAs visit domains with distinguishable timing correlations, enabling unique fingerprinting attacks.
Specifically, we demonstrate a novel prompt and user trait leakage attack against WRAs that only leverages their network-level metadata (i.e., visited IP addresses and their timings). We start by building a new dataset of WRA traces based on user search queries and queries generated by synthetic personas. We define a behavioral metric (called OBELS) to comprehensively assess similarity between original and inferred prompts, showing that our attack recovers over 73% of the functional and domain knowledge of user prompts. Extending to a multi-session setting, we recover up to 19 of 32 latent traits with high accuracy. Our attack remains effective under partial observability and noisy conditions. Finally, we discuss mitigation strategies that constrain domain diversity or obfuscate traces, showing negligible utility impact while reducing attack effectiveness by an average of 29%.

15 Jul 2025
Finite-State Machines (FSMs) are critical for modeling the operational logic of network protocols, enabling verification, analysis, and vulnerability discovery. However, existing FSM extraction techniques face limitations such as scalability, incomplete coverage, and ambiguity in natural language specifications. In this paper, we propose FlowFSM, a novel agentic framework that leverages Large Language Models (LLMs) combined with prompt chaining and chain-of-thought reasoning to extract accurate FSMs from raw RFC documents. FlowFSM systematically processes protocol specifications, identifies state transitions, and constructs structured rule-books by chaining agent outputs. Experimental evaluation across FTP and RTSP protocols demonstrates that FlowFSM achieves high extraction precision while minimizing hallucinated transitions, showing promising results. Our findings highlight the potential of agent-based LLM systems in the advancement of protocol analysis and FSM inference for cybersecurity and reverse engineering applications.

29 Jun 2025
This survey presents the first unified, end-to-end threat model for LLM-powered AI agent ecosystems, systematically classifying over thirty distinct attack vectors. The work highlights pervasive vulnerabilities across the entire communication stack, including novel attack surfaces introduced by agent communication protocols like MCP and A2A.

05 Jun 2025
Misinformation and disinformation pose significant risks globally, with the Arab region facing unique vulnerabilities due to geopolitical instabilities, linguistic diversity, and cultural nuances. We explore these challenges through the key facets of combating misinformation: detection, tracking, mitigation and community-engagement. We shed light on how connecting with grass-roots fact-checking organizations, understanding cultural norms, promoting social correction, and creating strong collaborative information networks can create opportunities for a more resilient information ecosystem in the Arab world.

02 Dec 2025


AI agents have the potential to significantly alter the cybersecurity landscape. Here, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a given vulnerability), and Patch (patching a given vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \10 to \30,485, covering 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a given vulnerability. We evaluate 10 agents: Claude Code, OpenAI Codex CLI with o3-high and o4-mini, and custom agents with o3-high, GPT-4.1, Gemini 2.5 Pro Preview, Claude 3.7 Sonnet Thinking, Qwen3 235B A22B, Llama 4 Maverick, and DeepSeek-R1. Given up to three attempts, the top-performing agents are Codex CLI: o3-high (12.5% on Detect, mapping to \14,152), Custom Agent: Claude 3.7 Sonnet Thinking (67.5% on Exploit), and Codex CLI: o4-mini (90% on Patch, mapping to \$14,422). Codex CLI: o3-high, Codex CLI: o4-mini, and Claude Code are more capable at defense, achieving higher Patch scores of 90%, 90%, and 87.5%, compared to Exploit scores of 47.5%, 32.5%, and 57.5% respectively; while the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 17.5-67.5% and Patch scores of 25-60%.

22 May 2025

Xiong et al. identify "malicious font injection," a new attack vector that exploits LLMs' visual processing by embedding adversarial prompts within documents using corrupted font files. The technique enables hidden instructions to manipulate LLM responses and facilitate sensitive data leakage via protocols like the Model Context Protocol (MCP).

15 May 2025
The Agent Name Service (ANS) establishes a universal, secure directory for AI agents, enabling discovery and identity verification through integrated Public Key Infrastructure and capability matching across various communication protocols. It provides a foundational layer for secure agent interoperability.

02 May 2025
A comprehensive survey synthesizes research on Large Language Model (LLM) security by systematically categorizing attack vectors and defense strategies, analyzing vulnerabilities in both model architectures and applications while mapping current challenges and future research directions through examination of prevention and detection approaches across multiple Chinese institutions.

25 Apr 2025
Purdue University and Nanjing University researchers developed ParCleanse, a system that leverages large language models to automatically extract formal specifications from RFC documents for validating network protocol parsers. This approach addresses the 'oracle problem' and 'traceability problem' by generating comprehensive test cases and tracing inconsistencies back to specific RFC sections, detecting 69 unique bugs, 68 of which were previously unknown across nine protocols.

30 Aug 2025
Progent, developed by researchers including those from UC Berkeley, introduces a programmable privilege control framework for Large Language Model (LLM) agents, deterministically blocking malicious tool calls. The system achieves a 0% attack success rate across various benchmarks, including prompt injection and malicious tools, while preserving agent utility and incurring negligible runtime overhead.

19 May 2025
MCP Guardian introduces a security-first middleware layer to safeguard AI-to-tool communications using the Model Context Protocol (MCP). The framework effectively mitigates common attack vectors like prompt injection and unauthorized access while adding only a 10-15% latency overhead in a controlled environment.

02 May 2025
Enterprise-Grade Security for the Model Context Protocol (MCP): Frameworks and Mitigation Strategies
Enterprise-Grade Security for the Model Context Protocol (MCP): Frameworks and Mitigation Strategies
This research from collaborators at AWS (independent research) and Intuit's Adversarial AI Security reSearch (A2RS) group presents an enterprise-grade security framework for the Model Context Protocol (MCP). It translates theoretical security concerns into actionable controls and practical strategies, addressing novel threats like tool poisoning and data exfiltration to enable secure enterprise AI integration.
27 Nov 2025
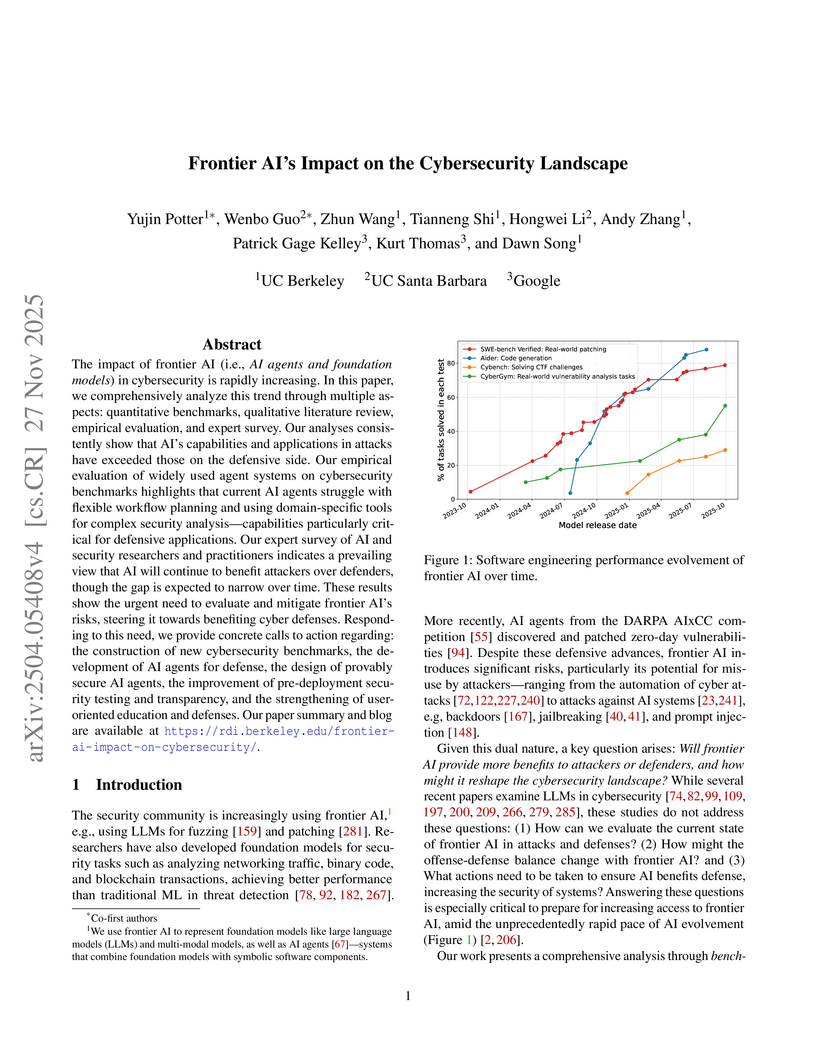
The impact of frontier AI (i.e., AI agents and foundation models) in cybersecurity is rapidly increasing. In this paper, we comprehensively analyze this trend through multiple aspects: quantitative benchmarks, qualitative literature review, empirical evaluation, and expert survey. Our analyses consistently show that AI's capabilities and applications in attacks have exceeded those on the defensive side. Our empirical evaluation of widely used agent systems on cybersecurity benchmarks highlights that current AI agents struggle with flexible workflow planning and using domain-specific tools for complex security analysis -- capabilities particularly critical for defensive applications. Our expert survey of AI and security researchers and practitioners indicates a prevailing view that AI will continue to benefit attackers over defenders, though the gap is expected to narrow over time. These results show the urgent need to evaluate and mitigate frontier AI's risks, steering it towards benefiting cyber defenses. Responding to this need, we provide concrete calls to action regarding: the construction of new cybersecurity benchmarks, the development of AI agents for defense, the design of provably secure AI agents, the improvement of pre-deployment security testing and transparency, and the strengthening of user-oriented education and defenses. Our paper summary and blog are available at this https URL.

26 Mar 2025


SHIELDAGENT introduces a novel guardrail agent that applies probabilistic logical reasoning and formal verification to enforce explicit safety policy compliance on LLM-based autonomous agent action trajectories. The system achieved over 90% guardrail accuracy and reduced API queries by 64.7% and inference time by 58.2% compared to baselines, alongside releasing SHIELDAGENT-BENCH, the first comprehensive benchmark for agent guardrails.

23 Feb 2025

Network tomography is a crucial problem in network monitoring, where the
observable path performance metric values are used to infer the unobserved
ones, making it essential for tasks such as route selection, fault diagnosis,
and traffic control. However, most existing methods either assume complete
knowledge of network topology and metric formulas-an unrealistic expectation in
many real-world scenarios with limited observability-or rely entirely on
black-box end-to-end models. To tackle this, in this paper, we argue that a
good network tomography requires synergizing the knowledge from both data and
appropriate inductive bias from (partial) prior knowledge. To see this, we
propose Deep Network Tomography (DeepNT), a novel framework that leverages a
path-centric graph neural network to predict path performance metrics without
relying on predefined hand-crafted metrics, assumptions, or the real network
topology. The path-centric graph neural network learns the path embedding by
inferring and aggregating the embeddings of the sequence of nodes that compose
this path. Training path-centric graph neural networks requires learning the
neural netowrk parameters and network topology under discrete constraints
induced by the observed path performance metrics, which motivates us to design
a learning objective that imposes connectivity and sparsity constraints on
topology and path performance triangle inequality on path performance.
Extensive experiments on real-world and synthetic datasets demonstrate the
superiority of DeepNT in predicting performance metrics and inferring graph
topology compared to state-of-the-art methods.

04 Jan 2022

With the explosive growth of the e-commerce industry, detecting online
transaction fraud in real-world applications has become increasingly important
to the development of e-commerce platforms. The sequential behavior history of
users provides useful information in differentiating fraudulent payments from
regular ones. Recently, some approaches have been proposed to solve this
sequence-based fraud detection problem. However, these methods usually suffer
from two problems: the prediction results are difficult to explain and the
exploitation of the internal information of behaviors is insufficient. To
tackle the above two problems, we propose a Hierarchical Explainable Network
(HEN) to model users' behavior sequences, which could not only improve the
performance of fraud detection but also make the inference process
interpretable. Meanwhile, as e-commerce business expands to new domains, e.g.,
new countries or new markets, one major problem for modeling user behavior in
fraud detection systems is the limitation of data collection, e.g., very few
data/labels available. Thus, in this paper, we further propose a transfer
framework to tackle the cross-domain fraud detection problem, which aims to
transfer knowledge from existing domains (source domains) with enough and
mature data to improve the performance in the new domain (target domain). Our
proposed method is a general transfer framework that could not only be applied
upon HEN but also various existing models in the Embedding & MLP paradigm.
Based on 90 transfer task experiments, we also demonstrate that our transfer
framework could not only contribute to the cross-domain fraud detection task
with HEN, but also be universal and expandable for various existing models.
There are no more papers matching your filters at the moment.
