
09 Dec 2025



Researchers at HKUST developed TrackingWorld, a framework for dense, world-centric 3D tracking of nearly all pixels in monocular videos, effectively disentangling camera and object motion. This method integrates foundation models with a novel optimization pipeline to track objects, including newly emerging ones, demonstrating superior camera pose estimation and 3D depth consistency, achieving, for example, an Abs Rel depth error of 0.218 on Sintel compared to 0.636 from baselines.

09 Dec 2025
SegEarth-OV3 introduces a training-free adaptation of the Segment Anything Model 3 (SAM 3) for open-vocabulary semantic segmentation in remote sensing images. The method establishes a new state-of-the-art for training-free approaches, achieving a 53.4% average mIoU across eight remote sensing benchmarks, an improvement of 12.7% mIoU over previous methods.

09 Dec 2025

The MVP framework introduces a training-free, two-stage approach that significantly improves the reliability and accuracy of GUI grounding models by addressing coordinate prediction instability. It achieves this by aggregating predictions from multiple attention-guided, enlarged views, leading to new state-of-the-art performance on challenging benchmarks like ScreenSpot-Pro and UI-Vision.

10 Dec 2025
Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.

08 Dec 2025
Specialized visual tools can augment large language models or vision language models with expert knowledge (e.g., grounding, spatial reasoning, medical knowledge, etc.), but knowing which tools to call (and when to call them) can be challenging. We introduce DART, a multi-agent framework that uses disagreements between multiple debating visual agents to identify useful visual tools (e.g., object detection, OCR, spatial reasoning, etc.) that can resolve inter-agent disagreement. These tools allow for fruitful multi-agent discussion by introducing new information, and by providing tool-aligned agreement scores that highlight agents in agreement with expert tools, thereby facilitating discussion. We utilize an aggregator agent to select the best answer by providing the agent outputs and tool information. We test DART on four diverse benchmarks and show that our approach improves over multi-agent debate as well as over single agent tool-calling frameworks, beating the next-strongest baseline (multi-agent debate with a judge model) by 3.4% and 2.4% on A-OKVQA and MMMU respectively. We also find that DART adapts well to new tools in applied domains, with a 1.3% improvement on the M3D medical dataset over other strong tool-calling, single agent, and multi-agent baselines. Additionally, we measure text overlap across rounds to highlight the rich discussion in DART compared to existing multi-agent methods. Finally, we study the tool call distribution, finding that diverse tools are reliably used to help resolve disagreement.

10 Dec 2025
We present NordFKB, a fine-grained benchmark dataset for geospatial AI in Norway, derived from the authoritative, highly accurate, national Felles KartdataBase (FKB). The dataset contains high-resolution orthophotos paired with detailed annotations for 36 semantic classes, including both per-class binary segmentation masks in GeoTIFF format and COCO-style bounding box annotations. Data is collected from seven geographically diverse areas, ensuring variation in climate, topography, and urbanization. Only tiles containing at least one annotated object are included, and training/validation splits are created through random sampling across areas to ensure representative class and context distributions. Human expert review and quality control ensures high annotation accuracy. Alongside the dataset, we release a benchmarking repository with standardized evaluation protocols and tools for semantic segmentation and object detection, enabling reproducible and comparable research. NordFKB provides a robust foundation for advancing AI methods in mapping, land administration, and spatial planning, and paves the way for future expansions in coverage, temporal scope, and data modalities.
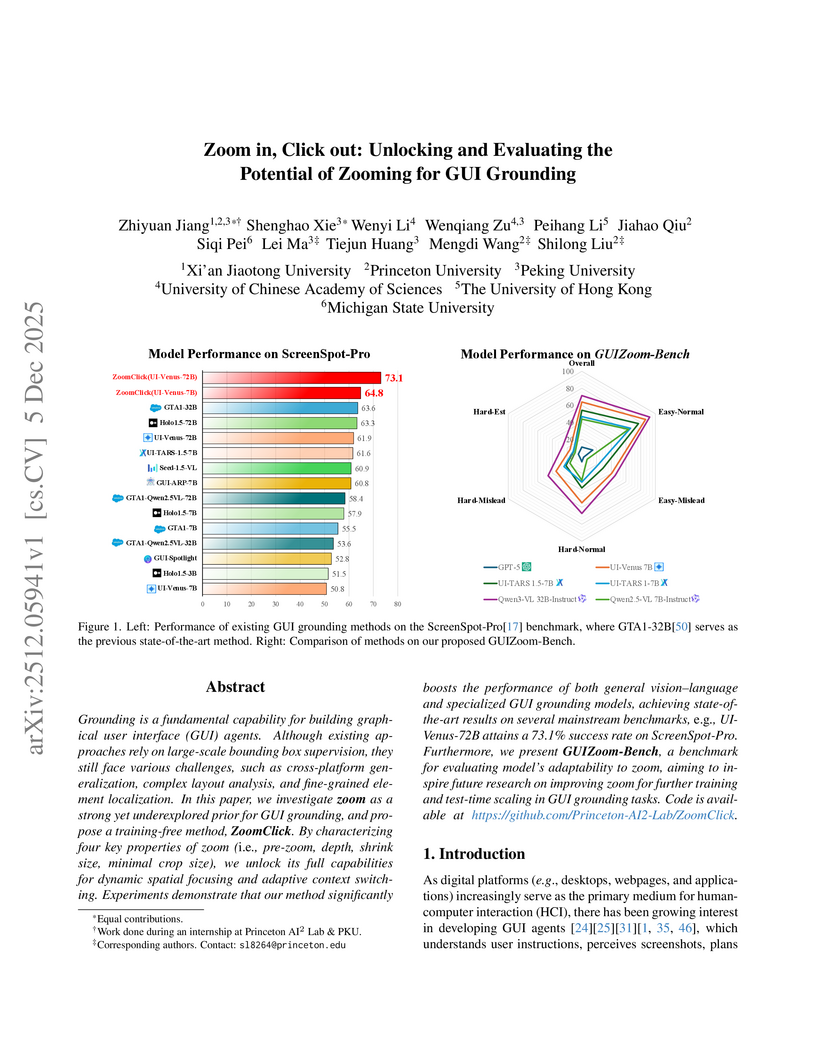
05 Dec 2025
Researchers from Peking University, Princeton University, and other institutions developed ZoomClick, a training-free inference strategy that enhances GUI grounding accuracy by dynamically zooming into relevant regions, and GUIZoom-Bench, a diagnostic benchmark for evaluating zoom behaviors. ZoomClick achieved a new state-of-the-art of 73.1% accuracy on ScreenSpot-Pro and a 66.7% relative improvement on UI-Vision, enabling smaller models to outperform larger unaugmented counterparts.

08 Dec 2025
AutoSeg3D introduces a tracking-centric framework for online, real-time 3D instance segmentation, leveraging Long-Term Memory, Short-Term Memory, and Spatial Consistency Learning. This method achieves 45.5 AP on ScanNet200, a 2.8 AP improvement over the previous state-of-the-art ESAM, while operating at real-time speeds.

09 Dec 2025
With the rise of Large Language Models (LLMs) such as GPT-3, these models exhibit strong generalization capabilities. Through transfer learning techniques such as fine-tuning and prompt tuning, they can be adapted to various downstream tasks with minimal parameter adjustments. This approach is particularly common in the field of Natural Language Processing (NLP). This paper aims to explore the effectiveness of common prompt tuning methods in 3D object detection. We investigate whether a model trained on the large-scale Waymo dataset can serve as a foundation model and adapt to other scenarios within the 3D object detection field. This paper sequentially examines the impact of prompt tokens and prompt generators, and further proposes a Scene-Oriented Prompt Pool (\textbf{SOP}). We demonstrate the effectiveness of prompt pools in 3D object detection, with the goal of inspiring future researchers to delve deeper into the potential of prompts in the 3D field.

09 Dec 2025

Object pose estimation is a fundamental task in computer vision and robotics, yet most methods require extensive, dataset-specific training. Concurrently, large-scale vision language models show remarkable zero-shot capabilities. In this work, we bridge these two worlds by introducing ConceptPose, a framework for object pose estimation that is both training-free and model-free. ConceptPose leverages a vision-language-model (VLM) to create open-vocabulary 3D concept maps, where each point is tagged with a concept vector derived from saliency maps. By establishing robust 3D-3D correspondences across concept maps, our approach allows precise estimation of 6DoF relative pose. Without any object or dataset-specific training, our approach achieves state-of-the-art results on common zero shot relative pose estimation benchmarks, significantly outperforming existing methods by over 62% in ADD(-S) score, including those that utilize extensive dataset-specific training.

09 Dec 2025
Coronary angiography is the main tool for assessing coronary artery disease, but visual grading of stenosis is variable and only moderately related to ischaemia. Wire based fractional flow reserve (FFR) improves lesion selection but is not used systematically. Angiography derived indices such as quantitative flow ratio (QFR) offer wire free physiology, yet many tools are workflow intensive and separate from automated anatomy analysis and virtual PCI planning. We developed AngioAI-QFR, an end to end angiography only pipeline combining deep learning stenosis detection, lumen segmentation, centreline and diameter extraction, per millimetre Relative Flow Capacity profiling, and virtual stenting with automatic recomputation of angiography derived QFR. The system was evaluated in 100 consecutive vessels with invasive FFR as reference. Primary endpoints were agreement with FFR (correlation, mean absolute error) and diagnostic performance for FFR <= 0.80. On held out frames, stenosis detection achieved precision 0.97 and lumen segmentation Dice 0.78. Across 100 vessels, AngioAI-QFR correlated strongly with FFR (r = 0.89, MAE 0.045). The AUC for detecting FFR <= 0.80 was 0.93, with sensitivity 0.88 and specificity 0.86. The pipeline completed fully automatically in 93 percent of vessels, with median time to result 41 s. RFC profiling distinguished focal from diffuse capacity loss, and virtual stenting predicted larger QFR gain in focal than in diffuse disease. AngioAI-QFR provides a practical, near real time pipeline that unifies computer vision, functional profiling, and virtual PCI with automated angiography derived physiology.

10 Dec 2025
Convolutional Neural Networks (CNNs) for computer vision sometimes struggle with understanding images in a global context, as they mainly focus on local patterns. On the other hand, Vision Transformers (ViTs), inspired by models originally created for language processing, use self-attention mechanisms, which allow them to understand relationships across the entire image. In this paper, we compare different types of ViTs (pure, hierarchical, and hybrid) against traditional CNN models across various tasks, including object recognition, detection, and medical image classification. We conduct thorough tests on standard datasets like ImageNet for image classification and COCO for object detection. Additionally, we apply these models to medical imaging using the ChestX-ray14 dataset. We find that hybrid and hierarchical transformers, especially Swin and CvT, offer a strong balance between accuracy and computational resources. Furthermore, by experimenting with data augmentation techniques on medical images, we discover significant performance improvements, particularly with the Swin Transformer model. Overall, our results indicate that Vision Transformers are competitive and, in many cases, outperform traditional CNNs, especially in scenarios requiring the understanding of global visual contexts like medical imaging.

09 Dec 2025
Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.

05 Dec 2025

Large Video-Language Models (Video-LMs) have achieved impressive progress in multimodal understanding, yet their reasoning remains weakly grounded in space and time. We present Know-Show, a new benchmark designed to evaluate spatio-temporal grounded reasoning, the ability of a model to reason about actions and their semantics while simultaneously grounding its inferences in visual and temporal evidence. Know-Show unifies reasoning and localization within a single evaluation framework consisting of five complementary scenarios across spatial (person, object, person-object, and hand-object) and temporal dimensions. Built from Charades, Action Genome, and Ego4D with 2.5K human-authored questions, the benchmark exposes significant gaps between current Video-LMs and human reasoning. To bridge this gap, we propose GRAM, a training-free plug-in that augments Video-LMs with fine-grained grounding through attention-based video token selection and explicit timestamp encoding. Extensive experiments across open and closed Video-LMs (Qwen, VideoLLaVA, GPT-4o, and Gemini, etc.) reveal that existing models struggle to "show what they know" and vice versa, especially in fine-grained hand-object interactions. Know-Show establishes a unified standard for assessing grounded reasoning in video-language understanding and provides insights toward developing interpretable and reliable multimodal reasoning systems. We will release the code at this https URL.

08 Dec 2025
Text as signs, labels, or instructions is a critical element of real-world scenes as they can convey important contextual information. 3D representations such as 3D Gaussian Splatting (3DGS) struggle to preserve fine-grained text details, while achieving high visual fidelity. Small errors in textual element reconstruction can lead to significant semantic loss. We propose STRinGS, a text-aware, selective refinement framework to address this issue for 3DGS reconstruction. Our method treats text and non-text regions separately, refining text regions first and merging them with non-text regions later for full-scene optimization. STRinGS produces sharp, readable text even in challenging configurations. We introduce a text readability measure OCR Character Error Rate (CER) to evaluate the efficacy on text regions. STRinGS results in a 63.6% relative improvement over 3DGS at just 7K iterations. We also introduce a curated dataset STRinGS-360 with diverse text scenarios to evaluate text readability in 3D reconstruction. Our method and dataset together push the boundaries of 3D scene understanding in text-rich environments, paving the way for more robust text-aware reconstruction methods.

07 Dec 2025
 Chinese Academy of Sciences
Chinese Academy of Sciences Fudan University
Fudan University University of Science and Technology of China
University of Science and Technology of China Shanghai Jiao Tong UniversityAerospace Information Research InstituteInstitute of Trustworthy Embodied AI, Fudan UniversityKey Laboratory of Target Cognition and Application Technology, Aerospace Information Research Institute, Chinese Academy of Sciences
Shanghai Jiao Tong UniversityAerospace Information Research InstituteInstitute of Trustworthy Embodied AI, Fudan UniversityKey Laboratory of Target Cognition and Application Technology, Aerospace Information Research Institute, Chinese Academy of SciencesResearchers from Fudan University and Shanghai Jiao Tong University established a spatial retrieval augmented autonomous driving paradigm, integrating offline geographic images to enhance autonomous vehicle robustness. This approach boosted online mapping performance by up to 11.9% mAP and reduced collision rates in planning, particularly under challenging conditions.

08 Dec 2025
This paper investigates and develops methods for detecting small objects in large-scale aerial images. Current approaches for detecting small objects in aerial images often involve image cropping and modifications to detector network architectures. Techniques such as sliding window cropping and architectural enhancements, including higher-resolution feature maps and attention mechanisms, are commonly employed. Given the growing importance of aerial imagery in various critical and industrial applications, the need for robust frameworks for small object detection becomes imperative. To address this need, we adopted the base SW-YOLO approach to enhance speed and accuracy in small object detection by refining cropping dimensions and overlap in sliding window usage and subsequently enhanced it through architectural modifications. we propose a novel model by modifying the base model architecture, including advanced feature extraction modules in the neck for feature map enhancement, integrating CBAM in the backbone to preserve spatial and channel information, and introducing a new head to boost small object detection accuracy. Finally, we compared our method with SAHI, one of the most powerful frameworks for processing large-scale images, and CZDet, which is also based on image cropping, achieving significant improvements in accuracy. The proposed model achieves significant accuracy gains on the VisDrone2019 dataset, outperforming baseline YOLOv5L detection by a substantial margin. Specifically, the final proposed model elevates the mAP .5.5 accuracy on the VisDrone2019 dataset from the base accuracy of 35.5 achieved by the YOLOv5L detector to 61.2. Notably, the accuracy of CZDet, which is another classic method applied to this dataset, is 58.36. This research demonstrates a significant improvement, achieving an increase in accuracy from 35.5 to 61.2.

08 Dec 2025
Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.

09 Dec 2025
This study explores the application of deep learning to improve and automate pollen grain detection and classification in both optical and holographic microscopy images, with a particular focus on veterinary cytology use cases. We used YOLOv8s for object detection and MobileNetV3L for the classification task, evaluating their performance across imaging modalities. The models achieved 91.3% mAP50 for detection and 97% overall accuracy for classification on optical images, whereas the initial performance on greyscale holographic images was substantially lower. We addressed the performance gap issue through dataset expansion using automated labeling and bounding box area enlargement. These techniques, applied to holographic images, improved detection performance from 2.49% to 13.3% mAP50 and classification performance from 42% to 54%. Our work demonstrates that, at least for image classification tasks, it is possible to pair deep learning techniques with cost-effective lensless digital holographic microscopy devices.

10 Dec 2025
Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices. To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation. We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.
There are no more papers matching your filters at the moment.
