
09 Dec 2025

Astra, a collaborative effort from Tsinghua University and Kuaishou Technology, introduces an interactive general world model using an autoregressive denoising framework to generate real-world futures with precise action interactions. The model achieves superior performance in instruction following and visual fidelity across diverse simulation scenarios while efficiently extending a pre-trained video diffusion backbone.

10 Dec 2025
The Astribot Team developed Lumo-1, a Vision-Language-Action (VLA) model that explicitly integrates structured reasoning with physical actions to achieve purposeful robotic control on their Astribot S1 bimanual mobile manipulator. This system exhibits superior generalization to novel objects and instructions, improves reasoning-action consistency through reinforcement learning, and outperforms state-of-the-art baselines in complex, long-horizon, and dexterous tasks.

10 Dec 2025

UniUGP presents a unified framework for end-to-end autonomous driving, integrating scene understanding, future video generation, and trajectory planning through a hybrid expert architecture. This approach enhances interpretability with Chain-of-Thought reasoning and demonstrates state-of-the-art performance in challenging long-tail scenarios and multimodal capabilities across various benchmarks.

10 Dec 2025



Researchers from Columbia University and NYU introduced Online World Modeling (OWM) and Adversarial World Modeling (AWM) to mitigate the train-test gap in world models for gradient-based planning (GBP). These methods enabled GBP to achieve performance comparable to or better than search-based planning algorithms like CEM, while simultaneously reducing computation time by an order of magnitude across various robotic tasks.

07 Dec 2025
Researchers from Microsoft Research Asia, Xi'an Jiaotong University, and Fudan University developed VideoVLA, a robot manipulator that repurposes large pre-trained video generation models. This system jointly predicts future video states and corresponding actions, achieving enhanced generalization capabilities for novel objects and skills in both simulated and real-world environments.

09 Dec 2025
Researchers at ETH Zürich used a reinforcement learning agent to investigate how feedback influences skill acquisition in a complex physical fluid system. Their work demonstrated that learning high-performance skills, particularly those involving non-minimum phase dynamics, can require substantially richer sensory information during training than is necessary for their execution.

10 Dec 2025

The H2R-Grounder framework enables the translation of human interaction videos into physically grounded robot manipulation videos without requiring paired human-robot demonstration data. Researchers at the National University of Singapore's Show Lab developed this approach, which utilizes a simple 2D pose representation and fine-tunes a video diffusion model on unpaired robot videos, achieving higher human preference for motion consistency (54.5%), physical plausibility (63.6%), and visual quality (61.4%) compared to baseline methods.

09 Dec 2025
Researchers from the University of Glasgow developed the Masked Generative Policy (MGP), a framework that employs masked generative transformers for robotic control. This approach integrates parallel action generation with adaptive token refinement, achieving an average 9% higher success rate across 150 tasks while reducing inference time by up to 35x, particularly excelling in long-horizon and non-Markovian environments.

09 Dec 2025

RETAIN, developed at UC Berkeley, introduces a parameter merging strategy for generalist robot policies, interpolating pre-trained and finetuned weights to enable robust adaptation to new tasks. This approach enhances out-of-distribution generalization by approximately 40% on real-world robotic tasks while preserving the policy's existing broad capabilities in low-data scenarios.
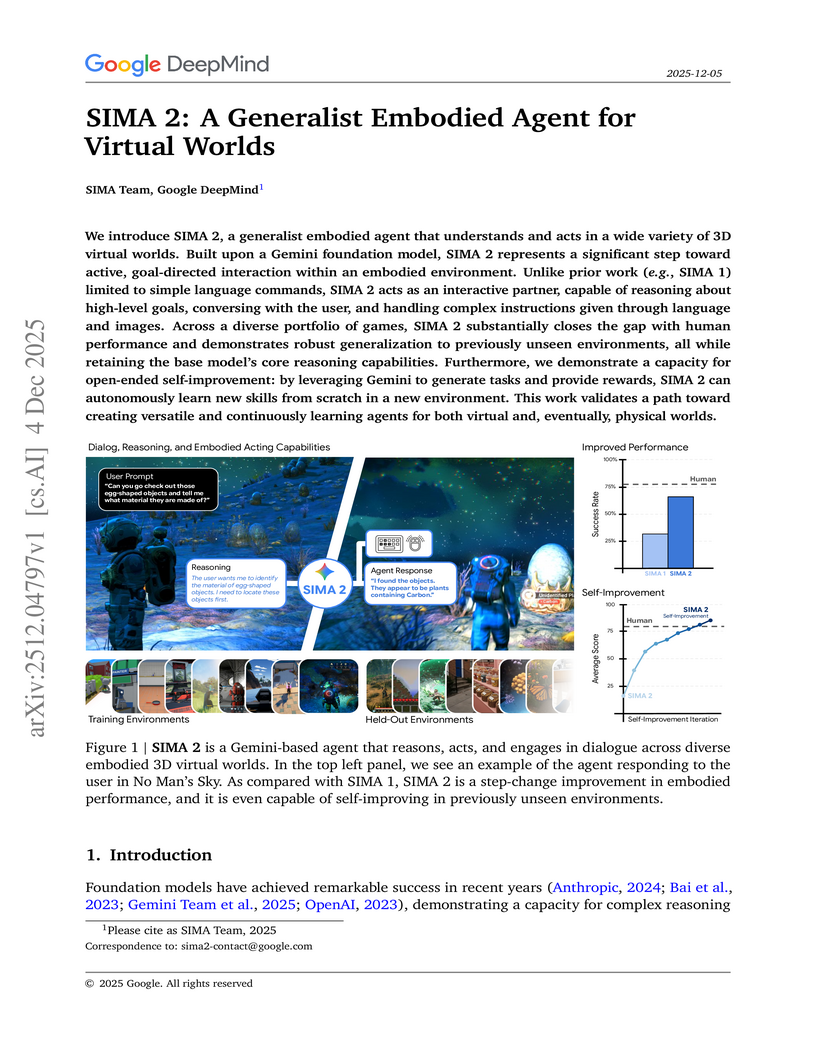
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

09 Dec 2025
Researchers at Physical Intelligence optimized Real-Time Chunking for Vision-Language-Action models by introducing training-time action conditioning, moving computationally intensive prefix conditioning from inference to training. This approach maintained task performance and execution speed, notably reducing latency from 135ms to 108ms and improving robustness at higher inference delays compared to prior methods.

10 Dec 2025
Researchers from the University of Rochester, Purdue University, and Northeastern University developed VisualActBench, a benchmark designed to assess Vision-Language Models' (VLMs) ability to perform proactive, vision-centric action reasoning and align with human value systems. Their evaluation of 29 state-of-the-art VLMs demonstrated a substantial gap between current models and human-level performance, particularly in generating high-priority, initiative-driven actions based solely on visual input.

08 Dec 2025
This document introduces foundational concepts and algorithms in Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL) for embodied agents, providing a self-contained pedagogical resource from ISCTE – University Institute of Lisbon. It offers clear, in-depth explanations of core methods, including necessary mathematical prerequisites, to build a strong understanding for learners.

09 Dec 2025
OSMO is an open-source tactile glove platform designed to capture both shear and normal forces from human demonstrations, facilitating direct transfer of these skills to robots. Policies trained using OSMO achieved 71.69% success in a wiping task, outperforming vision-only baselines (55.75%) by eliminating contact-related failures.

07 Dec 2025
An independent research team secured 1st place in the 2025 BEHAVIOR Challenge, achieving a 26% q-score by enhancing a Vision-Language-Action model (Pi0.5) with innovations like correlated noise for flow matching, "System 2" stage tracking, and practical inference-time heuristics. The approach demonstrated emergent recovery behaviors and addressed challenges in long-horizon, complex manipulation tasks.

07 Dec 2025


MIND-V introduces a hierarchical video generation framework for long-horizon robotic manipulation, autonomously synthesizing physically plausible and logically coherent operation videos. It employs a multi-stage architecture with reinforcement learning for physical alignment, providing a scalable method for generating robot training data.

10 Dec 2025


Researchers developed TacThru, a novel See-Through-Skin sensor enabling truly simultaneous tactile and visual perception, which is integrated into the TacThru-UMI imitation learning framework. This combination achieves an 85.5% average success rate in complex robotic manipulation tasks, surpassing vision-only (55.4%) and traditional tactile-visual baselines (66.3%).

08 Dec 2025

Verifying closed-loop vision-based control systems remains a fundamental challenge due to the high dimensionality of images and the difficulty of modeling visual environments. While generative models are increasingly used as camera surrogates in verification, their reliance on stochastic latent variables introduces unnecessary overapproximation error. To address this bottleneck, we propose a Deterministic World Model (DWM) that maps system states directly to generative images, effectively eliminating uninterpretable latent variables to ensure precise input bounds. The DWM is trained with a dual-objective loss function that combines pixel-level reconstruction accuracy with a control difference loss to maintain behavioral consistency with the real system. We integrate DWM into a verification pipeline utilizing Star-based reachability analysis (StarV) and employ conformal prediction to derive rigorous statistical bounds on the trajectory deviation between the world model and the actual vision-based system. Experiments on standard benchmarks show that our approach yields significantly tighter reachable sets and better verification performance than a latent-variable baseline.

10 Dec 2025


Visual navigation has emerged as a practical alternative to traditional robotic navigation pipelines that rely on detailed mapping and path planning. However, constructing and maintaining 3D maps is often computationally expensive and memory-intensive. We address the problem of visual navigation when exploration videos of a large environment are available. The videos serve as a visual reference, allowing a robot to retrace the explored trajectories without relying on metric maps. Our proposed method, YOPO-Nav (You Only Pass Once), encodes an environment into a compact spatial representation composed of interconnected local 3D Gaussian Splatting (3DGS) models. During navigation, the framework aligns the robot's current visual observation with this representation and predicts actions that guide it back toward the demonstrated trajectory. YOPO-Nav employs a hierarchical design: a visual place recognition (VPR) module provides coarse localization, while the local 3DGS models refine the goal and intermediate poses to generate control actions. To evaluate our approach, we introduce the YOPO-Campus dataset, comprising 4 hours of egocentric video and robot controller inputs from over 6 km of human-teleoperated robot trajectories. We benchmark recent visual navigation methods on trajectories from YOPO-Campus using a Clearpath Jackal robot. Experimental results show YOPO-Nav provides excellent performance in image-goal navigation for real-world scenes on a physical robot. The dataset and code will be made publicly available for visual navigation and scene representation research.

10 Dec 2025
Navigating complex urban environments using natural language instructions poses significant challenges for embodied agents, including noisy language instructions, ambiguous spatial references, diverse landmarks, and dynamic street scenes. Current visual navigation methods are typically limited to simulated or off-street environments, and often rely on precise goal formats, such as specific coordinates or images. This limits their effectiveness for autonomous agents like last-mile delivery robots navigating unfamiliar cities. To address these limitations, we introduce UrbanNav, a scalable framework that trains embodied agents to follow free-form language instructions in diverse urban settings. Leveraging web-scale city walking videos, we develop an scalable annotation pipeline that aligns human navigation trajectories with language instructions grounded in real-world landmarks. UrbanNav encompasses over 1,500 hours of navigation data and 3 million instruction-trajectory-landmark triplets, capturing a wide range of urban scenarios. Our model learns robust navigation policies to tackle complex urban scenarios, demonstrating superior spatial reasoning, robustness to noisy instructions, and generalization to unseen urban settings. Experimental results show that UrbanNav significantly outperforms existing methods, highlighting the potential of large-scale web video data to enable language-guided, real-world urban navigation for embodied agents.
There are no more papers matching your filters at the moment.
