
09 Dec 2025
SAM-Body4D introduces a training-free framework for 4D human body mesh recovery from videos, synergistically combining promptable video object segmentation and image-based human mesh recovery models with an occlusion-aware mask refinement module. The system produces temporally consistent and robust mesh trajectories, effectively handling occlusions and maintaining identity across frames.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

08 Dec 2025

A medical world model named CLARITY, developed by researchers at the University of Central Florida, dynamically simulates treatment-conditioned disease trajectories and refines therapy decisions. It achieves state-of-the-art performance in treatment exploration with a 9.2% F1 improvement over leading baselines on glioma datasets and provides significantly improved survival risk stratification while being 9-15x more computationally efficient than diffusion-based alternatives.

10 Dec 2025
Turbulent flows posses broadband, power-law spectra in which multiscale interactions couple high-wavenumber fluctuations to large-scale dynamics. Although diffusion-based generative models offer a principled probabilistic forecasting framework, we show that standard DDPMs induce a fundamental \emph{spectral collapse}: a Fourier-space analysis of the forward SDE reveals a closed-form, mode-wise signal-to-noise ratio (SNR) that decays monotonically in wavenumber, for spectra , rendering high-wavenumber modes indistinguishable from noise and producing an intrinsic spectral bias. We reinterpret the noise schedule as a spectral regularizer and introduce power-law schedules that preserve fine-scale structure deeper into diffusion time, along with \emph{Lazy Diffusion}, a one-step distillation method that leverages the learned score geometry to bypass long reverse-time trajectories and prevent high- degradation. Applied to high-Reynolds-number 2D Kolmogorov turbulence and Gulf of Mexico ocean reanalysis, these methods resolve spectral collapse, stabilize long-horizon autoregression, and restore physically realistic inertial-range scaling. Together, they show that naïve Gaussian scheduling is structurally incompatible with power-law physics and that physics-aware diffusion processes can yield accurate, efficient, and fully probabilistic surrogates for multiscale dynamical systems.

09 Dec 2025
The Weibull distribution is a commonly adopted choice for modeling the survival of systems subject to maintenance over time. When only proxy indicators and censored observations are available, it becomes necessary to express the distribution's parameters as functions of time-dependent covariates. Deep neural networks provide the flexibility needed to learn complex relationships between these covariates and operational lifetime, thereby extending the capabilities of traditional regression-based models. Motivated by the analysis of a fleet of military vehicles operating in highly variable and demanding environments, as well as by the limitations observed in existing methodologies, this paper introduces WTNN, a new neural network-based modeling framework specifically designed for Weibull survival studies. The proposed architecture is specifically designed to incorporate qualitative prior knowledge regarding the most influential covariates, in a manner consistent with the shape and structure of the Weibull distribution. Through numerical experiments, we show that this approach can be reliably trained on proxy and right-censored data, and is capable of producing robust and interpretable survival predictions that can improve existing approaches.

08 Dec 2025
Decision making often occurs in the presence of incomplete information, leading to the under- or overestimation of risk. Leveraging the observable information to learn the complete information is called nowcasting. In practice, incomplete information is often a consequence of reporting or observation delays. In this paper, we propose an expectation-maximisation (EM) framework for nowcasting that uses machine learning techniques to model both the occurrence as well as the reporting process of events. We allow for the inclusion of covariate information specific to the occurrence and reporting periods as well as characteristics related to the entity for which events occurred. We demonstrate how the maximisation step and the information flow between EM iterations can be tailored to leverage the predictive power of neural networks and (extreme) gradient boosting machines (XGBoost). With simulation experiments, we show that we can effectively model both the occurrence and reporting of events when dealing with high-dimensional covariate information. In the presence of non-linear effects, we show that our methodology outperforms existing EM-based nowcasting frameworks that use generalised linear models in the maximisation step. Finally, we apply the framework to the reporting of Argentinian Covid-19 cases, where the XGBoost-based approach again is most performant.

09 Dec 2025
Understanding disease progression is a central clinical challenge with direct implications for early diagnosis and personalized treatment. While recent generative approaches have attempted to model progression, key mismatches remain: disease dynamics are inherently continuous and monotonic, yet latent representations are often scattered, lacking semantic structure, and diffusion-based models disrupt continuity with random denoising process. In this work, we propose to treat the disease dynamic as a velocity field and leverage Flow Matching (FM) to align the temporal evolution of patient data. Unlike prior methods, it captures the intrinsic dynamic of disease, making the progression more interpretable. However, a key challenge remains: in latent space, Auto-Encoders (AEs) do not guarantee alignment across patients or correlation with clinical-severity indicators (e.g., age and disease conditions). To address this, we propose to learn patient-specific latent alignment, which enforces patient trajectories to lie along a specific axis, with magnitude increasing monotonically with disease severity. This leads to a consistent and semantically meaningful latent space. Together, we present -LFM, a framework for modeling patient-specific latent progression with flow matching. Across three longitudinal MRI benchmarks, -LFM demonstrates strong empirical performance and, more importantly, offers a new framework for interpreting and visualizing disease dynamics.

09 Dec 2025
Stock market prediction is a long-standing challenge in finance, as accurate forecasts support informed investment decisions. Traditional models rely mainly on historical prices, but recent work shows that financial news can provide useful external signals. This paper investigates a multimodal approach that integrates companies' news articles with their historical stock data to improve prediction performance. We compare a Graph Neural Network (GNN) model with a baseline LSTM model. Historical data for each company is encoded using an LSTM, while news titles are embedded with a language model. These embeddings form nodes in a heterogeneous graph, and GraphSAGE is used to capture interactions between articles, companies, and industries. We evaluate two targets: a binary direction-of-change label and a significance-based label. Experiments on the US equities and Bloomberg datasets show that the GNN outperforms the LSTM baseline, achieving 53% accuracy on the first target and a 4% precision gain on the second. Results also indicate that companies with more associated news yield higher prediction accuracy. Moreover, headlines contain stronger predictive signals than full articles, suggesting that concise news summaries play an important role in short-term market reactions.

09 Dec 2025
Intracranial aneurysms remain a major cause of neurological morbidity and mortality worldwide, where rupture risk is tightly coupled to local hemodynamics particularly wall shear stress and oscillatory shear index. Conventional computational fluid dynamics simulations provide accurate insights but are prohibitively slow and require specialized expertise. Clinical imaging alternatives such as 4D Flow MRI offer direct in-vivo measurements, yet their spatial resolution remains insufficient to capture the fine-scale shear patterns that drive endothelial remodeling and rupture risk while being extremely impractical and expensive.
We present a graph neural network surrogate model that bridges this gap by reproducing full-field hemodynamics directly from vascular geometries in less than one minute per cardiac cycle. Trained on a comprehensive dataset of high-fidelity simulations of patient-specific aneurysms, our architecture combines graph transformers with autoregressive predictions to accurately simulate blood flow, wall shear stress, and oscillatory shear index. The model generalizes across unseen patient geometries and inflow conditions without mesh-specific calibration. Beyond accelerating simulation, our framework establishes the foundation for clinically interpretable hemodynamic prediction. By enabling near real-time inference integrated with existing imaging pipelines, it allows direct comparison with hospital phase-diagram assessments and extends them with physically grounded, high-resolution flow fields.
This work transforms high-fidelity simulations from an expert-only research tool into a deployable, data-driven decision support system. Our full pipeline delivers high-resolution hemodynamic predictions within minutes of patient imaging, without requiring computational specialists, marking a step-change toward real-time, bedside aneurysm analysis.

08 Dec 2025

ViSA presents a real-time framework for creating high-fidelity upper-body avatars from a single image by merging 3D reconstruction's geometric stability with video diffusion models' photorealistic dynamics. The method achieves superior visual quality (PSNR 22.09, LPIPS 0.043) and identity preservation at 15.15 FPS, surpassing existing state-of-the-art techniques.

08 Dec 2025
Inspired by graph-based methodologies, we introduce a novel graph-spanning algorithm designed to identify changes in both offline and online data across low to high dimensions. This versatile approach is applicable to Euclidean and graph-structured data with unknown distributions, while maintaining control over error probabilities. Theoretically, we demonstrate that the algorithm achieves high detection power when the magnitude of the change surpasses the lower bound of the minimax separation rate, which scales on the order of . Our method outperforms other techniques in terms of accuracy for both Gaussian and non-Gaussian data. Notably, it maintains strong detection power even with small observation windows, making it particularly effective for online environments where timely and precise change detection is critical.

08 Dec 2025
Estimation of the conditional independence graph (CIG) of high-dimensional multivariate Gaussian time series from multi-attribute data is considered. Existing methods for graph estimation for such data are based on single-attribute models where one associates a scalar time series with each node. In multi-attribute graphical models, each node represents a random vector or vector time series. In this paper we provide a unified theoretical analysis of multi-attribute graph learning for dependent time series using a penalized log-likelihood objective function formulated in the frequency domain using the discrete Fourier transform of the time-domain data. We consider both convex (sparse-group lasso) and non-convex (log-sum and SCAD group penalties) penalty/regularization functions. We establish sufficient conditions in a high-dimensional setting for consistency (convergence of the inverse power spectral density to true value in the Frobenius norm), local convexity when using non-convex penalties, and graph recovery. We do not impose any incoherence or irrepresentability condition for our convergence results. We also empirically investigate selection of the tuning parameters based on the Bayesian information criterion, and illustrate our approach using numerical examples utilizing both synthetic and real data.
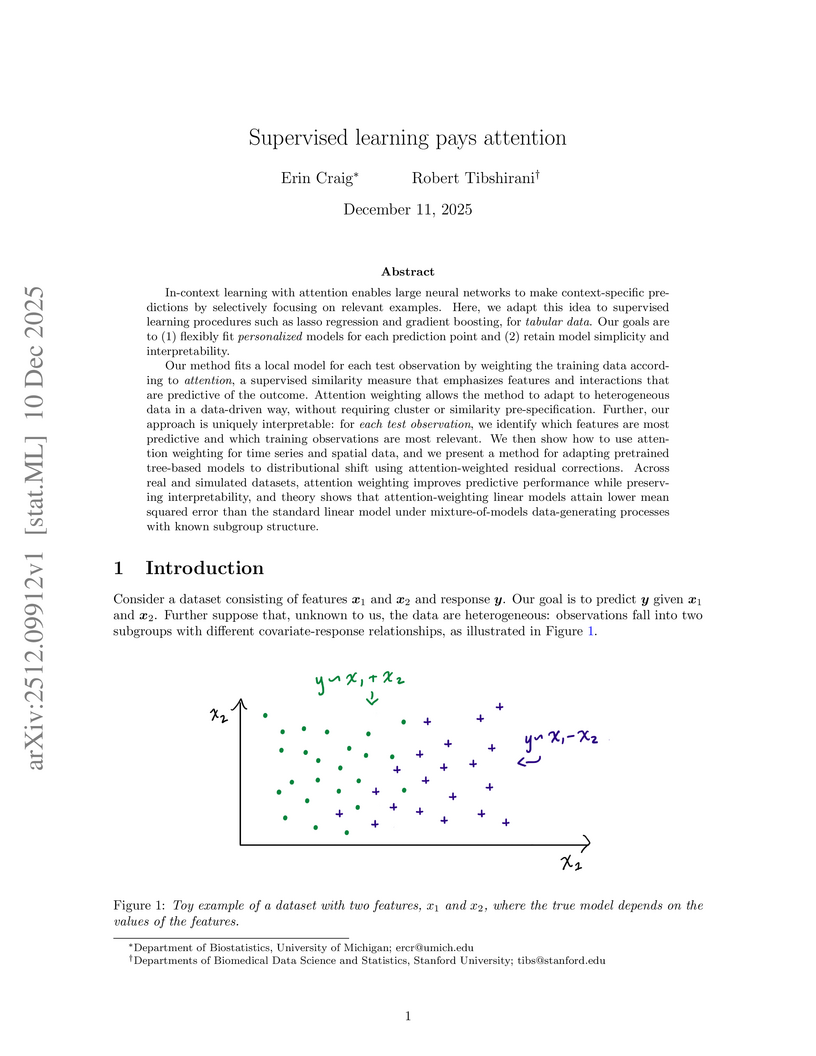
10 Dec 2025


In-context learning with attention enables large neural networks to make context-specific predictions by selectively focusing on relevant examples. Here, we adapt this idea to supervised learning procedures such as lasso regression and gradient boosting, for tabular data. Our goals are to (1) flexibly fit personalized models for each prediction point and (2) retain model simplicity and interpretability.
Our method fits a local model for each test observation by weighting the training data according to attention, a supervised similarity measure that emphasizes features and interactions that are predictive of the outcome. Attention weighting allows the method to adapt to heterogeneous data in a data-driven way, without requiring cluster or similarity pre-specification. Further, our approach is uniquely interpretable: for each test observation, we identify which features are most predictive and which training observations are most relevant. We then show how to use attention weighting for time series and spatial data, and we present a method for adapting pretrained tree-based models to distributional shift using attention-weighted residual corrections. Across real and simulated datasets, attention weighting improves predictive performance while preserving interpretability, and theory shows that attention-weighting linear models attain lower mean squared error than the standard linear model under mixture-of-models data-generating processes with known subgroup structure.

10 Dec 2025
Inferring the eventual goal of a mobile agent from noisy observations of its trajectory is a fundamental estimation problem. We initiate the study of such intent inference using a variant of a Rao-Blackwellized Particle Filter (RBPF), subject to the assumption that the agent's intent manifests through closed-loop behavior with a state-of-the-art provable practical stability property. Leveraging the assumed closed-form agent dynamics, the RBPF analytically marginalizes the linear-Gaussian substructure and updates particle weights only, improving sample efficiency over a standard particle filter. Two difference estimators are introduced: a Gaussian mixture model using the RBPF weights and a reduced version confining the mixture to the effective sample. We quantify how well the adversary can recover the agent's intent using information-theoretic leakage metrics and provide computable lower bounds on the Kullback-Leibler (KL) divergence between the true intent distribution and RBPF estimates via Gaussian-mixture KL bounds. We also provide a bound on the difference in performance between the two estimators, highlighting the fact that the reduced estimator performs almost as well as the complete one. Experiments illustrate fast and accurate intent recovery for compliant agents, motivating future work on designing intent-obfuscating controllers.

09 Dec 2025
Understanding how driver mental states differ between active and autonomous driving is critical for designing safe human-vehicle interfaces. This paper presents the first EEG-based comparison of cognitive load, fatigue, valence, and arousal across the two driving modes. Using data from 31 participants performing identical tasks in both scenarios of three different complexity levels, we analyze temporal patterns, task-complexity effects, and channel-wise activation differences. Our findings show that although both modes evoke similar trends across complexity levels, the intensity of mental states and the underlying neural activation differ substantially, indicating a clear distribution shift between active and autonomous driving. Transfer-learning experiments confirm that models trained on active driving data generalize poorly to autonomous driving and vice versa. We attribute this distribution shift primarily to differences in motor engagement and attentional demands between the two driving modes, which lead to distinct spatial and temporal EEG activation patterns. Although autonomous driving results in lower overall cortical activation, participants continue to exhibit measurable fluctuations in cognitive load, fatigue, valence, and arousal associated with readiness to intervene, task-evoked emotional responses, and monotony-related passive fatigue. These results emphasize the need for scenario-specific data and models when developing next-generation driver monitoring systems for autonomous vehicles.

10 Dec 2025
We present FineFreq, a large-scale multilingual character frequency dataset derived from the FineWeb and FineWeb2 corpora, covering over 1900 languages and spanning 2013-2025. The dataset contains frequency counts for 96 trillion characters processed from 57 TB of compressed text. For each language, FineFreq provides per-character statistics with aggregate and year-level frequencies, allowing fine-grained temporal analysis. The dataset preserves naturally occurring multilingual features such as cross-script borrowings, emoji, and acronyms without applying artificial filtering. Each character entry includes Unicode metadata (category, script, block), enabling domain-specific or other downstream filtering and analysis. The full dataset is released in both CSV and Parquet formats, with associated metadata, available on GitHub and HuggingFace. this https URL

10 Dec 2025
This study presents QuanvNeXt, an end-to-end fully quanvolutional model for EEG-based depression diagnosis. QuanvNeXt incorporates a novel Cross Residual block, which reduces feature homogeneity and strengthens cross-feature relationships while retaining parameter efficiency. We evaluated QuanvNeXt on two open-source datasets, where it achieved an average accuracy of 93.1% and an average AUC-ROC of 97.2%, outperforming state-of-the-art baselines such as InceptionTime (91.7% accuracy, 95.9% AUC-ROC). An uncertainty analysis across Gaussian noise levels demonstrated well-calibrated predictions, with ECE scores remaining low (0.0436, Dataset 1) to moderate (0.1159, Dataset 2) even at the highest perturbation ({\epsilon} = 0.1). Additionally, a post-hoc explainable AI analysis confirmed that QuanvNeXt effectively identifies and learns spectrotemporal patterns that distinguish between healthy controls and major depressive disorder. Overall, QuanvNeXt establishes an efficient and reliable approach for EEG-based depression diagnosis.

07 Dec 2025
Estimation of differences in conditional independence graphs (CIGs) of two time series Gaussian graphical models (TSGGMs) is investigated where the two TSGGMs are known to have similar structure. The TSGGM structure is encoded in the inverse power spectral density (IPSD) of the time series. In several existing works, one is interested in estimating the difference in two precision matrices to characterize underlying changes in conditional dependencies of two sets of data consisting of independent and identically distributed (i.i.d.) observations. In this paper we consider estimation of the difference in two IPSDs to characterize the underlying changes in conditional dependencies of two sets of time-dependent data. Our approach accounts for data time dependencies unlike past work. We analyze a penalized D-trace loss function approach in the frequency domain for differential graph learning, using Wirtinger calculus. We consider both convex (group lasso) and non-convex (log-sum and SCAD group penalties) penalty/regularization functions. An alternating direction method of multipliers (ADMM) algorithm is presented to optimize the objective function. We establish sufficient conditions in a high-dimensional setting for consistency (convergence of the inverse power spectral density to true value in the Frobenius norm) and graph recovery. Both synthetic and real data examples are presented in support of the proposed approaches. In synthetic data examples, our log-sum-penalized differential time-series graph estimator significantly outperformed our lasso based differential time-series graph estimator which, in turn, significantly outperformed an existing lasso-penalized i.i.d. modeling approach, with score as the performance metric.

10 Dec 2025
The rise of 5G/6G network technologies promises to enable applications like autonomous vehicles and virtual reality, resulting in a significant increase in connected devices and necessarily complicating network management. Even worse, these applications often have strict, yet heterogeneous, performance requirements across metrics like latency and reliability. Much recent work has thus focused on developing the ability to predict network performance. However, traditional methods for network modeling, like discrete event simulators and emulation, often fail to balance accuracy and scalability. Network Digital Twins (NDTs), augmented by machine learning, present a viable solution by creating virtual replicas of physical networks for real- time simulation and analysis. State-of-the-art models, however, fall short of full-fledged NDTs, as they often focus only on a single performance metric or simulated network data. We introduce M3Net, a Multi-Metric Mixture-of-experts (MoE) NDT that uses a graph neural network architecture to estimate multiple performance metrics from an expanded set of network state data in a range of scenarios. We show that M3Net significantly enhances the accuracy of flow delay predictions by reducing the MAPE (Mean Absolute Percentage Error) from 20.06% to 17.39%, while also achieving 66.47% and 78.7% accuracy on jitter and packets dropped for each flow

10 Dec 2025
Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at this https URL.
There are no more papers matching your filters at the moment.
