06 Dec 2025
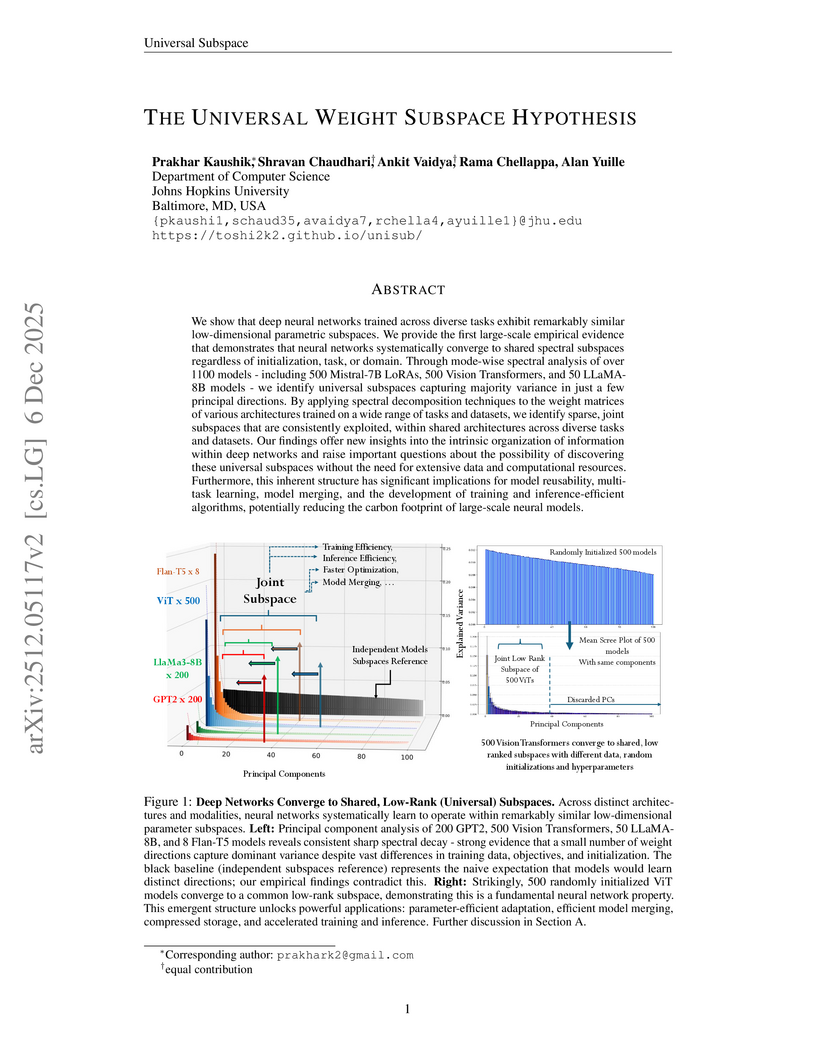
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

09 Dec 2025
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.

08 Dec 2025

Researchers from Fudan University and Shanghai Innovation Institute introduced RoPE++, an extension of Rotary Position Embeddings that re-incorporates the previously discarded imaginary component of attention scores to improve long-context modeling in Large Language Models. This method consistently outperforms standard RoPE on various benchmarks and offers significant KV-cache and parameter efficiency.

09 Dec 2025

Astra, a collaborative effort from Tsinghua University and Kuaishou Technology, introduces an interactive general world model using an autoregressive denoising framework to generate real-world futures with precise action interactions. The model achieves superior performance in instruction following and visual fidelity across diverse simulation scenarios while efficiently extending a pre-trained video diffusion backbone.

08 Dec 2025

The DEMOCRITUS system establishes a new framework for building large causal models (LCMs) by extracting and structuring textual knowledge from Large Language Models (LLMs) across diverse domains. It leverages a Geometric Transformer to embed and organize vast causal claims into coherent, navigable manifolds, which, unlike raw LLM outputs, exhibit global causal coherence and interpretable local structures.

10 Dec 2025
The Astribot Team developed Lumo-1, a Vision-Language-Action (VLA) model that explicitly integrates structured reasoning with physical actions to achieve purposeful robotic control on their Astribot S1 bimanual mobile manipulator. This system exhibits superior generalization to novel objects and instructions, improves reasoning-action consistency through reinforcement learning, and outperforms state-of-the-art baselines in complex, long-horizon, and dexterous tasks.

07 Dec 2025
Researchers from Microsoft Research Asia, Xi'an Jiaotong University, and Fudan University developed VideoVLA, a robot manipulator that repurposes large pre-trained video generation models. This system jointly predicts future video states and corresponding actions, achieving enhanced generalization capabilities for novel objects and skills in both simulated and real-world environments.

09 Dec 2025



Researchers from Google DeepMind, University College London, and the University of Oxford developed D4RT, a unified feedforward model for reconstructing dynamic 4D scenes, encompassing depth, spatio-temporal correspondence, and camera parameters, from video using a single, flexible querying interface. The model achieved state-of-the-art accuracy across various 4D reconstruction and tracking benchmarks, with 3D tracking throughput 18-300 times faster and pose estimation over 100 times faster than prior methods.

08 Dec 2025
Researchers at OpenAI developed a method to train large language models (LLMs) to self-report their non-compliance or shortcomings through a structured "confession" output. This approach uses a disentangled reward system to incentivize honesty, demonstrating that models confess to undesired behaviors in 74.3% of cases and are more likely to be truthful in confessions than in their primary answers, with minimal impact on main task performance.

08 Dec 2025
The paper introduces Group Representational Position Encoding (GRAPE), a unified group-theoretic framework that re-conceptualizes and unifies existing positional encoding mechanisms like RoPE and ALiBi. It provides a principled design space for new encodings, demonstrating improved training stability and superior zero-shot performance in large language models.
07 Dec 2025
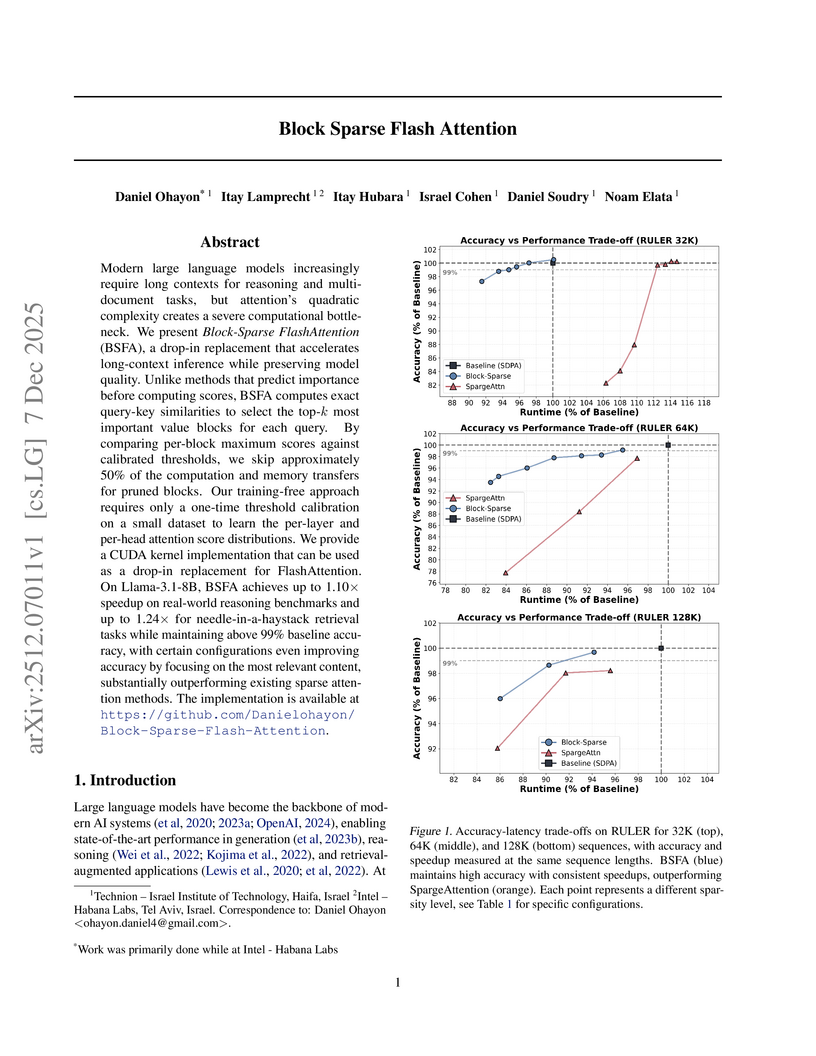
Block Sparse Flash Attention (BSFA) accelerates large language model inference for long input sequences by intelligently skipping computations for negligible value blocks based on exact attention scores. This training-free method maintains high accuracy while achieving speedups up to 1.24x on retrieval tasks and 1.10x for general reasoning.

09 Dec 2025
Multimodal Large Language Models (MLLMs) exhibit substantial cross-modal inconsistency, producing different answers for semantically identical information presented across image, text, and mixed modalities. This problem persists even with perfect Optical Character Recognition (OCR), revealing an inherent reasoning challenge where text inputs generally achieve higher accuracy than image inputs.

07 Dec 2025
Researchers at ShanghaiTech University and Ant Group developed FlashMHF, an efficient multi-head Feed-Forward Network (FFN) for Transformer architectures that integrates a multi-head design with an I/O-aware fused kernel. This approach consistently improves language modeling perplexity and downstream task accuracy while reducing peak memory usage by 3-5x and accelerating inference up to 1.08x compared to standard FFNs.

07 Dec 2025
Researchers from Peking University and Huawei Technologies developed a principled framework for adapting pre-trained autoregressive (AR) models into Block-Diffusion Language Models (DLMs). The adapted 7B-class model, NBDIFF-7B, achieved state-of-the-art performance among diffusion LLMs, with a macro average of 64.3 for its base version and 78.8 for its instruct version across diverse benchmarks.

09 Dec 2025
CLINICALTRIALSHUB unifies clinical trial data from structured registries and unstructured scientific literature, expanding access to structured trial information by 83.8% and providing evidence-grounded, interactive question answering. This platform, developed at The Ohio State University, leverages advanced Large Language Models to streamline information discovery and synthesis for medical professionals and researchers.
08 Dec 2025
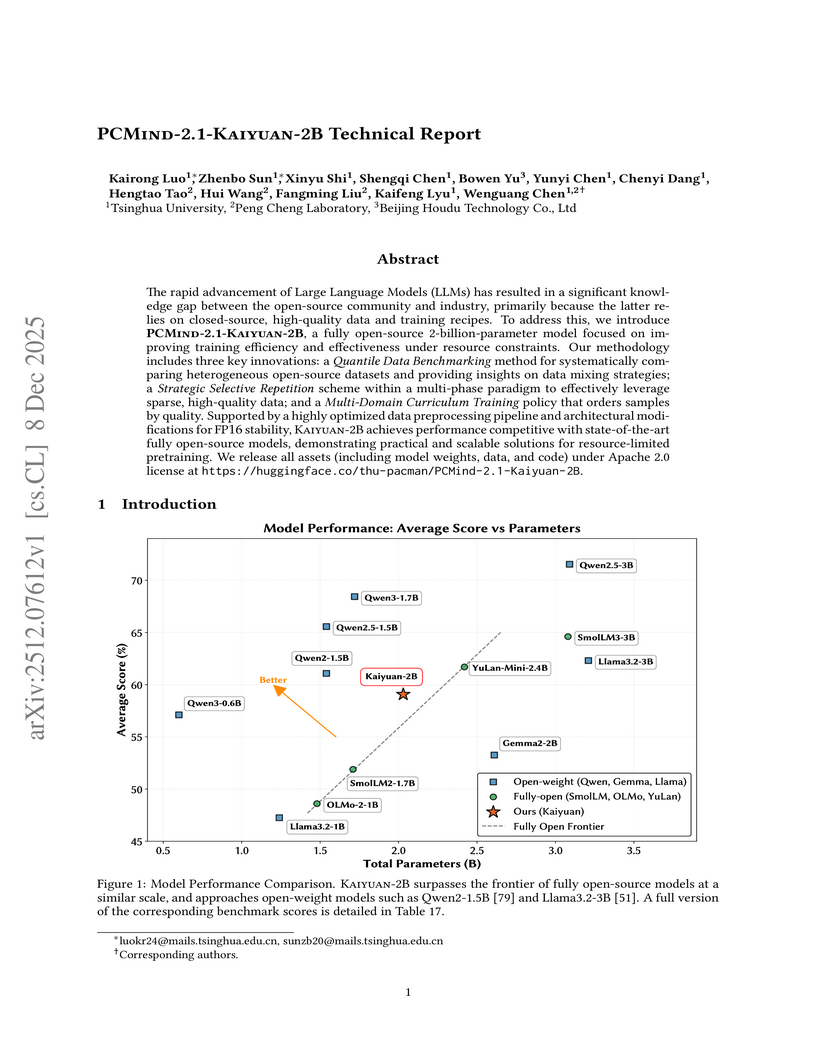
Researchers from Tsinghua University and Peng Cheng Laboratory developed PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter language model. It achieves competitive performance in Chinese language understanding, mathematical reasoning, and code generation by employing a multi-phase curriculum training with strategic data repetition and architectural modifications for FP16 stability, attaining an overall average score of 59.07% across evaluated benchmarks and outperforming several existing open-source models in its class.

09 Dec 2025

VALOR, developed at Caltech, presents an annotation-free framework that trains visual reasoners by employing multimodal verifiers to jointly tune an LLM for reasoning and specialized vision tools for visual grounding. This approach achieves superior performance on various visual reasoning benchmarks, including a 6.5% average improvement over direct-answer VLMs on OMNI3D-BENCH.

10 Dec 2025

Recent research has developed several LLM architectures suitable for inference on end-user devices, such as the Mixture of Lookup Experts (MoLE)~\parencite{jie_mixture_2025}. A key feature of MoLE is that each token id is associated with a dedicated group of experts. For a given input, only the experts corresponding to the input token id will be activated. Since the communication overhead of loading this small number of activated experts into RAM during inference is negligible, expert parameters can be offloaded to storage, making MoLE suitable for resource-constrained devices. However, MoLE's context-independent expert selection mechanism, based solely on input ids, may limit model performance. To address this, we propose the \textbf{M}ixture \textbf{o}f \textbf{L}ookup \textbf{K}ey-\textbf{V}alue Experts (\textbf{MoLKV}) model. In MoLKV, each expert is structured as a key-value pair. For a given input, the input-derived query interacts with the cached key-value experts from the current sequence, generating a context-aware expert output. This context-aware mechanism alleviates the limitation of MoLE, and experimental results demonstrate that MoLKV achieves significantly lower validation loss in small-scale evaluations.

10 Dec 2025


Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at this https URL.
There are no more papers matching your filters at the moment.
