
10 Dec 2025

DynaIP introduces a dynamic image prompt adapter for Multimodal Diffusion Transformers (MM-DiT) that enhances personalized text-to-image generation by achieving superior concept preservation, prompt following, and scalability for multi-subject compositions. The method, developed by Huawei, leverages dynamic decoupling and hierarchical feature fusion, significantly outperforming baselines in qualitative and quantitative evaluations on single and multi-subject tasks.

08 Dec 2025

Image fusion aims to blend complementary information from multiple sensing modalities, yet existing approaches remain limited in robustness, adaptability, and controllability. Most current fusion networks are tailored to specific tasks and lack the ability to flexibly incorporate user intent, especially in complex scenarios involving low-light degradation, color shifts, or exposure imbalance. Moreover, the absence of ground-truth fused images and the small scale of existing datasets make it difficult to train an end-to-end model that simultaneously understands high-level semantics and performs fine-grained multimodal alignment. We therefore present DiTFuse, instruction-driven Diffusion-Transformer (DiT) framework that performs end-to-end, semantics-aware fusion within a single model. By jointly encoding two images and natural-language instructions in a shared latent space, DiTFuse enables hierarchical and fine-grained control over fusion dynamics, overcoming the limitations of pre-fusion and post-fusion pipelines that struggle to inject high-level semantics. The training phase employs a multi-degradation masked-image modeling strategy, so the network jointly learns cross-modal alignment, modality-invariant restoration, and task-aware feature selection without relying on ground truth images. A curated, multi-granularity instruction dataset further equips the model with interactive fusion capabilities. DiTFuse unifies infrared-visible, multi-focus, and multi-exposure fusion-as well as text-controlled refinement and downstream tasks-within a single architecture. Experiments on public IVIF, MFF, and MEF benchmarks confirm superior quantitative and qualitative performance, sharper textures, and better semantic retention. The model also supports multi-level user control and zero-shot generalization to other multi-image fusion scenarios, including instruction-conditioned segmentation.

08 Dec 2025
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.

07 Dec 2025


Meta AI developed Saber, a framework for zero-shot Reference-to-Video generation that leverages a masked training strategy on general video-text datasets, eliminating the need for specialized R2V data. It achieves superior identity consistency and overall performance on benchmarks like OpenS2V-Eval compared to methods trained on costly R2V datasets.

08 Dec 2025
To address the trade-off between robustness and performance for robust VLM, we observe that function words could incur vulnerability of VLMs against cross-modal adversarial attacks, and propose Function-word De-Attention (FDA) accordingly to mitigate the impact of function words. Similar to differential amplifiers, our FDA calculates the original and the function-word cross-attention within attention heads, and differentially subtracts the latter from the former for more aligned and robust VLMs. Comprehensive experiments include 2 SOTA baselines under 6 different attacks on 2 downstream tasks, 3 datasets, and 3 models. Overall, our FDA yields an average 18/13/53% ASR drop with only 0.2/0.3/0.6% performance drops on the 3 tested models on retrieval, and a 90% ASR drop with a 0.3% performance gain on visual grounding. We demonstrate the scalability, generalization, and zero-shot performance of FDA experimentally, as well as in-depth ablation studies and analysis. Code will be made publicly at this https URL.
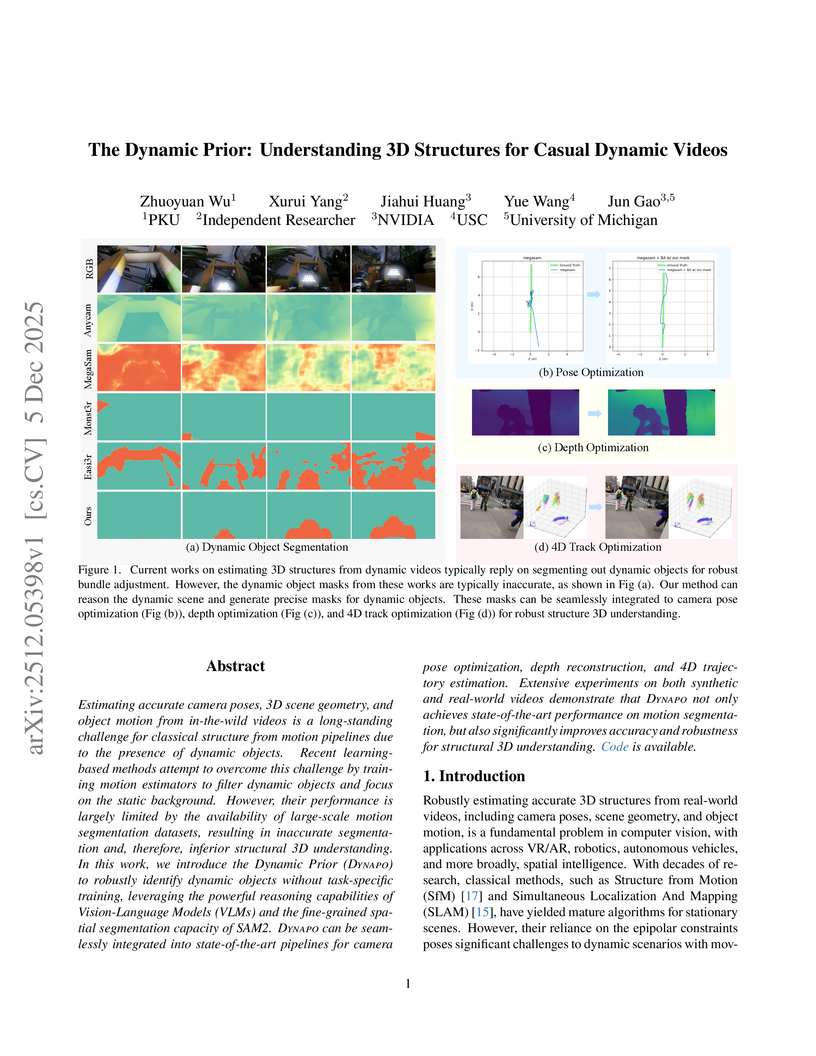
05 Dec 2025




Researchers at Peking University, NVIDIA, USC, and the University of Michigan developed Dynapo, a training-free framework that leverages large vision-language models and advanced segmentation models to robustly identify dynamic objects in casual videos. This approach significantly enhances the accuracy of camera pose estimation, depth reconstruction, and 4D trajectory optimization in dynamic scenes.

08 Dec 2025
Textual explanations make image classifier decisions transparent by describing the prediction rationale in natural language. Large vision-language models can generate captions but are designed for general visual understanding, not classifier-specific reasoning. Existing zero-shot explanation methods align global image features with language, producing descriptions of what is visible rather than what drives the prediction. We propose TEXTER, which overcomes this limitation by isolating decision-critical features before alignment. TEXTER identifies the neurons contributing to the prediction and emphasizes the features encoded in those neurons -- i.e., the decision-critical features. It then maps these emphasized features into the CLIP feature space to retrieve textual explanations that reflect the model's reasoning. A sparse autoencoder further improves interpretability, particularly for Transformer architectures. Extensive experiments show that TEXTER generates more faithful and interpretable explanations than existing methods. The code will be publicly released.

10 Dec 2025
Collaborative pursuit-evasion in cluttered environments presents significant challenges due to sparse rewards and constrained Fields of View (FOV). Standard Multi-Agent Reinforcement Learning (MARL) often suffers from inefficient exploration and fails to scale to large scenarios. We propose PGF-MAPPO (Path-Guided Frontier MAPPO), a hierarchical framework bridging topological planning with reactive control. To resolve local minima and sparse rewards, we integrate an A*-based potential field for dense reward shaping. Furthermore, we introduce Directional Frontier Allocation, combining Farthest Point Sampling (FPS) with geometric angle suppression to enforce spatial dispersion and accelerate coverage. The architecture employs a parameter-shared decentralized critic, maintaining O(1) model complexity suitable for robotic swarms. Experiments demonstrate that PGF-MAPPO achieves superior capture efficiency against faster evaders. Policies trained on 10x10 maps exhibit robust zero-shot generalization to unseen 20x20 environments, significantly outperforming rule-based and learning-based baselines.

09 Dec 2025
SegEarth-OV3 introduces a training-free adaptation of the Segment Anything Model 3 (SAM 3) for open-vocabulary semantic segmentation in remote sensing images. The method establishes a new state-of-the-art for training-free approaches, achieving a 53.4% average mIoU across eight remote sensing benchmarks, an improvement of 12.7% mIoU over previous methods.

09 Dec 2025
Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at this https URL.

08 Dec 2025
Ensuring reliable tool use is critical for safe agentic AI systems. Language models frequently produce unreliable reasoning with plausible but incorrect solutions that are difficult to verify. To address this, we investigate fine-tuning models to use Prolog as an external tool for verifiable computation. Using Group Relative Policy Optimization (GRPO), we fine-tune Qwen2.5-3B-Instruct on a cleaned GSM8K-Prolog-Prover dataset while varying (i) prompt structure, (ii) reward composition (execution, syntax, semantics, structure), and (iii) inference protocol: single-shot, best-of-N, and two agentic modes where Prolog is invoked internally or independently. Our reinforcement learning approach outperforms supervised fine-tuning, with our 3B model achieving zero-shot MMLU performance comparable to 7B few-shot results. Our findings reveal that: 1) joint tuning of prompt, reward, and inference shapes program syntax and logic; 2) best-of-N with external Prolog verification maximizes accuracy on GSM8K; 3) agentic inference with internal repair yields superior zero-shot generalization on MMLU-Stem and MMLU-Pro. These results demonstrate that grounding model reasoning in formal verification systems substantially improves reliability and auditability for safety-critical applications. The source code for reproducing our experiments is available under this https URL

08 Dec 2025
NeSTR is a neuro-symbolic abductive framework designed to enhance temporal reasoning in Large Language Models (LLMs) through a five-stage prompting strategy that integrates symbolic representation, neural inference, and error correction. The framework achieved a macro-average F1 score of 89.7 with GPT-4o-mini, surpassing prior methods and demonstrating robust zero-shot performance across various temporal question answering benchmarks.

08 Dec 2025
Multimodal pre-training remains constrained by the descriptive bias of image-caption pairs, leading models to favor surface linguistic cues over grounded visual understanding. We introduce MMRPT, a masked multimodal reinforcement pre-training framework that strengthens visual reasoning in MLLMs. We are the first to incorporate reinforcement learning directly into the pre-training of large vision-language models, enabling learning signals that reward visual grounding rather than caption imitation. MMRPT constructs masked multimodal data by estimating sentence-level visual dependency via attention over visual tokens and masking highly vision-dependent segments; the model reconstructs these spans through vision-grounded reasoning guided by a semantic-visual reward. Experiments show consistent zero-shot gains across diverse benchmarks and substantially improved robustness under supervised fine-tuning, demonstrating that reinforcement-driven masked reasoning provides a more reliable and generalizable pre-training objective for multimodal models.

08 Dec 2025
Background: The deployment of personalized Large Language Models (LLMs) is currently constrained by the stability-plasticity dilemma. Prevailing alignment methods, such as Supervised Fine-Tuning (SFT), rely on stochastic weight updates that often incur an "alignment tax" -- degrading general reasoning capabilities.
Methods: We propose the Soul Engine, a framework based on the Linear Representation Hypothesis, which posits that personality traits exist as orthogonal linear subspaces. We introduce SoulBench, a dataset constructed via dynamic contextual sampling. Using a dual-head architecture on a frozen Qwen-2.5 base, we extract disentangled personality vectors without modifying the backbone weights.
Results: Our experiments demonstrate three breakthroughs. First, High-Precision Profiling: The model achieves a Mean Squared Error (MSE) of 0.011 against psychological ground truth. Second, Geometric Orthogonality: T-SNE visualization confirms that personality manifolds are distinct and continuous, allowing for "Zero-Shot Personality Injection" that maintains original model intelligence. Third, Deterministic Steering: We achieve robust control over behavior via vector arithmetic, validated through extensive ablation studies.
Conclusion: This work challenges the necessity of fine-tuning for personalization. By transitioning from probabilistic prompting to deterministic latent intervention, we provide a mathematically rigorous foundation for safe, controllable AI personalization.

09 Dec 2025
Flow-based text-to-image (T2I) models excel at prompt-driven image generation, but falter on Image Restoration (IR), often "drifting away" from being faithful to the measurement. Prior work mitigate this drift with data-specific flows or task-specific adapters that are computationally heavy and not scalable across tasks. This raises the question "Can't we efficiently manipulate the existing generative capabilities of a flow model?" To this end, we introduce FlowSteer (FS), an operator-aware conditioning scheme that injects measurement priors along the sampling path,coupling a frozed flow's implicit guidance with explicit measurement constraints. Across super-resolution, deblurring, denoising, and colorization, FS improves measurement consistency and identity preservation in a strictly zero-shot setting-no retrained models, no adapters. We show how the nature of flow models and their sensitivities to noise inform the design of such a scheduler. FlowSteer, although simple, achieves a higher fidelity of reconstructed images, while leveraging the rich generative priors of flow models.

09 Dec 2025
KAIST researchers developed TabPFN-GN, a method that reformulates graph node classification as a tabular learning problem, enabling a pre-trained tabular foundation model to achieve competitive or superior performance compared to Graph Neural Networks (GNNs) without graph-specific training. The method outperforms baseline GNNs on 5 out of 6 heterophilous datasets and ranks first on 3 homophilous datasets.

09 Dec 2025

Object pose estimation is a fundamental task in computer vision and robotics, yet most methods require extensive, dataset-specific training. Concurrently, large-scale vision language models show remarkable zero-shot capabilities. In this work, we bridge these two worlds by introducing ConceptPose, a framework for object pose estimation that is both training-free and model-free. ConceptPose leverages a vision-language-model (VLM) to create open-vocabulary 3D concept maps, where each point is tagged with a concept vector derived from saliency maps. By establishing robust 3D-3D correspondences across concept maps, our approach allows precise estimation of 6DoF relative pose. Without any object or dataset-specific training, our approach achieves state-of-the-art results on common zero shot relative pose estimation benchmarks, significantly outperforming existing methods by over 62% in ADD(-S) score, including those that utilize extensive dataset-specific training.

09 Dec 2025
Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.

10 Dec 2025
Predicting molecule-protein interactions (MPIs) is a fundamental task in computational biology, with crucial applications in drug discovery and molecular function annotation. However, existing MPI models face two major challenges. First, the scarcity of labeled molecule-protein pairs significantly limits model performance, as available datasets capture only a small fraction of biological relevant interactions. Second, most methods rely solely on molecular and protein features, ignoring broader biological context such as genes, metabolic pathways, and functional annotations that could provide essential complementary information. To address these limitations, our framework first aggregates diverse biological datasets, including molecular, protein, genes and pathway-level interactions, and then develop an optimal transport-based approach to generate high-quality pseudo-labels for unlabeled molecule-protein pairs, leveraging the underlying distribution of known interactions to guide label assignment. By treating pseudo-labeling as a mechanism for bridging disparate biological modalities, our approach enables the effective use of heterogeneous data to enhance MPI prediction. We evaluate our framework on multiple MPI datasets including virtual screening tasks and protein retrieval tasks, demonstrating substantial improvements over state-of-the-art methods in prediction accuracies and zero shot ability across unseen interactions. Beyond MPI prediction, our approach provides a new paradigm for leveraging diverse biological data sources to tackle problems traditionally constrained by single- or bi-modal learning, paving the way for future advances in computational biology and drug discovery.

04 Dec 2025
The `GenMimic` framework enables humanoid robots to execute actions from noisy, AI-generated videos in a zero-shot manner by combining 4D human reconstruction and retargeting with a robust reinforcement learning policy. This approach facilitates successful physical reproduction on a Unitree G1 robot and demonstrates improved performance on a newly introduced benchmark dataset of synthetic motions.
There are no more papers matching your filters at the moment.
