
13 Jul 2025


This paper introduces the first Auto-Regressive (AR) framework for multi-view image generation, which leverages information from all preceding views to maintain consistency. The MV-AR method generates multi-view consistent images from diverse inputs such as text, reference images, and geometric shapes, demonstrating improved consistency for distant views and competitive performance against state-of-the-art diffusion models.
10 Oct 2025
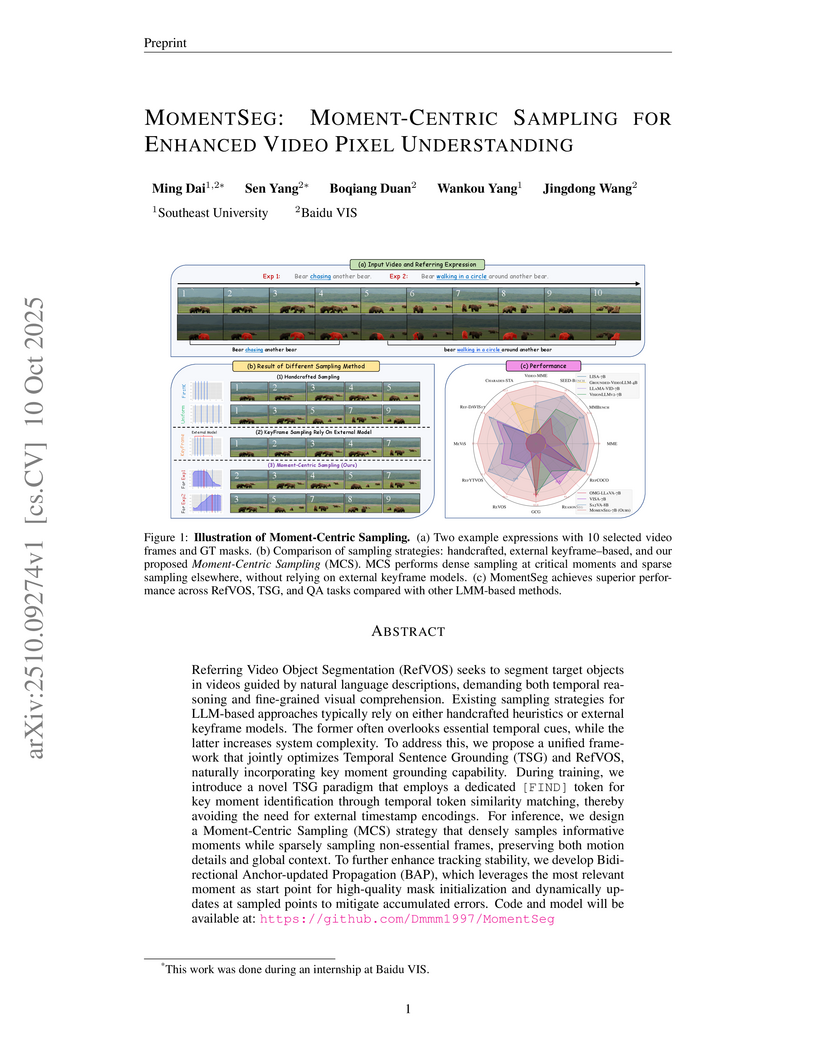
MomentSeg, developed by researchers from Southeast University and Baidu VIS, introduces a unified framework for Referring Video Object Segmentation (RefVOS) and Temporal Sentence Grounding (TSG) that enables Large Multimodal Models to natively identify text-relevant key moments. The approach achieves state-of-the-art performance on various benchmarks, demonstrating a 5% improvement on MeViS (val) and a 6% gain on ReVOS, by employing moment-centric sampling and a bidirectional anchor-updated propagation mechanism.

30 Sep 2025

Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.

06 Dec 2024


This paper introduces OpenGaussian, a method for achieving 3D point-level open-vocabulary understanding with 3D Gaussian Splatting by overcoming limitations in feature expressiveness and 2D-3D correspondence. It learns distinctive, 3D consistent features for individual Gaussians and links them to high-dimensional CLIP features, significantly outperforming existing methods in open-vocabulary object selection and point cloud understanding.

13 Oct 2025

Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at this https URL.

21 Dec 2024


With the rapid advancement of Multimodal Large Language Models (MLLMs), a variety of benchmarks have been introduced to evaluate their capabilities. While most evaluations have focused on complex tasks such as scientific comprehension and visual reasoning, little attention has been given to assessing their fundamental image classification abilities. In this paper, we address this gap by thoroughly revisiting the MLLMs with an in-depth analysis of image classification. Specifically, building on established datasets, we examine a broad spectrum of scenarios, from general classification tasks (e.g., ImageNet, ObjectNet) to more fine-grained categories such as bird and food classification. Our findings reveal that the most recent MLLMs can match or even outperform CLIP-style vision-language models on several datasets, challenging the previous assumption that MLLMs are bad at image classification \cite{VLMClassifier}. To understand the factors driving this improvement, we conduct an in-depth analysis of the network architecture, data selection, and training recipe used in public MLLMs. Our results attribute this success to advancements in language models and the diversity of training data sources. Based on these observations, we further analyze and attribute the potential reasons to conceptual knowledge transfer and enhanced exposure of target concepts, respectively. We hope our findings will offer valuable insights for future research on MLLMs and their evaluation in image classification tasks.

09 Dec 2024

Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360 views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{this https URL}.

01 Nov 2025

In this paper, we propose a novel Visual Reference Prompt (VRP) encoder that empowers the Segment Anything Model (SAM) to utilize annotated reference images as prompts for segmentation, creating the VRP-SAM model. In essence, VRP-SAM can utilize annotated reference images to comprehend specific objects and perform segmentation of specific objects in target image. It is note that the VRP encoder can support a variety of annotation formats for reference images, including \textbf{point}, \textbf{box}, \textbf{scribble}, and \textbf{mask}. VRP-SAM achieves a breakthrough within the SAM framework by extending its versatility and applicability while preserving SAM's inherent strengths, thus enhancing user-friendliness. To enhance the generalization ability of VRP-SAM, the VRP encoder adopts a meta-learning strategy. To validate the effectiveness of VRP-SAM, we conducted extensive empirical studies on the Pascal and COCO datasets. Remarkably, VRP-SAM achieved state-of-the-art performance in visual reference segmentation with minimal learnable parameters. Furthermore, VRP-SAM demonstrates strong generalization capabilities, allowing it to perform segmentation of unseen objects and enabling cross-domain segmentation. The source code and models will be available at this https URL

24 Sep 2024


Most existing multimodality methods use separate backbones for autoregression-based discrete text generation and diffusion-based continuous visual generation, or the same backbone by discretizing the visual data to use autoregression for both text and visual generation. In this paper, we propose to study a simple idea: share one transformer for both autoregression and diffusion. The feasibility comes from two main aspects: (i) Transformer is successfully applied to diffusion for visual generation, and (ii) transformer training for autoregression and diffusion is very similar, and the difference merely lies in that diffusion uses bidirectional attention mask and autoregression uses causal attention mask. Experimental results show that our approach achieves comparable image generation performance to current state-of-the-art methods as well as maintains the text generation capability. The project is publicly available at this https URL.

10 Oct 2022

Freezing the pre-trained backbone has become a standard paradigm to avoid overfitting in few-shot segmentation. In this paper, we rethink the paradigm and explore a new regime: {\em fine-tuning a small part of parameters in the backbone}. We present a solution to overcome the overfitting problem, leading to better model generalization on learning novel classes. Our method decomposes backbone parameters into three successive matrices via the Singular Value Decomposition (SVD), then {\em only fine-tunes the singular values} and keeps others frozen. The above design allows the model to adjust feature representations on novel classes while maintaining semantic clues within the pre-trained backbone. We evaluate our {\em Singular Value Fine-tuning (SVF)} approach on various few-shot segmentation methods with different backbones. We achieve state-of-the-art results on both Pascal-5 and COCO-20 across 1-shot and 5-shot settings. Hopefully, this simple baseline will encourage researchers to rethink the role of backbone fine-tuning in few-shot settings. The source code and models will be available at this https URL.

23 Mar 2025
TexGaussian proposes an octree-based 3D Gaussian Splatting framework to automatically generate high-quality Physically Based Rendering (PBR) materials for untextured 3D meshes. This method generates materials about 60 times faster than prior optimization-based approaches while ensuring 3D global consistency and sharp details.

20 Sep 2024

FullAnno presents a data engine that automatically generates large-scale, high-quality, and fine-grained image annotations by integrating specialized expert models with a robust LLM prompting strategy. This approach triples object annotations, increases caption length by 15 times, and improves MLLM visual comprehension across benchmarks like SQA_I (up by 2.8 points) and SEED (up by 4.5 points) while mitigating hallucinations.

17 Oct 2024

Arcana improves the visual perception of Multi-Modal Large Language Models by introducing the Query Ladder Adapter for enhanced visual feature extraction and Multimodal LoRA for modality-specific learning in the decoder. This approach achieves competitive performance on general VQA and LVLM benchmarks, outperforming many existing MLLMs on OKVQA, ScienceQA, and AI2D, all while maintaining computational efficiency.

14 Aug 2023
In this paper, we study the problem of end-to-end multi-person pose estimation. State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e.g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR. We present a simple yet effective transformer approach, named Group Pose. We simply regard -keypoint pose estimation as predicting a set of keypoint positions, each from a keypoint query, as well as representing each pose with an instance query for scoring pose predictions. Motivated by the intuition that the interaction, among across-instance queries of different types, is not directly helpful, we make a simple modification to decoder self-attention. We replace single self-attention over all the queries with two subsequent group self-attentions: (i) within-instance self-attention, with each over keypoint queries and one instance query, and (ii) same-type across-instance self-attention, each over queries of the same type. The resulting decoder removes the interaction among across-instance type-different queries, easing the optimization and thus improving the performance. Experimental results on MS COCO and CrowdPose show that our approach without human box supervision is superior to previous methods with complex decoders, and even is slightly better than ED-Pose that uses human box supervision. and code are available.

15 Aug 2024
This paper presents a 3D Gaussian Inverse Rendering (GIR) method, employing 3D Gaussian representations to effectively factorize the scene into material properties, light, and geometry. The key contributions lie in three-fold. We compute the normal of each 3D Gaussian using the shortest eigenvector, with a directional masking scheme forcing accurate normal estimation without external supervision. We adopt an efficient voxel-based indirect illumination tracing scheme that stores direction-aware outgoing radiance in each 3D Gaussian to disentangle secondary illumination for approximating multi-bounce light transport. To further enhance the illumination disentanglement, we represent a high-resolution environmental map with a learnable low-resolution map and a lightweight, fully convolutional network. Our method achieves state-of-the-art performance in both relighting and novel view synthesis tasks among the recently proposed inverse rendering methods while achieving real-time rendering. This substantiates our proposed method's efficacy and broad applicability, highlighting its potential as an influential tool in various real-time interactive graphics applications such as material editing and relighting. The code will be released at this https URL.

08 May 2023
This research from Baidu VIS introduces Prompt Tuning Inversion (PTI), a method for text-driven image editing using diffusion models that significantly improves the balance between editability and fidelity. PTI achieves superior reconstruction quality (PSNR 25.71, SSIM 0.8501) and enables high-fidelity, mask-free edits by optimizing a conditional embedding, outperforming prior methods like Null-Text Inversion and DiffEdit.

26 Nov 2025
The computational expense of redundant vision tokens in Large Vision-Language Models (LVLMs) has led many existing methods to compress them via a vision projector. However, this compression may lose visual information that is crucial for tasks relying on fine-grained spatial relationships, such as OCR and Chart&Table Understanding. In this paper, we propose to resample original vision features across the LLM decoder layers to recover visual information and attain efficiency. Following this principle, we introduce Vision Remember, which includes two key modules: (1) Token-Feature Cross-Attention Layer and (2) Token Bidirectional Self-Attention Layer. In the Token bidirectional attention, we employ self-attention mechanism to maintain the bidirectional interaction between vision tokens and the text-guided token. In the Token-Feature interaction attention, we introduce local cross-attention to resample the visual feature and utilize the multi-level fusion to enrich the visual representation. We conduct comprehensive experiments on multiple visual understanding benchmarks and the results with the LLaVA-NeXT baseline show that Vision Remember outperforms TokenPacker by +2.7 and FastV by +5.7 across nearly all the settings. Compared with previous vision feature re-fusion methods, our approach also surpasses DeepStack by +3.9 and SVA Aggregator by +3.4 on the same baseline. The experimental results validate the generalization capability of the proposed method when combined with various efficient vision projectors and LVLMs.

18 Nov 2022
Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.

01 Nov 2025
The In-Context Learning (ICL) is to understand a new task via a few demonstrations (aka. prompt) and predict new inputs without tuning the models. While it has been widely studied in NLP, it is still a relatively new area of research in computer vision. To reveal the factors influencing the performance of visual in-context learning, this paper shows that prompt selection and prompt fusion are two major factors that have a direct impact on the inference performance of visual context learning. Prompt selection is the process of identifying the most appropriate prompt or example to help the model understand new tasks. This is important because providing the model with relevant prompts can help it learn more effectively and efficiently. Prompt fusion involves combining knowledge from different positions within the large-scale visual model. By doing this, the model can leverage the diverse knowledge stored in different parts of the model to improve its performance on new tasks. Based these findings, we propose a simple framework prompt-SelF for visual in-context learning. Specifically, we first use the pixel-level retrieval method to select a suitable prompt, and then use different prompt fusion methods to activate all the knowledge stored in the large-scale model, and finally ensemble the prediction results obtained from different prompt fusion methods to obtain the final prediction results. And we conduct extensive experiments on single-object segmentation and detection tasks to demonstrate the effectiveness of prompt-SelF. Remarkably, the prompt-SelF has outperformed OSLSM based meta-learning in 1-shot segmentation for the first time. This indicated the great potential of visual in-context learning. The source code and models will be available at this https URL.
21 Nov 2022

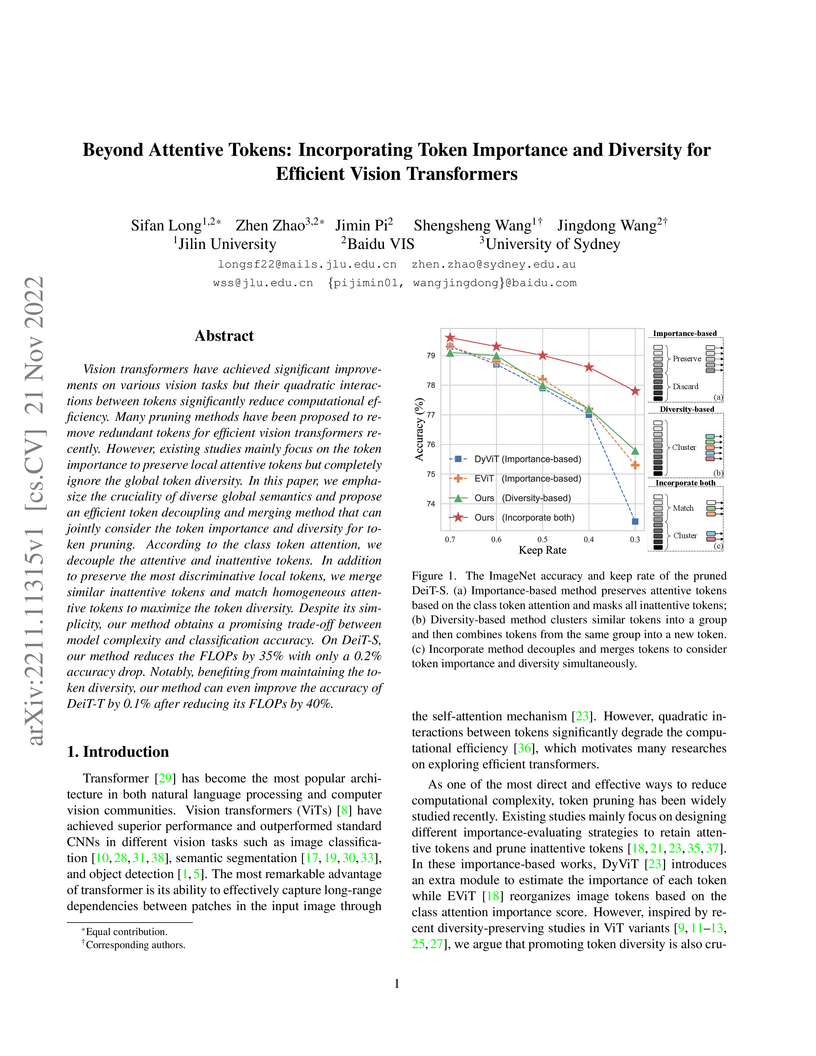
The Token Decoupling and Merging method proposes an efficient Vision Transformer token pruning strategy that considers both token importance and diversity. This approach reduces computational costs by up to 40% for DeiT-T models while maintaining or slightly improving classification accuracy on the ImageNet-1K dataset.
There are no more papers matching your filters at the moment.
