
21 Mar 2017


Clinical medical data, especially in the intensive care unit (ICU), consist of multivariate time series of observations. For each patient visit (or episode), sensor data and lab test results are recorded in the patient's Electronic Health Record (EHR). While potentially containing a wealth of insights, the data is difficult to mine effectively, owing to varying length, irregular sampling and missing data. Recurrent Neural Networks (RNNs), particularly those using Long Short-Term Memory (LSTM) hidden units, are powerful and increasingly popular models for learning from sequence data. They effectively model varying length sequences and capture long range dependencies. We present the first study to empirically evaluate the ability of LSTMs to recognize patterns in multivariate time series of clinical measurements. Specifically, we consider multilabel classification of diagnoses, training a model to classify 128 diagnoses given 13 frequently but irregularly sampled clinical measurements. First, we establish the effectiveness of a simple LSTM network for modeling clinical data. Then we demonstrate a straightforward and effective training strategy in which we replicate targets at each sequence step. Trained only on raw time series, our models outperform several strong baselines, including a multilayer perceptron trained on hand-engineered features.

18 Dec 2017
Objective: Predict patient-specific vitals deemed medically acceptable for discharge from a pediatric intensive care unit (ICU). Design: The means of each patient's hr, sbp and dbp measurements between their medical and physical discharge from the ICU were computed as a proxy for their physiologically acceptable state space (PASS) for successful ICU discharge. These individual PASS values were compared via root mean squared error (rMSE) to population age-normal vitals, a polynomial regression through the PASS values of a Pediatric ICU (PICU) population and predictions from two recurrent neural network models designed to predict personalized PASS within the first twelve hours following ICU admission. Setting: PICU at Children's Hospital Los Angeles (CHLA). Patients: 6,899 PICU episodes (5,464 patients) collected between 2009 and 2016. Interventions: None. Measurements: Each episode data contained 375 variables representing vitals, labs, interventions, and drugs. They also included a time indicator for PICU medical discharge and physical discharge. Main Results: The rMSEs between individual PASS values and population age-normals (hr: 25.9 bpm, sbp: 13.4 mmHg, dbp: 13.0 mmHg) were larger than the rMSEs corresponding to the polynomial regression (hr: 19.1 bpm, sbp: 12.3 mmHg, dbp: 10.8 mmHg). The rMSEs from the best performing RNN model were the lowest (hr: 16.4 bpm; sbp: 9.9 mmHg, dbp: 9.0 mmHg). Conclusion: PICU patients are a unique subset of the general population, and general age-normal vitals may not be suitable as target values indicating physiologic stability at discharge. Age-normal vitals that were specifically derived from the medical-to-physical discharge window of ICU patients may be more appropriate targets for 'acceptable' physiologic state for critical care patients. Going beyond simple age bins, an RNN model can provide more personalized target values.

11 Mar 2025
Mothers of infants have specific demands in fostering emotional bonds with
their children, characterized by dynamics that are different from adult-adult
interactions, notably requiring heightened maternal emotional regulation. In
this study, we analyzed maternal emotional state by modeling maternal emotion
regulation reflected in smiles. The dataset comprises N=94 videos of
approximately 3 plus or minus 1-minutes, capturing free play interactions
between 6 and 12-month-old infants and their mothers. Corresponding demographic
details of self-reported maternal mental health provide variables for
determining mothers' relations to emotions measured during free play. In this
work, we employ diverse methodological approaches to explore the temporal
evolution of maternal smiles. Our findings reveal a correlation between the
temporal dynamics of mothers' smiles and their emotional state. Furthermore, we
identify specific smile features that correlate with maternal emotional state,
thereby enabling informed inferences with existing literature on general smile
analysis. This study offers insights into emotional labor, defined as the
management of one's own emotions for the benefit of others, and emotion
regulation entailed in mother-infant interactions.

20 Oct 2014
Earlier this year, we published a scathing critique of a paper by Mendez et al. (2013) in which the claim was made that a Y chromosome was 237,000-581,000 years old. Elhaik et al. (2014) also attacked a popular article in Scientific American by the senior author of Mendez et al. (2013), whose title was "Sex with other human species might have been the secret of Homo sapiens's [sic] success" (Hammer 2013). Five of the 11 authors of Mendez et al. (2013) have now written a "rebuttal," and we were allowed to reply. Unfortunately, our reply was censored for being "too sarcastic and inflamed." References were removed, meanings were castrated, and a dedication in the Acknowledgments was deleted. Now, that the so-called rebuttal by 45% of the authors of Mendez et al. (2013) has been published together with our vasectomized reply, we decided to make public our entire reply to the so called "rebuttal." In fact, we go one step further, and publish a version of the reply that has not even been self-censored.

11 Dec 2024

A common concern in the field of functional data analysis is the challenge of temporal misalignment, which is typically addressed using curve registration methods. Currently, most of these methods assume the data is governed by a single common shape or a finite mixture of population level shapes. We introduce more flexibility using mixed membership models. Individual observations are assumed to partially belong to different clusters, allowing variation across multiple functional features. We propose a Bayesian hierarchical model to estimate the underlying shapes, as well as the individual time-transformation functions and levels of membership. Motivating this work is data from EEG signals in children with autism spectrum disorder (ASD). Our method agrees with the neuroimaging literature, recovering the 1/f pink noise feature distinctly from the peak in the alpha band. Furthermore, the introduction of a regression component in the estimation of time-transformation functions quantifies the effect of age and clinical designation on the location of the peak alpha frequency (PAF).

01 Oct 2024

Mixed membership models are a flexible class of probabilistic data
representations used for unsupervised and semi-supervised learning, allowing
each observation to partially belong to multiple clusters or features. In this
manuscript, we extend the framework of functional mixed membership models to
allow for covariate-dependent adjustments. The proposed model utilizes a
multivariate Karhunen-Lo\`eve decomposition, which allows for a scalable and
flexible model. Within this framework, we establish a set of sufficient
conditions ensuring the identifiability of the mean, covariance, and allocation
structure up to a permutation of the labels. This manuscript is primarily
motivated by studies on functional brain imaging through electroencephalography
(EEG) of children with autism spectrum disorder (ASD). Specifically, we are
interested in characterizing the heterogeneity of alpha oscillations for
typically developing (TD) children and children with ASD. Since alpha
oscillations are known to change as children develop, we aim to characterize
the heterogeneity of alpha oscillations conditionally on the age of the child.
Using the proposed framework, we were able to gain novel information on the
developmental trajectories of alpha oscillations for children with ASD and how
the developmental trajectories differ between TD children and children with
ASD.

23 Jan 2017
Viewing the trajectory of a patient as a dynamical system, a recurrent neural
network was developed to learn the course of patient encounters in the
Pediatric Intensive Care Unit (PICU) of a major tertiary care center. Data
extracted from Electronic Medical Records (EMR) of about 12000 patients who
were admitted to the PICU over a period of more than 10 years were leveraged.
The RNN model ingests a sequence of measurements which include physiologic
observations, laboratory results, administered drugs and interventions, and
generates temporally dynamic predictions for in-ICU mortality at user-specified
times. The RNN's ICU mortality predictions offer significant improvements over
those from two clinically-used scores and static machine learning algorithms.

28 Mar 2025


Objective: To describe the association of demographic factors with triage
acuity, hospital admission rates, and length of stay (LOS) for adult patients
in the emergency department (ED). Methods: We performed a retrospective
cross-sectional analysis using publicly available electronic health records
describing visits to the ED of a single US medical center during 2011-2019. The
primary exposures of interest were self-reported gender, race/ethnicity, and
age. The outcomes studied were triage acuity, admission to hospital, and LOS in
the ED. Odds ratios were calculated using propensity-score matching. Analyses
were adjusted for confounding variables, including vital signs and diagnoses.
Key Results: Black patients were more likely than White patients to experience
long stays before admission but not before discharge. Men were more likely than
women to be triaged as urgent or admitted, and had shorter stays. Patients over
30 were likelier to be triaged as urgent or admitted, but had longer stays.

03 Oct 2025
Persistent demographic disparities have been identified in the treatment of patients seeking care in the emergency department (ED). These may be driven in part by subconscious biases, which providers themselves may struggle to identify. To better understand the operation of these biases, we performed a retrospective cross-sectional analysis using electronic health records describing 339,400 visits to the ED of a single US pediatric medical center between 2019-2024. Odds ratios were calculated using propensity-score matching. Analyses were adjusted for confounding variables, including chief complaint, insurance type, socio-economic deprivation, and patient comorbidities. We also trained a machine learning [ML] model on this dataset to identify predictors of admission. We found significant demographic disparities in admission (Non-Hispanic Black [NHB] relative to Non-Hispanic White [NHW]: OR 0.77, 95\% CI 0.73-0.81; Hispanic relative to NHW: OR 0.80, 95\% CI 0.76-0.83). We also identified disparities in individual decisions taken during the ED stay. For example, NHB patients were significantly less likely than NHW patients to be assigned an `emergent' triage acuity score of (OR 0.70, 95\% CI 0.67-0.72), but emergent NHB patients were also significantly less likely to be admitted than NHW patients with the same triage acuity (OR 0.86, 95\% CI 0.80-0.93). Demographic disparities were particularly acute wherever patients had normal vital signs, public insurance, moderate socio-economic deprivation, or a home address distant from the hospital. An ML model assigned higher importance to triage score for NHB than NHW patients when predicting admission, reflecting these disparities in assignment. We conclude that many visit characteristics, clinical and otherwise, may influence the operation of subconscious biases and affect ML-driven decision support tools.

20 Nov 2021
High Flow Nasal Cannula (HFNC) provides non-invasive respiratory support for
critically ill children who may tolerate it more readily than other
Non-Invasive (NIV) techniques. Timely prediction of HFNC failure can provide an
indication for increasing respiratory support. This work developed and compared
machine learning models to predict HFNC failure. A retrospective study was
conducted using EMR of patients admitted to a tertiary pediatric ICU from
January 2010 to February 2020. A Long Short-Term Memory (LSTM) model was
trained to generate a continuous prediction of HFNC failure. Performance was
assessed using the area under the receiver operating curve (AUROC) at various
times following HFNC initiation. The sensitivity, specificity, positive and
negative predictive values (PPV, NPV) of predictions at two hours after HFNC
initiation were also evaluated. These metrics were also computed in a cohort
with primarily respiratory diagnoses. 834 HFNC trials [455 training, 173
validation, 206 test] met the inclusion criteria, of which 175 [103, 30, 42]
(21.0%) escalated to NIV or intubation. The LSTM models trained with transfer
learning generally performed better than the LR models, with the best LSTM
model achieving an AUROC of 0.78, vs 0.66 for the LR, two hours after
initiation. Machine learning models trained using EMR data were able to
identify children at risk for failing HFNC within 24 hours of initiation. LSTM
models that incorporated transfer learning, input data perseveration and
ensembling showed improved performance than the LR and standard LSTM models.

07 Sep 2022
Agents must monitor their partners' affective states continuously in order to understand and engage in social interactions. However, methods for evaluating affect recognition do not account for changes in classification performance that may occur during occlusions or transitions between affective states. This paper addresses temporal patterns in affect classification performance in the context of an infant-robot interaction, where infants' affective states contribute to their ability to participate in a therapeutic leg movement activity. To support robustness to facial occlusions in video recordings, we trained infant affect recognition classifiers using both facial and body features. Next, we conducted an in-depth analysis of our best-performing models to evaluate how performance changed over time as the models encountered missing data and changing infant affect. During time windows when features were extracted with high confidence, a unimodal model trained on facial features achieved the same optimal performance as multimodal models trained on both facial and body features. However, multimodal models outperformed unimodal models when evaluated on the entire dataset. Additionally, model performance was weakest when predicting an affective state transition and improved after multiple predictions of the same affective state. These findings emphasize the benefits of incorporating body features in continuous affect recognition for infants. Our work highlights the importance of evaluating variability in model performance both over time and in the presence of missing data when applying affect recognition to social interactions.

12 Oct 2022

Lesion appearance is a crucial clue for medical providers to distinguish referable diabetic retinopathy (rDR) from non-referable DR. Most existing large-scale DR datasets contain only image-level labels rather than pixel-based annotations. This motivates us to develop algorithms to classify rDR and segment lesions via image-level labels. This paper leverages self-supervised equivariant learning and attention-based multi-instance learning (MIL) to tackle this problem. MIL is an effective strategy to differentiate positive and negative instances, helping us discard background regions (negative instances) while localizing lesion regions (positive ones). However, MIL only provides coarse lesion localization and cannot distinguish lesions located across adjacent patches. Conversely, a self-supervised equivariant attention mechanism (SEAM) generates a segmentation-level class activation map (CAM) that can guide patch extraction of lesions more accurately. Our work aims at integrating both methods to improve rDR classification accuracy. We conduct extensive validation experiments on the Eyepacs dataset, achieving an area under the receiver operating characteristic curve (AU ROC) of 0.958, outperforming current state-of-the-art algorithms.

30 Jan 2023
In this paper we describe NPSA, the first parallel nonparametric global
maximum likelihood optimization algorithm using simulated annealing (SA).
Unlike the nonparametric adaptive grid search method NPAG, which is not
guaranteed to find a global optimum solution, and may suffer from the curse of
dimensionality, NPSA is a global optimizer and it is free from these grid
related issues. We illustrate NPSA by a number of examples including a
pharmacokinetics (PK) model for Voriconazole and show that NPSA may be taken as
an upgrade to the current grid search based nonparametric methods.
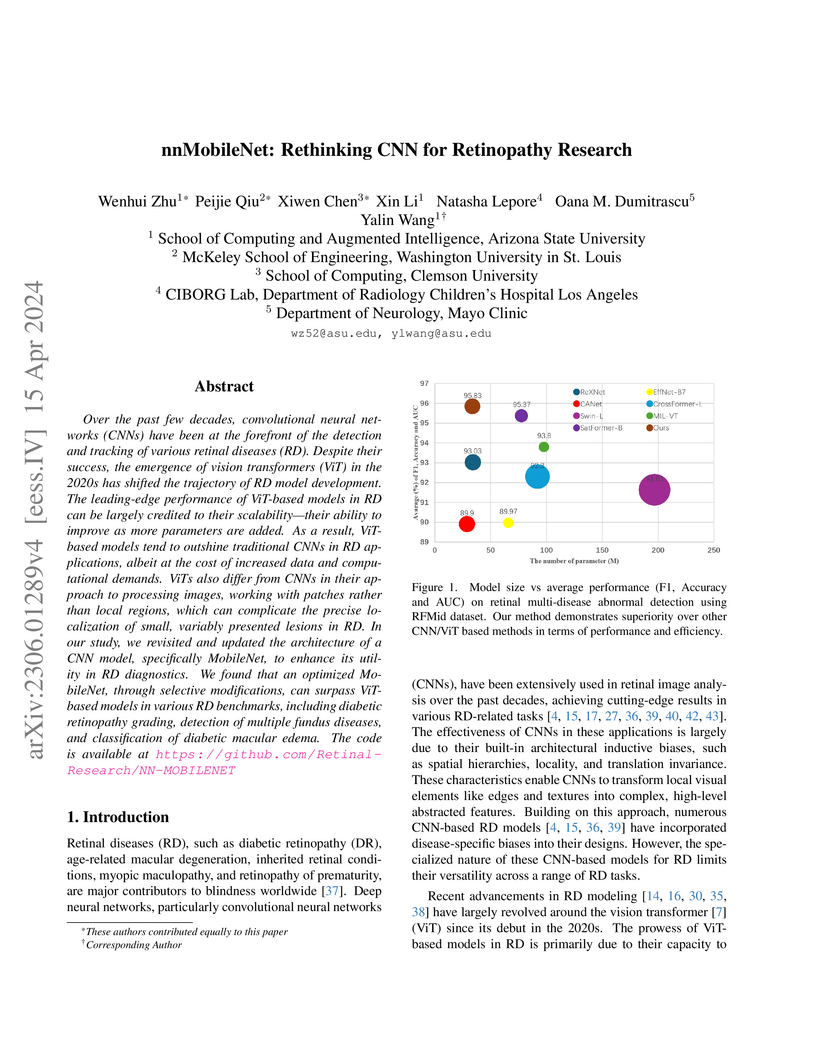
15 Apr 2024
Over the past few decades, convolutional neural networks (CNNs) have been at the forefront of the detection and tracking of various retinal diseases (RD). Despite their success, the emergence of vision transformers (ViT) in the 2020s has shifted the trajectory of RD model development. The leading-edge performance of ViT-based models in RD can be largely credited to their scalability-their ability to improve as more parameters are added. As a result, ViT-based models tend to outshine traditional CNNs in RD applications, albeit at the cost of increased data and computational demands. ViTs also differ from CNNs in their approach to processing images, working with patches rather than local regions, which can complicate the precise localization of small, variably presented lesions in RD. In our study, we revisited and updated the architecture of a CNN model, specifically MobileNet, to enhance its utility in RD diagnostics. We found that an optimized MobileNet, through selective modifications, can surpass ViT-based models in various RD benchmarks, including diabetic retinopathy grading, detection of multiple fundus diseases, and classification of diabetic macular edema. The code is available at this https URL

20 Feb 2025
This paper introduces a non-parametric estimation algorithm designed to
effectively estimate the joint distribution of model parameters with
application to population pharmacokinetics. Our research group has previously
developed the non-parametric adaptive grid (NPAG) algorithm, which while
accurate, explores parameter space using an ad-hoc method to suggest new
support points. In contrast, the non-parametric optimal design (NPOD) algorithm
uses a gradient approach to suggest new support points, which reduces the
amount of time spent evaluating non-relevant points and by this the overall
number of cycles required to reach convergence. In this paper, we demonstrate
that the NPOD algorithm achieves similar solutions to NPAG across two datasets,
while being significantly more efficient in both the number of cycles required
and overall runtime. Given the importance of developing robust and efficient
algorithms for determining drug doses quickly in pharmacokinetics, the NPOD
algorithm represents a valuable advancement in non-parametric modeling. Further
analysis is needed to determine which algorithm performs better under specific
conditions.
There are no more papers matching your filters at the moment.
