
19 Mar 2023

Researchers from Hugging Face and cohere.ai present MTEB, a massive text embedding benchmark comprising 58 datasets across 8 diverse tasks and 112 languages, designed to standardize evaluation. The benchmark reveals that no single model currently excels across all tasks, indicating that existing text embeddings are often specialized for particular applications rather than being universally effective.
26 Sep 2022



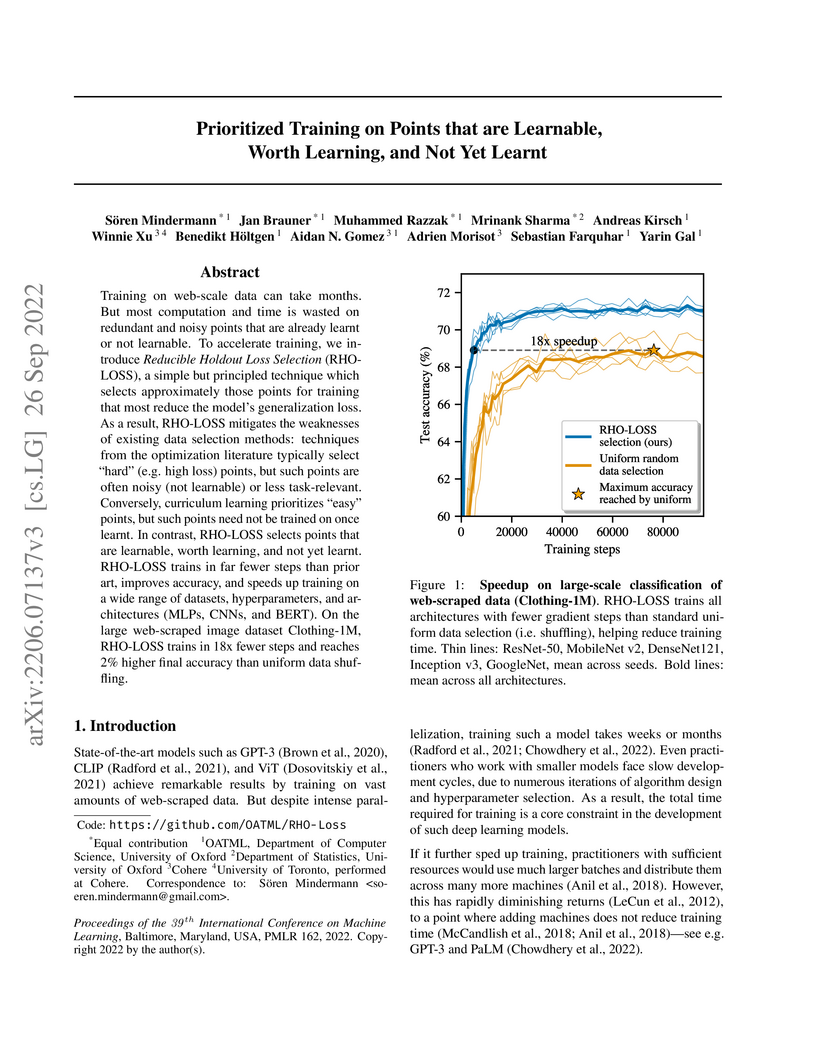
Researchers from the University of Oxford and Cohere developed Reducible Holdout Loss Selection (RHO-LOSS), an online batch selection technique that accelerates deep learning training by up to 18x and improves final accuracy by selecting data points that are learnable, relevant, and not yet mastered.
22 Sep 2022
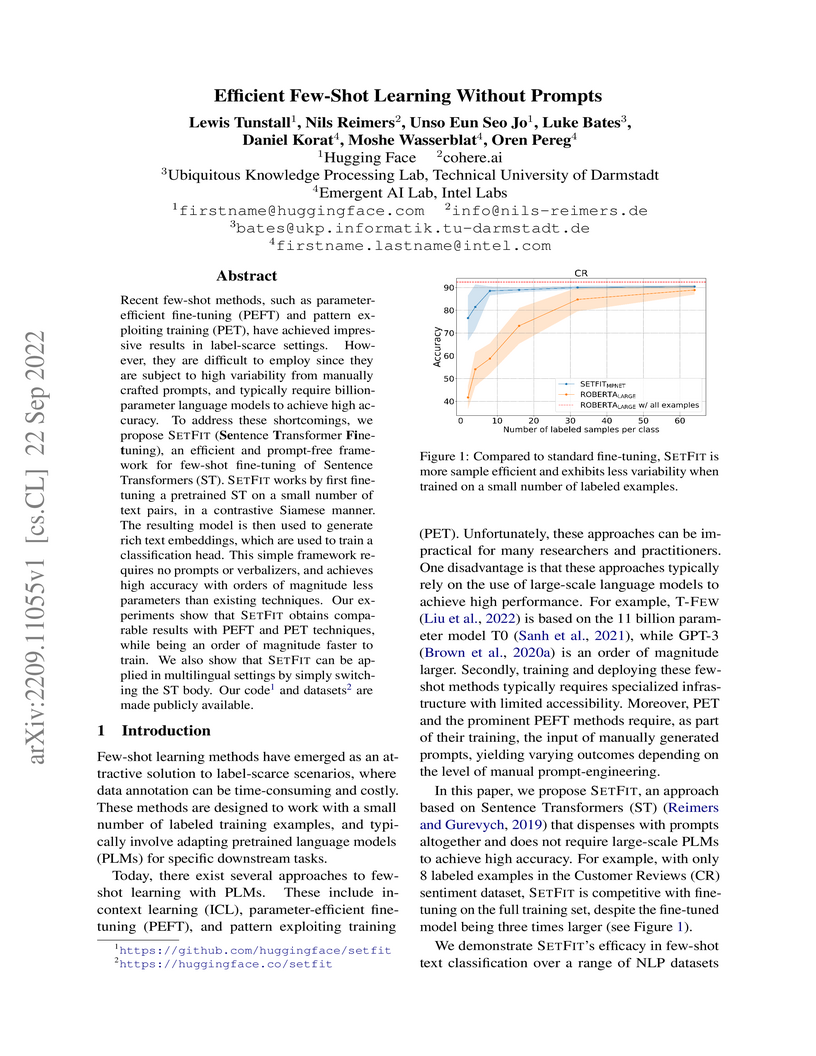
SETFIT introduces a prompt-free framework for few-shot text classification by fine-tuning Sentence Transformers, achieving performance comparable to or surpassing much larger prompt-based models while being orders of magnitude more efficient in training, inference, and memory footprint. This method significantly reduces reliance on massive language models and complex prompt engineering, democratizing access to powerful few-shot capabilities.

27 Jun 2024

Large Language Models (LLMs) frequently overtrust external tools, silently propagating errors. This work demonstrates that LLMs can detect incorrect tool outputs, even without explicit error messages, by employing simple in-context prompting techniques, improving reliability in tasks ranging from arithmetic to embodied AI agent evaluation.

19 Oct 2022

Researchers from the Technical University of Darmstadt and industry partners developed a three-phase approach that combines lexical retrieval, neural re-ranking, and few-shot learning to effectively incorporate user relevance feedback for information-seeking queries. This method enables personalized search results and achieves improved performance by fusing lexical and neural approaches on various benchmark datasets.
01 Jul 2022

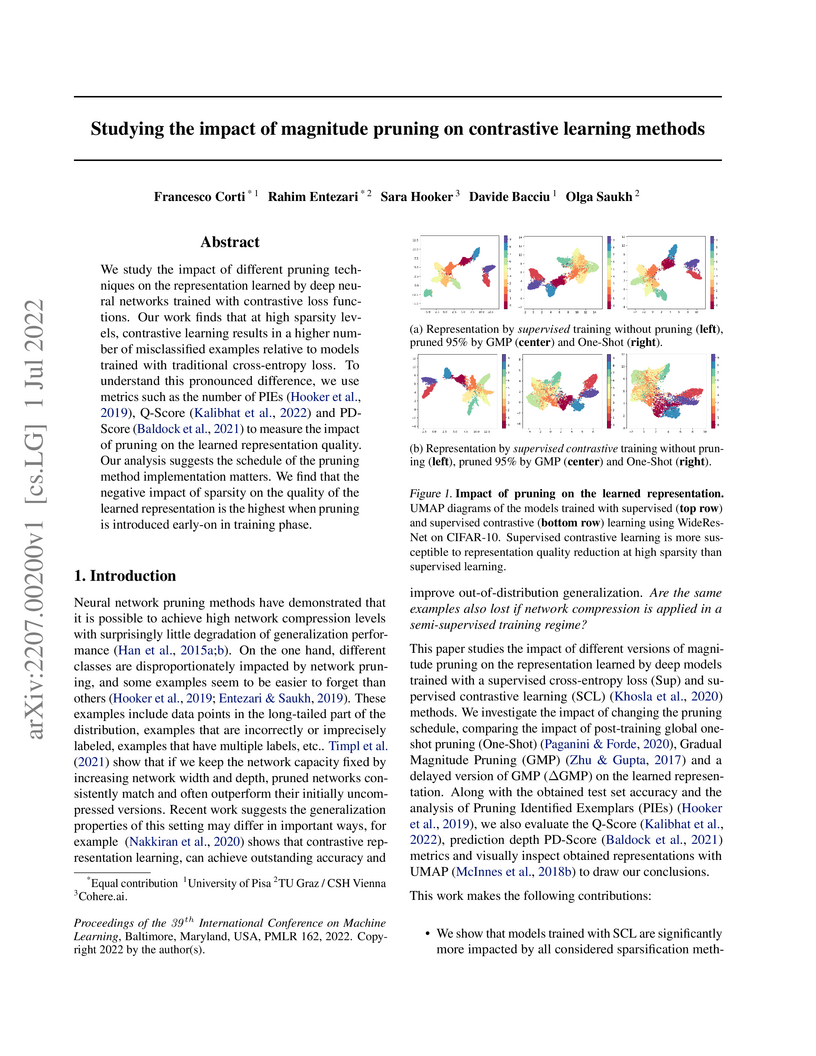
We study the impact of different pruning techniques on the representation
learned by deep neural networks trained with contrastive loss functions. Our
work finds that at high sparsity levels, contrastive learning results in a
higher number of misclassified examples relative to models trained with
traditional cross-entropy loss. To understand this pronounced difference, we
use metrics such as the number of PIEs (Hooker et al., 2019), Q-Score (Kalibhat
et al., 2022), and PD-Score (Baldock et al., 2021) to measure the impact of
pruning on the learned representation quality. Our analysis suggests the
schedule of the pruning method implementation matters. We find that the
negative impact of sparsity on the quality of the learned representation is the
highest when pruning is introduced early on in the training phase.
There are no more papers matching your filters at the moment.
