Ask or search anything...
AdaFV accelerates Vision-Language Models (VLMs) by introducing a training-free self-adaptive cross-modality attention mixture (SACMAM) mechanism. This method intelligently prunes visual tokens based on an adaptive blend of visual saliency and text-to-image similarity, achieving superior performance and robustness, particularly at high reduction rates, often outperforming fine-tuned approaches.
View blog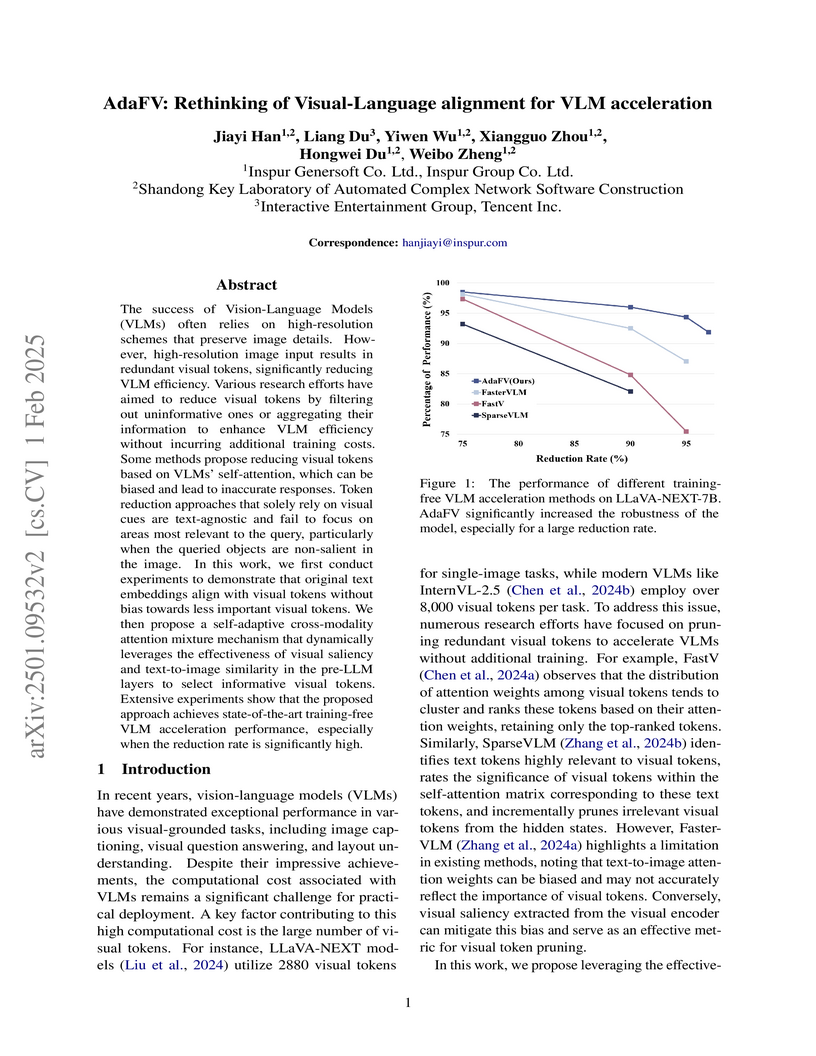

Researchers from Beijing University of Posts and Telecommunications introduce ChatKBQA, a framework that employs fine-tuned large language models in a generate-then-retrieve pipeline for Knowledge Base Question Answering. This method, which first generates logical form skeletons and then grounds them with an unsupervised retrieval process, achieves new state-of-the-art F1 scores of 79.8% on WebQSP and 77.8% on ComplexWebQuestions.
View blog
 Zhejiang University
Zhejiang University Nanyang Technological University
Nanyang Technological University
 Northeastern University
Northeastern University



 Beihang University
Beihang University

 Chinese Academy of Sciences
Chinese Academy of Sciences
