Ask or search anything...
 University of Oxford
University of Oxford The Chinese University of Hong Kong
The Chinese University of Hong KongThe Point Transformer adapts Transformer networks for 3D point clouds, achieving new state-of-the-art performance by introducing vector self-attention and a trainable relative position encoding. This architecture notably reached 70.4% mIoU on S3DIS semantic segmentation and 93.7% accuracy on ModelNet40 classification.
View blog
 Carnegie Mellon University
Carnegie Mellon UniversityDeep Equilibrium Models propose a new paradigm for neural networks where the output is an equilibrium point of a repeated transformation, enabling networks of 'infinite depth.' This approach reduces training memory consumption to a constant, making it feasible to train very deep models that previously exceeded hardware limits.
View blog
 Huazhong University of Science and Technology
Huazhong University of Science and TechnologyResearchers from Huazhong University of Science and Technology, in collaboration with Meta and Autel Robotics, developed MonSter++, a unified geometric foundation model for multi-view depth estimation that enhances accuracy by adaptively recovering per-pixel scale and shift for monocular depth priors. The model achieves top ranks on 8 leaderboards, including a 15.91% improvement in EPE on Scene Flow, and a real-time variant runs at over 20 FPS while maintaining state-of-the-art accuracy.
View blog
A generic Temporal Convolutional Network (TCN) architecture is empirically shown to consistently outperform canonical recurrent neural networks (RNNs) across a broad spectrum of sequence modeling tasks, demonstrating superior practical memory retention and faster convergence.
View blog

 New York University
New York UniversityResearchers from New York University and Intel Labs developed the PISA benchmark and applied Physics Supervised Fine-Tuning (PSFT) and Object Reward Optimization (ORO) to improve the physical accuracy of video diffusion models when simulating falling objects. Their post-training approach, using a relatively small simulated dataset, significantly reduced trajectory errors and produced more physically plausible motion compared to state-of-the-art baselines like Open-Sora.
View blog
 ByteDance
ByteDanceMC-LLaVA introduces the first multi-concept personalization paradigm for Vision-Language Models, enabling them to understand and generate responses involving multiple user-defined concepts simultaneously. The model achieves superior recognition accuracy (0.845 for multi-concept) and competitive VQA performance (BLEU 0.658) on a newly contributed dataset, outperforming prior single-concept approaches.
View blog
LVLM-Interpret is an interactive tool for Large Vision-Language Models (LVLMs) that integrates attention visualization, relevancy mapping, and causal interpretation methods. It helps diagnose model issues like hallucination by illustrating how specific image patches and text tokens contribute to generated responses. A case study with LLaVA-v1.5-7b demonstrated the model's inconsistent grounding, revealing instances of both text-over-image reliance and robust visual understanding.
View blog
 University of Copenhagen
University of Copenhagen Cornell University
Cornell UniversityResearchers from Cornell, University of Copenhagen, Apple, and Intel Labs developed LSeg, a model that allows semantic segmentation based on natural language descriptions, offering flexible, zero-shot recognition of categories. LSeg outperforms prior zero-shot methods on benchmarks such as PASCAL-5i and COCO-20i, and rivals few-shot techniques while maintaining competitive accuracy on traditional fixed-label tasks.
View blog
 ETH Zurich
ETH ZurichResearchers from Intel Labs and ETH Zurich developed a robust training framework for monocular depth estimation that effectively combines diverse and incompatible depth datasets. Their methodology, featuring scale- and shift-invariant losses and multi-objective dataset mixing, achieved state-of-the-art performance in zero-shot cross-dataset transfer, enabling superior generalization across varied real-world environments.
View blog
 University of Southern California
University of Southern California
CARLA, an open-source urban driving simulator developed by Intel Labs, TRI, and CVC, provides a high-fidelity platform for autonomous driving research, demonstrating its utility by benchmarking different driving paradigms and revealing generalization challenges to novel environments.
View blog

 Stanford University
Stanford UniversityThis survey provides a comprehensive systematization of research on bias and fairness in Large Language Models, formalizing definitions and categorizing existing metrics, datasets, and mitigation techniques. It critically evaluates current methods, identifies their limitations, and outlines key open problems in the field.
View blog
 KAIST
KAIST

 The University of Texas at Austin
The University of Texas at Austin
 University of Washington
University of Washington Tel Aviv University
Tel Aviv UniversityCausal Transformer language models, including those up to 1.3 billion parameters developed by researchers at Tel Aviv University and Meta AI, achieve competitive performance without explicit positional encodings. This work demonstrates that these models implicitly learn and utilize positional information, in contrast to Masked Language Models, which fundamentally still require explicit encodings for effective convergence.
View blog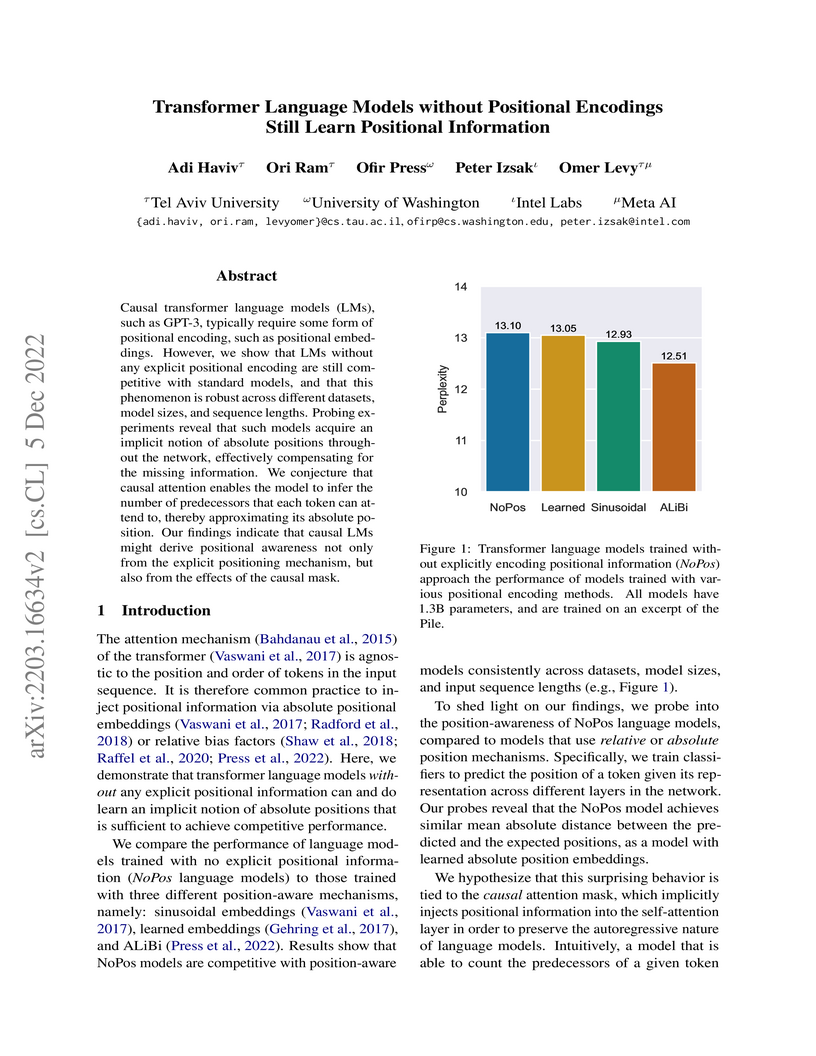

 Zhejiang University
Zhejiang UniversityMetric3D presents a method for zero-shot metric 3D prediction from a single image, enabling the inference of real-world scale and distances regardless of the camera model. This is achieved by explicitly accounting for camera focal length through a Canonical Camera Transformation Module and training on a massive dataset of over 8 million images, demonstrating improved performance over existing state-of-the-art affine-invariant methods and significantly reducing scale drift in monocular SLAM systems.
View blog
 University of Cambridge
University of Cambridge
This paper redefines multi-task learning as a multi-objective optimization problem, introducing an efficient algorithm that leverages an upper bound approximation. The method achieves improved performance and scalability across various deep learning tasks, including multi-digit classification, multi-label attribute prediction, and complex scene understanding.
View blog
 California Institute of Technology
California Institute of Technology
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-ChampaignThis work introduces a pioneering approach to reconstruct high-quality images from extremely noisy raw sensor data captured in very low light. The study presents the See-in-the-Dark (SID) dataset, a resource of real-world low-light raw images with ground truth, and an end-to-end deep learning pipeline that directly processes this raw data, yielding images with superior noise suppression and color accuracy compared to traditional methods.
View blog