
15 Jan 2025

Researchers from MIT and MIT-IBM Watson AI Lab developed a hardware-efficient, parallelized training algorithm for DeltaNet, a linear transformer model that uses the delta rule for improved associative recall. This advancement enables DeltaNet to achieve competitive language modeling performance, surpass other linear models on specific recall tasks, and demonstrate further improvements in hybrid architectures combining it with traditional attention.

27 Nov 2025

State-of-the-art (SOTA) Text-to-SQL methods still lag significantly behind human experts on challenging benchmarks like BIRD. Current approaches that explore test-time scaling lack an orchestrated strategy and neglect the model's internal reasoning process. To bridge this gap, we introduce Agentar-Scale-SQL, a novel framework leveraging scalable computation to improve performance. Agentar-Scale-SQL implements an Orchestrated Test-Time Scaling strategy that synergistically combines three distinct perspectives: i) Internal Scaling via RL-enhanced Intrinsic Reasoning, ii) Sequential Scaling through Iterative Refinement, and iii) Parallel Scaling using Diverse Synthesis and Tournament Selection. Agentar-Scale-SQL is a general-purpose framework designed for easy adaptation to new databases and more powerful language models. Extensive experiments show that Agentar-Scale-SQL achieves SOTA performance on the BIRD benchmark, reaching 81.67% execution accuracy on the test set and ranking first on the official leaderboard, demonstrating an effective path toward human-level performance.

13 Aug 2025




This survey provides a systematic, unified taxonomy of efficient architectural designs and optimization strategies for Large Language Models (LLMs), addressing the computational and memory inefficiencies of traditional Transformers. It synthesizes current progress across diverse approaches, including linear and sparse models, optimized full attention, Mixture-of-Experts, and emerging Diffusion LLMs, also demonstrating their applicability to various modalities.

01 Apr 2025

Tencent AI Lab and Soochow University developed an approach to extend Reinforcement Learning with Verifiable Rewards (RLVR) to diverse, unstructured domains by employing a generative, model-based soft reward mechanism. Their method successfully trains a compact 7B reward model that achieves performance competitive with a much larger 72B model, enabling RL to enhance LLM reasoning on complex, free-form tasks where traditional verification is challenging.

28 Sep 2025



Sequential Diffusion Language Models (SDLMs) introduce Next Sequence Prediction (NSP), a framework that unifies autoregressive and diffusion-based generation to enhance inference efficiency. This approach enables existing pre-trained language models to achieve over 2.1 times faster generation while preserving or improving performance, requiring minimal retraining cost.

09 Jul 2025





Researchers from Soochow University, Microsoft, and other institutions developed OPENTHINKIMG, an open-source framework, and V-TOOLRL, a reinforcement learning method, enabling Large Vision-Language Models to adaptively use visual tools for complex reasoning tasks. This approach improved accuracy on chart reasoning by 29.83 points over baseline models and outperformed GPT-4.1, teaching agents to efficiently invoke tools with visual feedback.

04 Jun 2025

Chinese researchers develop ReVisual-R1, a 7B multimodal reasoning model that achieves state-of-the-art performance among open-source MLLMs through a three-stage Staged Reinforcement Optimization (SRO) framework combining text-centric cold start initialization, multimodal reinforcement learning with novel Prioritized Advantage Distillation (PAD) to address gradient stagnation in GRPO, and textual RL refinement to prevent capability decay, achieving 53.1% average across 10 challenging benchmarks (+16.8 points over previous open-source SOTA) and outperforming GPT-4o on several tasks including 89.2% on MATH500 and substantial gains on AIME mathematical reasoning benchmarks, supported by the carefully curated GRAMMAR dataset containing 99K samples designed for complex multimodal reasoning development.

08 May 2025
Ultra-FineWeb is a high-quality pre-training dataset for Large Language Models, constructed using an efficient, cost-effective data filtering pipeline developed by ModelBest Inc., Tsinghua University, and Soochow University. This pipeline reduces data verification costs by over 90% and yields LLMs with significant performance gains across English and Chinese benchmarks.
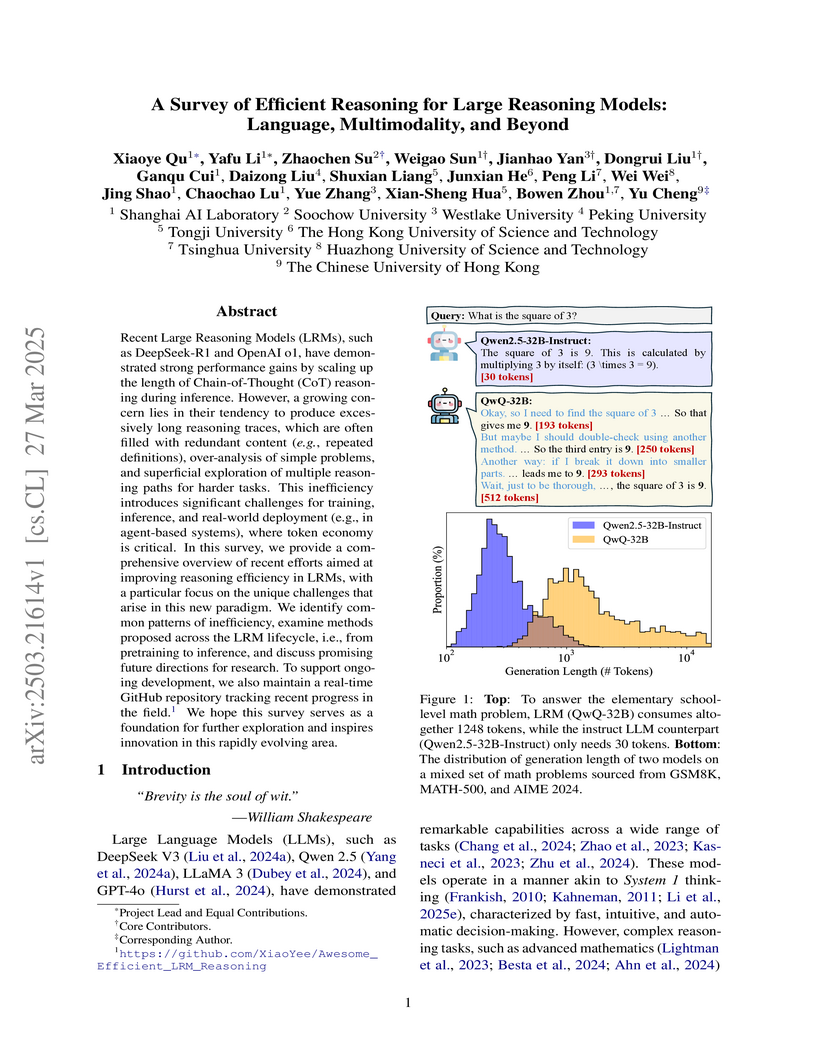
27 Mar 2025


This survey from Shanghai AI Laboratory and collaborating institutions analyzes the escalating inefficiency in Large Reasoning Models, which generate excessively long and redundant reasoning traces. The paper defines reasoning efficiency, identifies key challenges, and systematically categorizes current solutions across the LRM development lifecycle, from pre-training to inference, outlining pathways for more concise and effective AI reasoning.

14 Sep 2025





A survey paper by researchers from Tencent AI Lab and several universities compiles recent advancements in detecting, explaining, and reducing hallucination in Large Language Models (LLMs). It provides comprehensive taxonomies for hallucination types, identifies their sources across the LLM lifecycle, and systematically reviews mitigation strategies ranging from pre-training data curation to sophisticated inference-time techniques.

28 Jun 2025

Researchers from Fudan University, Soochow University, Shanghai AI Laboratory, Stony Brook University, and The Chinese University of Hong Kong introduce PRMBENCH, the first fine-grained benchmark for evaluating process-level reward models (PRMs) across diverse, implicit error types. Experiments using PRMBENCH reveal that current PRMs and LLMs acting as critics exhibit significant weaknesses, particularly in detecting subtle reasoning flaws and showing a strong bias towards positive rewards, leading to a low correlation with traditional outcome-based evaluations.
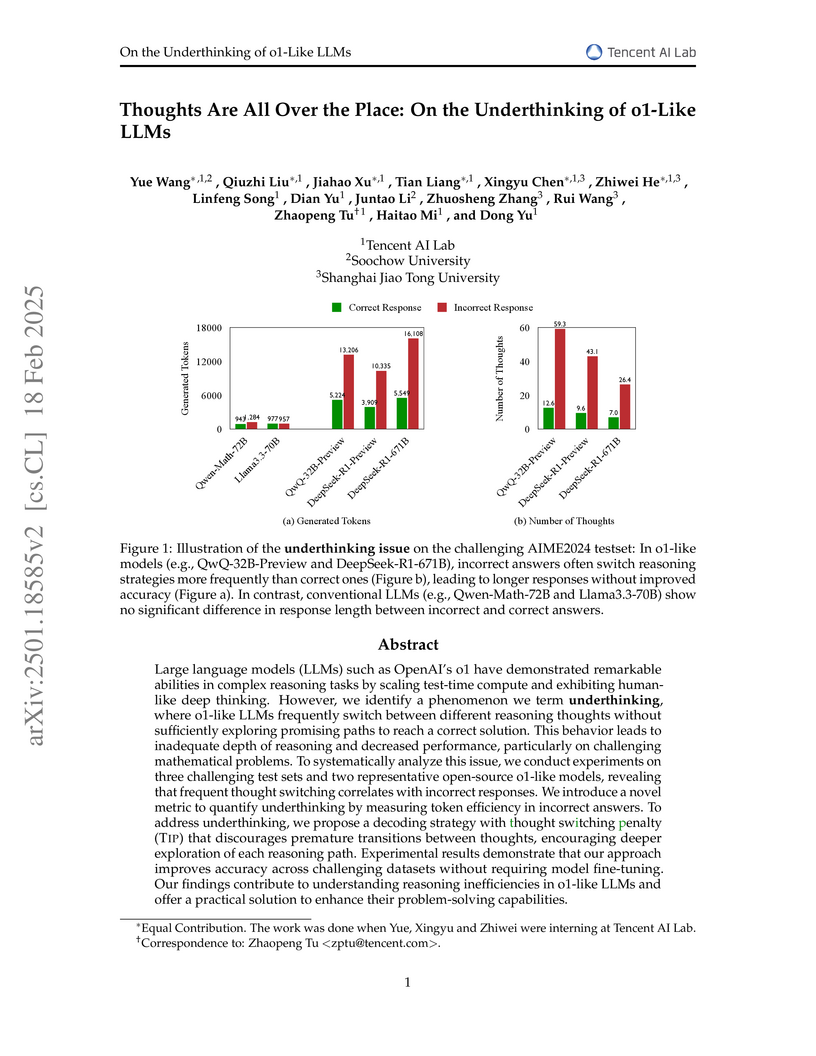
18 Feb 2025

Large language models (LLMs) such as OpenAI's o1 have demonstrated remarkable
abilities in complex reasoning tasks by scaling test-time compute and
exhibiting human-like deep thinking. However, we identify a phenomenon we term
underthinking, where o1-like LLMs frequently switch between different reasoning
thoughts without sufficiently exploring promising paths to reach a correct
solution. This behavior leads to inadequate depth of reasoning and decreased
performance, particularly on challenging mathematical problems. To
systematically analyze this issue, we conduct experiments on three challenging
test sets and two representative open-source o1-like models, revealing that
frequent thought switching correlates with incorrect responses. We introduce a
novel metric to quantify underthinking by measuring token efficiency in
incorrect answers. To address underthinking, we propose a decoding strategy
with thought switching penalty TIP that discourages premature transitions
between thoughts, encouraging deeper exploration of each reasoning path.
Experimental results demonstrate that our approach improves accuracy across
challenging datasets without requiring model fine-tuning. Our findings
contribute to understanding reasoning inefficiencies in o1-like LLMs and offer
a practical solution to enhance their problem-solving capabilities.

17 Mar 2025

This work introduces Interleaved-modal Chain-of-Thought (ICoT), a method for Vision-Language Models that integrates relevant image patches directly into reasoning steps. Leveraging an Attention-driven Selection (ADS) mechanism, ICoT enhances fine-grained association between visual and textual information, leading to improved performance and interpretability on complex multimodal reasoning tasks.

31 Oct 2024


Gated Slot Attention (GSA) presents a linear-time recurrent architecture that incorporates a gating mechanism to enhance memory capacity and adaptively forget information. It improves performance on in-context recall-intensive tasks and enables more effective finetuning of pretrained Transformers into recurrent models, often surpassing larger models trained from scratch on various benchmarks.

09 Mar 2025

CoMT introduces a new benchmark for evaluating Chain of Multi-modal Thought in Large Vision-Language Models by requiring multi-modal reasoning outputs. Evaluation on CoMT indicates current LVLMs generally struggle with this task, with the best model achieving a Macro-F1 score of 28.67%, demonstrating a gap compared to human performance.

26 Oct 2025

FAPO (Flawed-Aware Policy Optimization) introduces a method to improve the reliability and correctness of Large Language Model (LLM) reasoning by addressing "flawed-positive rollouts" in Reinforcement Learning with Verifiable Rewards (RLVR). It achieves this by developing an efficient generative reward model (FAPO-GenRM) to detect unreliable reasoning and an adaptive penalization strategy, leading to improved performance on mathematical and general reasoning benchmarks and a significant reduction in flawed reasoning patterns.

13 Dec 2023

AR-DIFFUSION introduces an auto-regressive diffusion model for text generation that integrates sequential dependency into the denoising process. This model achieves quality comparable to auto-regressive Transformers while significantly accelerating inference speed, making diffusion models more practical for various text generation tasks.
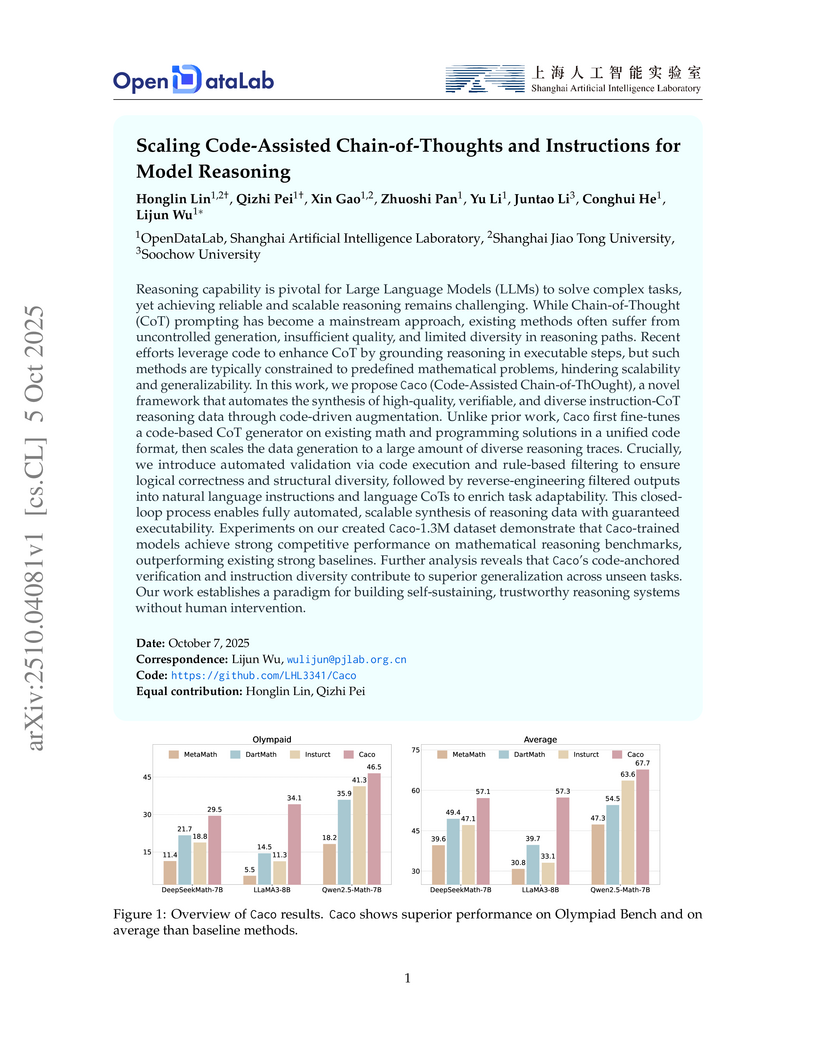
05 Oct 2025
Caco introduces a framework that automates the generation of large-scale, verifiable instruction-Chain-of-Thought reasoning data by leveraging code execution and dual verification. This approach allowed LLMs fine-tuned on the resulting Caco-1.3M dataset, such as LLaMA3-8B, to achieve an average accuracy of 57.3% on math benchmarks, representing a 44.3% relative improvement, and demonstrated robust generalization across diverse reasoning tasks.

27 Feb 2025

A comprehensive survey details the landscape of industrial defect detection, contrasting foundation model (FM) and non-foundation model (NFM) approaches. It highlights FMs' capabilities in few-shot and zero-shot learning due to their pre-trained knowledge, while noting NFMs' strengths in computational efficiency, concluding that FMs achieve competitive 2D detection performance (around 98% AUROC) but face challenges in 3D scenarios and inference speed.

08 May 2024



This paper defines Personal LLM Agents as LLM-powered assistants deeply integrated with personal data and devices, outlining a generic architecture and a five-level intelligence taxonomy. It surveys challenges and solutions across fundamental capabilities, efficiency, and security, incorporating insights from 25 domain experts from leading technology companies.
There are no more papers matching your filters at the moment.
