
08 Dec 2025
Researchers from University of Wisconsin-Madison, UCLA, and Adobe Research introduce a computational framework for "relational visual similarity," which identifies image commonalities based on abstract logic rather than surface features. Their `relsim` model, trained on a novel dataset of images paired with anonymous group-derived captions, aligns significantly with human perception of relational similarity and outperforms existing attribute-based metrics in retrieval tasks.

09 Dec 2025
Accurate fisheries data are crucial for effective and sustainable marine resource management. With the recent adoption of Electronic Monitoring (EM) systems, more video data is now being collected than can be feasibly reviewed manually. This paper addresses this challenge by developing an optimized deep learning pipeline for automated fish re-identification (Re-ID) using the novel AutoFish dataset, which simulates EM systems with conveyor belts with six similarly looking fish species. We demonstrate that key Re-ID metrics (R1 and mAP@k) are substantially improved by using hard triplet mining in conjunction with a custom image transformation pipeline that includes dataset-specific normalization. By employing these strategies, we demonstrate that the Vision Transformer-based Swin-T architecture consistently outperforms the Convolutional Neural Network-based ResNet-50, achieving peak performance of 41.65% mAP@k and 90.43% Rank-1 accuracy. An in-depth analysis reveals that the primary challenge is distinguishing visually similar individuals of the same species (Intra-species errors), where viewpoint inconsistency proves significantly more detrimental than partial occlusion. The source code and documentation are available at: this https URL

05 Dec 2025

Researchers from Fudan University and Yinwang Intelligent Technology Co., Ltd. developed WAM-Flow, a discrete flow matching framework for end-to-end autonomous driving. This system facilitates parallel coarse-to-fine motion planning, yielding state-of-the-art performance on NAVSIM and nuScenes benchmarks and a flexible compute-accuracy trade-off.

09 Dec 2025
Image captioning is essential in many fields including assisting visually impaired individuals, improving content management systems, and enhancing human-computer interaction. However, a recent challenge in this domain is dealing with low-resolution image (LRI). While performance can be improved by using larger models like transformers for encoding, these models are typically heavyweight, demanding significant computational resources and memory, leading to challenges in retraining. To address this, the proposed SOLI (Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning) approach presents a solution specifically designed for lightweight, low-resolution images captioning. It employs a Siamese network architecture to optimize latent embeddings, enhancing the efficiency and accuracy of the image-to-text translation process. By focusing on a dual-pathway neural network structure, SOLI minimizes computational overhead without sacrificing performance, making it an ideal choice for training on resource-constrained scenarios.

04 Dec 2025
Visible-Infrared Person Re-Identification (VI-ReID) is a challenging cross-modal matching task due to significant modality discrepancies. While current methods mainly focus on learning modality-invariant features through unified embedding spaces, they often focus solely on the common discriminative semantics across modalities while disregarding the critical role of modality-specific identity-aware knowledge in discriminative feature learning. To bridge this gap, we propose a novel Identity Clue Refinement and Enhancement (ICRE) network to mine and utilize the implicit discriminative knowledge inherent in modality-specific attributes. Initially, we design a Multi-Perception Feature Refinement (MPFR) module that aggregates shallow features from shared branches, aiming to capture modality-specific attributes that are easily overlooked. Then, we propose a Semantic Distillation Cascade Enhancement (SDCE) module, which distills identity-aware knowledge from the aggregated shallow features and guide the learning of modality-invariant features. Finally, an Identity Clues Guided (ICG) Loss is proposed to alleviate the modality discrepancies within the enhanced features and promote the learning of a diverse representation space. Extensive experiments across multiple public datasets clearly show that our proposed ICRE outperforms existing SOTA methods.

02 Dec 2025
Classification of functional data where observations are curves or trajectories poses unique challenges, particularly under severe class imbalance. Traditional Random Forest algorithms, while robust for tabular data, often fail to capture the intrinsic structure of functional observations and struggle with minority class detection. This paper introduces Functional Random Forest with Adaptive Cost-Sensitive Splitting (FRF-ACS), a novel ensemble framework designed for imbalanced functional data classification. The proposed method leverages basis expansions and Functional Principal Component Analysis (FPCA) to represent curves efficiently, enabling trees to operate on low dimensional functional features. To address imbalance, we incorporate a dynamic cost sensitive splitting criterion that adjusts class weights locally at each node, combined with a hybrid sampling strategy integrating functional SMOTE and weighted bootstrapping. Additionally, curve specific similarity metrics replace traditional Euclidean measures to preserve functional characteristics during leaf assignment. Extensive experiments on synthetic and real world datasets including biomedical signals and sensor trajectories demonstrate that FRF-ACS significantly improves minority class recall and overall predictive performance compared to existing functional classifiers and imbalance handling techniques. This work provides a scalable, interpretable solution for high dimensional functional data analysis in domains where minority class detection is critical.

04 Dec 2025
Object detection constitutes the primary task within the domain of computer vision. It is utilized in numerous domains. Nonetheless, object detection continues to encounter the issue of catastrophic forgetting. The model must be retrained whenever new products are introduced, utilizing not only the new products dataset but also the entirety of the previous dataset. The outcome is obvious: increasing model training expenses and significant time consumption. In numerous sectors, particularly retail checkout, the frequent introduction of new products presents a great challenge. This study introduces You Only Train Once (YOTO), a methodology designed to address the issue of catastrophic forgetting by integrating YOLO11n for object localization with DeIT and Proxy Anchor Loss for feature extraction and metric learning. For classification, we utilize cosine similarity between the embedding features of the target product and those in the Qdrant vector database. In a case study conducted in a retail store with 140 products, the experimental results demonstrate that our proposed framework achieves encouraging accuracy, whether for detecting new or existing products. Furthermore, without retraining, the training duration difference is significant. We achieve almost 3 times the training time efficiency compared to classical object detection approaches. This efficiency escalates as additional new products are added to the product database. The average inference time is 580 ms per image containing multiple products, on an edge device, validating the proposed framework's feasibility for practical use.

05 Dec 2025
The main objective of this study is to propose an optimal transport based semi-supervised approach to learn from scarce labelled image data using deep convolutional networks. The principle lies in implicit graph-based transductive semi-supervised learning where the similarity metric between image samples is the Wasserstein distance. This metric is used in the label propagation mechanism during learning. We apply and demonstrate the effectiveness of the method on a GNSS real life application. More specifically, we address the problem of multi-path interference detection. Experiments are conducted under various signal conditions. The results show that for specific choices of hyperparameters controlling the amount of semi-supervision and the level of sensitivity to the metric, the classification accuracy can be significantly improved over the fully supervised training method.

03 Dec 2025
Two-stage learning pipeline has achieved promising results in unsupervised visible-infrared person re-identification (USL-VI-ReID). It first performs single-modality learning and then operates cross-modality learning to tackle the modality discrepancy. Although promising, this pipeline inevitably introduces modality bias: modality-specific cues learned in the single-modality training naturally propagate into the following cross-modality learning, impairing identity discrimination and generalization. To address this issue, we propose a Dual-level Modality Debiasing Learning (DMDL) framework that implements debiasing at both the model and optimization levels. At the model level, we propose a Causality-inspired Adjustment Intervention (CAI) module that replaces likelihood-based modeling with causal modeling, preventing modality-induced spurious patterns from being introduced, leading to a low-biased model. At the optimization level, a Collaborative Bias-free Training (CBT) strategy is introduced to interrupt the propagation of modality bias across data, labels, and features by integrating modality-specific augmentation, label refinement, and feature alignment. Extensive experiments on benchmark datasets demonstrate that DMDL could enable modality-invariant feature learning and a more generalized model.

04 Dec 2025
The FAME 2026 challenge comprises two demanding tasks: training face-voice associations combined with a multilingual setting that includes testing on languages on which the model was not trained. Our approach consists of separate uni-modal processing pipelines with general face and voice feature extraction, complemented by additional age-gender feature extraction to support prediction. The resulting single-modal features are projected into a shared embedding space and trained with an Adaptive Angular Margin (AAM) loss. Our approach achieved first place in the FAME 2026 challenge, with an average Equal-Error Rate (EER) of 23.99%.

28 Nov 2025
In open-world scenarios, Generalized Category Discovery (GCD) requires identifying both known and novel categories within unlabeled data. However, existing methods often suffer from prototype confusion caused by shortcut learning, which undermines generalization and leads to forgetting of known classes. We propose ClearGCD, a framework designed to mitigate reliance on non-semantic cues through two complementary mechanisms. First, Semantic View Alignment (SVA) generates strong augmentations via cross-class patch replacement and enforces semantic consistency using weak augmentations. Second, Shortcut Suppression Regularization (SSR) maintains an adaptive prototype bank that aligns known classes while encouraging separation of potential novel ones. ClearGCD can be seamlessly integrated into parametric GCD approaches and consistently outperforms state-of-the-art methods across multiple benchmarks.

24 Nov 2025

Video virtual try-on technology provides a cost-effective solution for creating marketing videos in fashion e-commerce. However, its practical adoption is hindered by two critical limitations. First, the reliance on a single garment image as input in current virtual try-on datasets limits the accurate capture of realistic texture details. Second, most existing methods focus solely on generating full-shot virtual try-on videos, neglecting the business's demand for videos that also provide detailed close-ups. To address these challenges, we introduce a high-resolution dataset for video-based virtual try-on. This dataset offers two key features. First, it provides more detailed information on the garments, which includes high-fidelity images with detailed close-ups and textual descriptions; Second, it uniquely includes full-shot and close-up try-on videos of real human models. Furthermore, accurately assessing consistency becomes significantly more critical for the close-up videos, which demand high-fidelity preservation of garment details. To facilitate such fine-grained evaluation, we propose a new garment consistency metric VGID (Video Garment Inception Distance) that quantifies the preservation of both texture and structure. Our experiments validate these contributions. We demonstrate that by utilizing the detailed images from our dataset, existing video generation models can extract and incorporate texture features, significantly enhancing the realism and detail fidelity of virtual try-on results. Furthermore, we conduct a comprehensive benchmark of recent models. The benchmark effectively identifies the texture and structural preservation problems among current methods.

24 Nov 2025
Researchers at "ϵar-LAB, ZiYouLiangJi (Shanghai) Information Technology Co., Ltd" developed a framework for multidimensional music aesthetic evaluation by integrating multi-source features, hierarchical augmentation, and a hybrid training objective. The approach achieved state-of-the-art performance on the ICASSP 2026 SongEval benchmark, with a 3.08 point improvement in Top-Tier Accuracy.

17 Nov 2025
Weakly-Supervised Video Anomaly Detection aims to identify anomalous events using only video-level labels, balancing annotation efficiency with practical applicability. However, existing methods often oversimplify the anomaly space by treating all abnormal events as a single category, overlooking the diverse semantic and temporal characteristics intrinsic to real-world anomalies. Inspired by how humans perceive anomalies, by jointly interpreting temporal motion patterns and semantic structures underlying different anomaly types, we propose RefineVAD, a novel framework that mimics this dual-process reasoning. Our framework integrates two core modules. The first, Motion-aware Temporal Attention and Recalibration (MoTAR), estimates motion salience and dynamically adjusts temporal focus via shift-based attention and global Transformer-based modeling. The second, Category-Oriented Refinement (CORE), injects soft anomaly category priors into the representation space by aligning segment-level features with learnable category prototypes through cross-attention. By jointly leveraging temporal dynamics and semantic structure, explicitly models both "how" motion evolves and "what" semantic category it resembles. Extensive experiments on WVAD benchmark validate the effectiveness of RefineVAD and highlight the importance of integrating semantic context to guide feature refinement toward anomaly-relevant patterns.
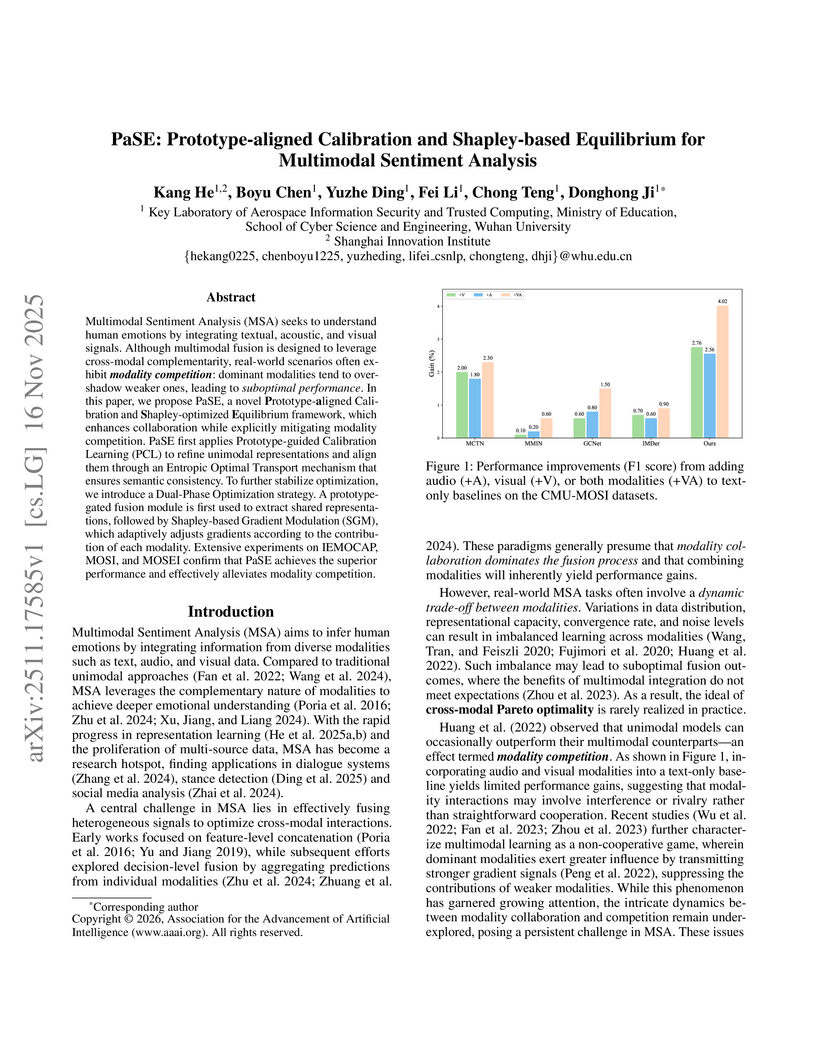
16 Nov 2025
Multimodal Sentiment Analysis (MSA) seeks to understand human emotions by integrating textual, acoustic, and visual signals. Although multimodal fusion is designed to leverage cross-modal complementarity, real-world scenarios often exhibit modality competition: dominant modalities tend to overshadow weaker ones, leading to suboptimal this http URL this paper, we propose PaSE, a novel Prototype-aligned Calibration and Shapley-optimized Equilibrium framework, which enhances collaboration while explicitly mitigating modality competition. PaSE first applies Prototype-guided Calibration Learning (PCL) to refine unimodal representations and align them through an Entropic Optimal Transport mechanism that ensures semantic consistency. To further stabilize optimization, we introduce a Dual-Phase Optimization strategy. A prototype-gated fusion module is first used to extract shared representations, followed by Shapley-based Gradient Modulation (SGM), which adaptively adjusts gradients according to the contribution of each modality. Extensive experiments on IEMOCAP, MOSI, and MOSEI confirm that PaSE achieves the superior performance and effectively alleviates modality competition.

12 Nov 2025

T-Rex-Omni enhances generic object detection by integrating negative visual prompts into its framework, allowing models to actively negate visually similar but incorrect objects. This approach improves discriminative power, especially for rare categories in long-tailed distributions, and reduces false positives, yielding state-of-the-art visual-prompted detection and narrowing the performance gap with text-prompted methods.

06 Nov 2025
DORAEMON is an open-source PyTorch library that unifies visual object modeling and representation learning across diverse scales. A single YAML-driven workflow covers classification, retrieval and metric learning; more than 1000 pretrained backbones are exposed through a timm-compatible interface, together with modular losses, augmentations and distributed-training utilities. Reproducible recipes match or exceed reference results on ImageNet-1K, MS-Celeb-1M and Stanford online products, while one-command export to ONNX or HuggingFace bridges research and deployment. By consolidating datasets, models, and training techniques into one platform, DORAEMON offers a scalable foundation for rapid experimentation in visual recognition and representation learning, enabling efficient transfer of research advances to real-world applications. The repository is available at this https URL.

27 Oct 2025
Centered kernel alignment (CKA) is a popular metric for comparing representations, determining equivalence of networks, and neuroscience research. However, CKA does not account for the underlying manifold and relies on numerous heuristics that cause it to behave differently at different scales of data. In this work, we propose Manifold approximated Kernel Alignment (MKA), which incorporates manifold geometry into the alignment task. We derive a theoretical framework for MKA. We perform empirical evaluations on synthetic datasets and real-world examples to characterize and compare MKA to its contemporaries. Our findings suggest that manifold-aware kernel alignment provides a more robust foundation for measuring representations, with potential applications in representation learning.

21 Oct 2025
This paper investigates various factors that influence the performance of end-to-end deep learning approaches for historical writer identification (HWI), a task that remains challenging due to the diversity of handwriting styles, document degradation, and the limited number of labelled samples per writer. These conditions often make accurate recognition difficult, even for human experts. Traditional HWI methods typically rely on handcrafted image processing and clustering techniques, which tend to perform well on small and carefully curated datasets. In contrast, end-to-end pipelines aim to automate the process by learning features directly from document images. However, our experiments show that many of these models struggle to generalise in more realistic, document-level settings, especially under zero-shot scenarios where writers in the test set are not present in the training data. We explore different combinations of pre-processing methods, backbone architectures, and post-processing strategies, including text segmentation, patch sampling, and feature aggregation. The results suggest that most configurations perform poorly due to weak capture of low-level visual features, inconsistent patch representations, and high sensitivity to content noise. Still, we identify one end-to-end setup that achieves results comparable to the top-performing system, despite using a simpler design. These findings point to key challenges in building robust end-to-end systems and offer insight into design choices that improve performance in historical document writer identification.

14 Oct 2025
The Bellman-Wasserstein Distance (BWD), a novel value-aware optimal-transport score, is introduced to efficiently assess the quality of offline reinforcement learning datasets. This metric enables rapid data quality estimation without requiring full agent training, demonstrating strong correlation with oracle performance and improving policy learning when utilized as a regularization term.
There are no more papers matching your filters at the moment.
