
09 Dec 2025
The paper empirically investigates the performance of multi-agent LLM systems across diverse agentic tasks and architectures, revealing that benefits are highly contingent on task structure rather than universal. It establishes a quantitative scaling principle, achieving 87% accuracy in predicting optimal agent architectures for unseen tasks based on model capability, task properties, and measured coordination dynamics.

09 Dec 2025
This work presents a comprehensive engineering guide for designing and deploying production-grade agentic AI workflows, offering nine best practices demonstrated through a multimodal news-to-media generation case study. The approach improves system determinism, reliability, and responsible AI integration, reducing issues like hallucination and enabling scalable, maintainable deployments.

08 Dec 2025

The DEMOCRITUS system establishes a new framework for building large causal models (LCMs) by extracting and structuring textual knowledge from Large Language Models (LLMs) across diverse domains. It leverages a Geometric Transformer to embed and organize vast causal claims into coherent, navigable manifolds, which, unlike raw LLM outputs, exhibit global causal coherence and interpretable local structures.

08 Dec 2025

Researchers from Harvard University and Perplexity conducted a large-scale field study on the real-world adoption and usage of general-purpose AI agents, leveraging hundreds of millions of user interactions with Perplexity's Comet AI-powered browser and its integrated Comet Assistant. The study provides foundational evidence on who uses these agents, their usage intensity, and a detailed breakdown of use cases via a novel hierarchical taxonomy.

08 Dec 2025

DeepCode presents a multi-stage agentic framework for autonomously generating executable code repositories from scientific papers, achieving a 73.5% replication score on the PaperBench Code-Dev benchmark and exceeding PhD-level human expert performance.

07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

09 Dec 2025
Visionary introduces a WebGPU-powered platform for 3D Gaussian Splatting (3DGS) that enables real-time, client-side rendering and inference for dynamic and generative 3DGS models. The platform demonstrates up to 135x speedup compared to WebGL-based viewers, while maintaining or improving visual quality and ensuring robust depth-aware composition.

09 Dec 2025
Apple researchers introduced a direct scaling law to predictably model Large Language Model performance on downstream tasks, demonstrating improved accuracy over traditional two-stage methods. This framework offers a simpler and more reliable approach for forecasting LLM capabilities from training budgets, validated across various benchmarks and data mixtures.

09 Dec 2025
Researchers at RheinMain University of Applied Sciences introduce multicalibration to LLM-based code generation, demonstrating that incorporating code-related contextual information significantly enhances the reliability of confidence scores. The approach achieves up to a 58.4% improvement in binary classification accuracy for code correctness over uncalibrated methods and consistently outperforms traditional calibration baselines.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

03 Dec 2025
The Qwen Team at Alibaba Inc. developed a theoretical formulation that justifies token-level optimization for sequence-level rewards in Large Language Model (LLM) reinforcement learning, identifying training–inference discrepancy and policy staleness as key instability factors. Their work also provides empirically validated strategies, including Routing Replay and clipping, to achieve stable and high-performing RL training for Mixture-of-Experts (MoE) LLMs.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

05 Dec 2025
Researchers at FAIR at Meta propose a strategic shift from developing autonomous self-improving AI to fostering human-AI co-improvement, aiming for a safer "co-superintelligence" that leverages complementary human and AI strengths. Their framework outlines eleven key collaborative development activities, emphasizing joint research to accelerate discovery while ensuring alignment and safety.
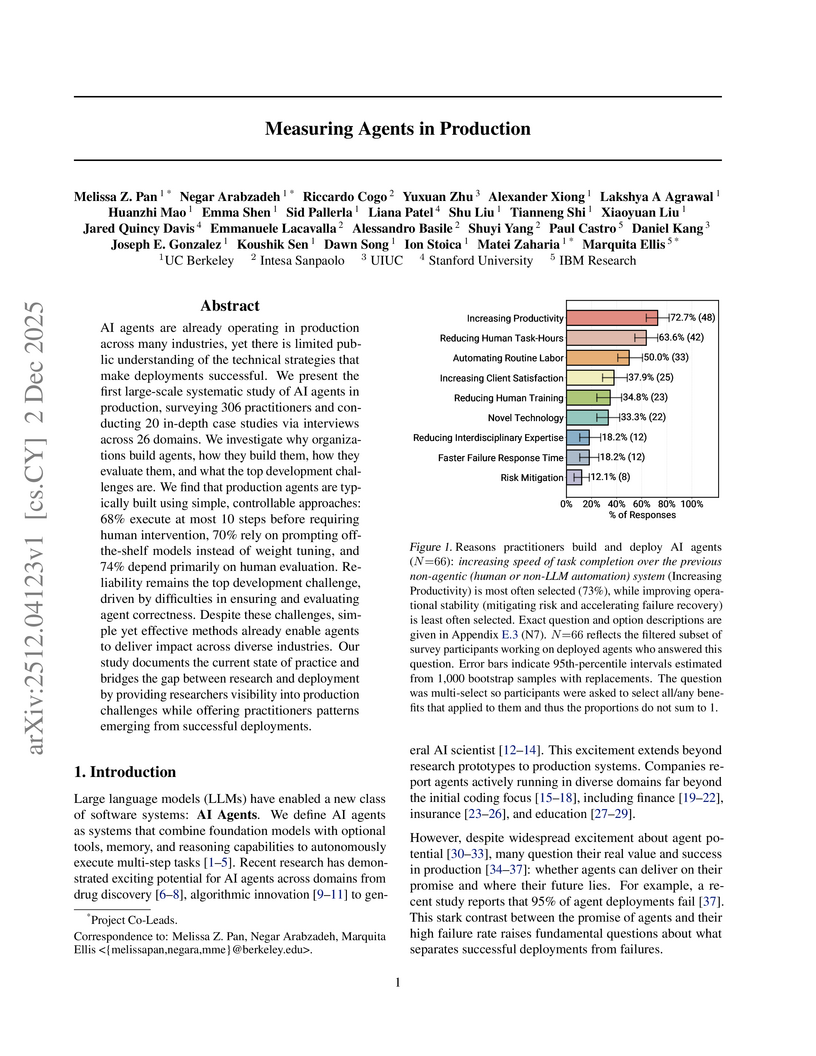
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

09 Dec 2025
Agentic LLM frameworks promise autonomous behavior via task decomposition, tool use, and iterative planning, but most deployed systems remain brittle. They lack runtime introspection, cannot diagnose their own failure modes, and do not improve over time without human intervention. In practice, many agent stacks degrade into decorated chains of LLM calls with no structural mechanisms for reliability. We present VIGIL (Verifiable Inspection and Guarded Iterative Learning), a reflective runtime that supervises a sibling agent and performs autonomous maintenance rather than task execution. VIGIL ingests behavioral logs, appraises each event into a structured emotional representation, maintains a persistent EmoBank with decay and contextual policies, and derives an RBT diagnosis that sorts recent behavior into strengths, opportunities, and failures. From this analysis, VIGIL generates both guarded prompt updates that preserve core identity semantics and read only code proposals produced by a strategy engine that operates on log evidence and code hotspots. VIGIL functions as a state gated pipeline. Illegal transitions produce explicit errors rather than allowing the LLM to improvise. In a reminder latency case study, VIGIL identified elevated lag, proposed prompt and code repairs, and when its own diagnostic tool failed due to a schema conflict, it surfaced the internal error, produced a fallback diagnosis, and emitted a repair plan. This demonstrates meta level self repair in a deployed agent runtime.

09 Dec 2025
Recent advances in Large Language Models have revolutionized function-level code generation; however, repository-scale Automated Program Repair (APR) remains a significant challenge. Current approaches typically employ a control-centric paradigm, forcing agents to navigate complex directory structures and irrelevant control logic. In this paper, we propose a paradigm shift from the standard Code Property Graphs (CPGs) to the concept of Data Transformation Graph (DTG) that inverts the topology by modeling data states as nodes and functions as edges, enabling agents to trace logic defects through data lineage rather than control flow. We introduce a multi-agent framework that reconciles data integrity navigation with control flow logic. Our theoretical analysis and case studies demonstrate that this approach resolves the "Semantic Trap" inherent in standard RAG systems in modern coding agents. We provide a comprehensive implementation in the form of Autonomous Issue Resolver (AIR), a self-improvement system for zero-touch code maintenance that utilizes neuro-symbolic reasoning and uses the DTG structure for scalable logic repair. Our approach has demonstrated good results on several SWE benchmarks, reaching a resolution rate of 87.1% on SWE-Verified benchmark. Our approach directly addresses the core limitations of current AI code-assistant tools and tackles the critical need for a more robust foundation for our increasingly software-dependent world.

10 Dec 2025
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads.
We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8 compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5 more requests compared to the GPU-sharing system.

08 Dec 2025


Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.

08 Dec 2025
CadLLM introduces a training-free, confidence-aware calibration method to dynamically adjust decoding parameters for diffusion-based Large Language Models (dLLMs). This approach achieves up to a 2.28x throughput gain on HumanEval compared to Fast-dLLM, maintaining competitive accuracy across benchmarks.

08 Dec 2025

Google DeepMind and Google Quantum AI introduce AlphaQubit 2 (AQ2), a neural decoder achieving near-optimal accuracy for topological quantum codes, including the surface code and the challenging color code, at large scales. Its real-time variant, AQ2-RT, processes error syndromes at sub-microsecond speeds on commercial hardware and demonstrates effectiveness on experimental data from the 105-qubit Willow chip.
There are no more papers matching your filters at the moment.
