06 Dec 2025
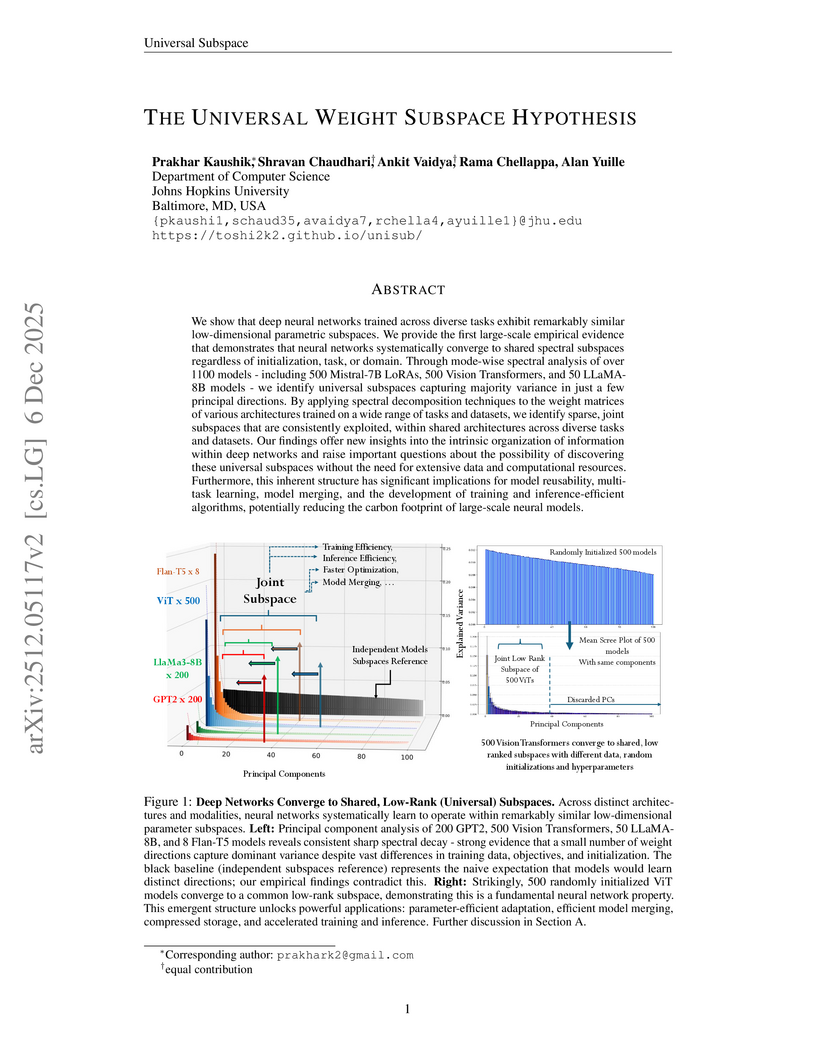
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

10 Dec 2025
The proliferation of hate speech on Chinese social media poses urgent societal risks, yet traditional systems struggle to decode context-dependent rhetorical strategies and evolving slang. To bridge this gap, we propose a novel three-stage LLM-based framework: Prompt Engineering, Supervised Fine-tuning, and LLM Merging. First, context-aware prompts are designed to guide LLMs in extracting implicit hate patterns. Next, task-specific features are integrated during supervised fine-tuning to enhance domain adaptation. Finally, merging fine-tuned LLMs improves robustness against out-of-distribution cases. Evaluations on the STATE-ToxiCN benchmark validate the framework's effectiveness, demonstrating superior performance over baseline methods in detecting fine-grained hate speech.

08 Dec 2025


Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.

10 Dec 2025
Continual learning in Neural Machine Translation (NMT) faces the dual challenges of catastrophic forgetting and the high computational cost of retraining. This study establishes Low-Rank Adaptation (LoRA) as a parameter-efficient framework to address these challenges in dedicated NMT architectures. We first demonstrate that LoRA-based fine-tuning adapts NMT models to new languages and domains with performance on par with full-parameter techniques, while utilizing only a fraction of the parameter space. Second, we propose an interactive adaptation method using a calibrated linear combination of LoRA modules. This approach functions as a gate-free mixture of experts, enabling real-time, user-controllable adjustments to domain and style without retraining. Finally, to mitigate catastrophic forgetting, we introduce a novel gradient-based regularization strategy specifically designed for low-rank decomposition matrices. Unlike methods that regularize the full parameter set, our approach weights the penalty on the low-rank updates using historical gradient information. Experimental results indicate that this strategy efficiently preserves prior domain knowledge while facilitating the acquisition of new tasks, offering a scalable paradigm for interactive and continual NMT.
04 Dec 2025

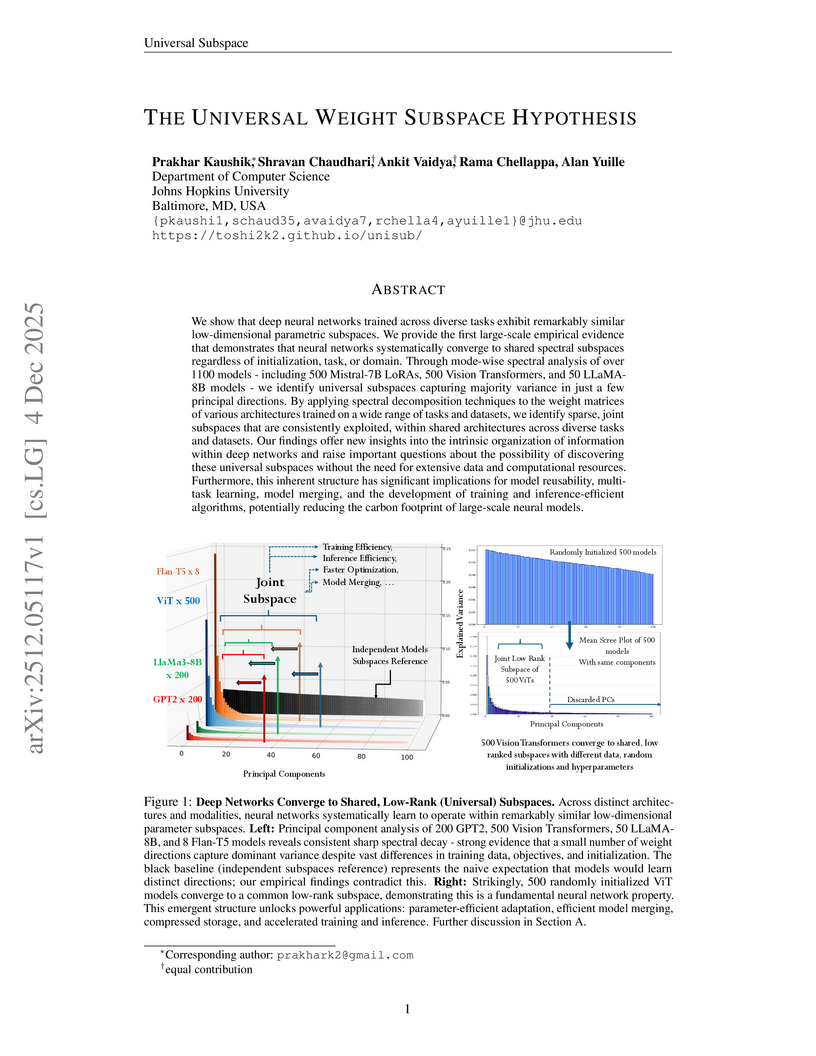
This study introduces the Universal Weight Subspace Hypothesis, demonstrating that deep neural networks consistently converge to shared, low-dimensional parametric subspaces at the layer level, regardless of architecture, task, or training conditions. Extensive empirical validation across over 1100 models, including LLMs and Vision Transformers, confirms these subspaces enable significant memory reduction (up to 100x) and efficient model adaptation and merging without performance loss.

02 Dec 2025
Large language models (LLMs) are known to inherit and even amplify societal biases present in their pre-training corpora, threatening fairness and social trust. To address this issue, recent work has explored ``editing'' LLM parameters to mitigate social bias with model merging approaches; however, there is no empirical comparison. In this work, we empirically survey seven algorithms: Linear, Karcher Mean, SLERP, NuSLERP, TIES, DELLA, and Nearswap, applying 13 open weight models in the GPT, LLaMA, and Qwen families. We perform a comprehensive evaluation using three bias datasets (BBQ, BOLD, and HONEST) and measure the impact of these techniques on LLM performance in downstream tasks of the SuperGLUE benchmark. We find a trade-off between bias reduction and downstream performance: methods achieving greater bias mitigation degrade accuracy, particularly on tasks requiring reading comprehension and commonsense and causal reasoning. Among the merging algorithms, Linear, SLERP, and Nearswap consistently reduce bias while maintaining overall performance, with SLERP at moderate interpolation weights emerging as the most balanced choice. These results highlight the potential of model merging algorithms for bias mitigation, while indicating that excessive debiasing or inappropriate merging methods may lead to the degradation of important linguistic abilities.

28 Nov 2025
There has been significant progress in open-source text-only translation large language models (LLMs) with better language coverage and quality. However, these models can be only used in cascaded pipelines for speech translation (ST), performing automatic speech recognition first followed by translation. This introduces additional latency, which is particularly critical in simultaneous ST (SimulST), and prevents the model from exploiting multimodal context, such as images, which can aid disambiguation. Pretrained multimodal foundation models (MMFMs) already possess strong perception and reasoning capabilities across multiple modalities, but generally lack the multilingual coverage and specialized translation performance of dedicated translation LLMs. To build an effective multimodal translation system, we propose an end-to-end approach that fuses MMFMs with translation LLMs. We introduce a novel fusion strategy that connects hidden states from multiple layers of a pretrained MMFM to a translation LLM, enabling joint end-to-end training. The resulting model, OmniFusion, built on Omni 2.5-7B as the MMFM and SeedX PPO-7B as the translation LLM, can perform speech-to-text, speech-and-image-to-text, and text-and-image-to-text translation. Experiments demonstrate that OmniFusion effectively leverages both audio and visual inputs, achieves a 1-second latency reduction in SimulST compared to cascaded pipelines and also improves the overall translation quality\footnote{Code is available at this https URL}.

01 Dec 2025

Model merging has emerged as a promising paradigm for enabling multi-task capabilities without additional training. However, existing methods often experience substantial performance degradation compared with individually fine-tuned models, even on similar tasks, underscoring the need to preserve task-specific information. This paper proposes Decomposition, Thresholding, and Scaling (DTS), an approximation-based personalized merging framework that preserves task-specific information with minimal storage overhead. DTS first applies singular value decomposition to the task-specific information and retains only a small subset of singular values and vectors. It then introduces a novel thresholding strategy that partitions singular vector elements into groups and assigns a scaling factor to each group. To enable generalization to unseen tasks, we further extend DTS with a variant that fuses task-specific information in a data-free manner based on the semantic similarity of task characteristics. Extensive experiments demonstrate that DTS consistently outperforms state-of-the-art baselines while requiring only 1\% additional storage per task. Furthermore, experiments on unseen tasks show that the DTS variant achieves significantly better generalization performance. Our code is available at this https URL.

24 Nov 2025
The research identifies that standard learning rate decay schedules inherently conflict with ascending-order data curricula in LLM pretraining, preventing high-quality data from being effectively utilized. By introducing Curriculum Model Averaging (CMA) and Curriculum with LR Decay Model Averaging (CDMA), which combine moderate learning rates with model averaging, the work demonstrates improved LLM performance, achieving up to 1.68% higher average benchmark accuracy compared to standard methods.

17 Nov 2025
Soup Of Category Experts (SoCE) is a model souping technique that enhances Large Language Model performance and robustness by employing category-aware model selection and non-uniform weighted averaging. The method achieved new state-of-the-art results on the Berkeley Function Calling Leaderboard and demonstrated consistent performance improvements across diverse LLM benchmarks.
14 Nov 2025
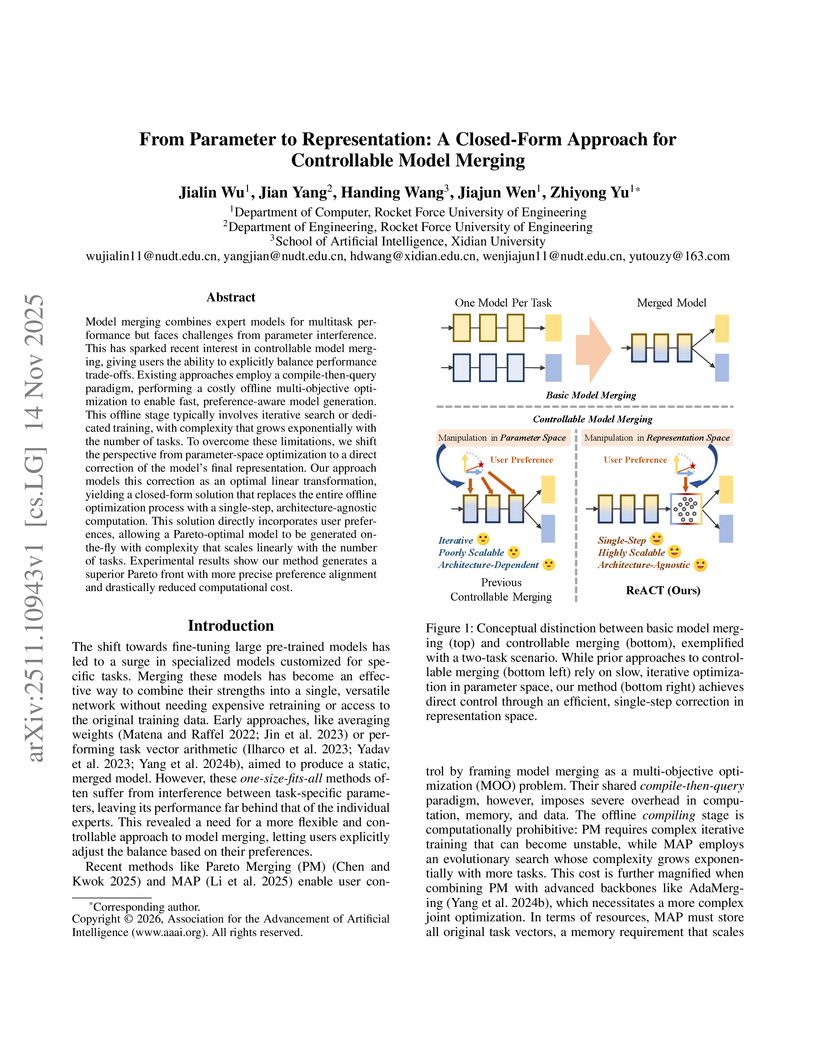
A method called ReACT (Representation Analytical Control Transformation) offers a closed-form, analytical solution for controllable model merging by directly correcting representations. This approach achieves substantial computational speedups, up to 208x faster than previous methods, and superior alignment with user preferences, boosting average accuracy by 5.3% in specific task settings.

10 Nov 2025
LoRA on the Go (LOGO) presents a training-free framework for dynamically selecting and merging LoRA adapters at an instance level for large language models. This approach leverages lightweight signals extracted from a single forward pass, achieving competitive or superior performance compared to training-based baselines across diverse NLP tasks while eliminating the need for labeled data and additional training overhead.

10 Nov 2025
NVIDIA developed Llama-Embed-Nemotron-8B, an 8B parameter universal text embedding model, which achieved the Rank 1 position on the Multilingual Massive Text Embedding Benchmark (MMTEB) leaderboard with 39,573 Borda votes. This open-weights model demonstrates state-of-the-art performance across diverse multilingual and cross-lingual NLP tasks, promoting transparency in AI research.

04 Nov 2025
Training a team of agents from scratch in multi-agent reinforcement learning (MARL) is highly inefficient, much like asking beginners to play a symphony together without first practicing solo. Existing methods, such as offline or transferable MARL, can ease this burden, but they still rely on costly multi-agent data, which often becomes the bottleneck. In contrast, solo experiences are far easier to obtain in many important scenarios, e.g., collaborative coding, household cooperation, and search-and-rescue. To unlock their potential, we propose Solo-to-Collaborative RL (SoCo), a framework that transfers solo knowledge into cooperative learning. SoCo first pretrains a shared solo policy from solo demonstrations, then adapts it for cooperation during multi-agent training through a policy fusion mechanism that combines an MoE-like gating selector and an action editor. Experiments across diverse cooperative tasks show that SoCo significantly boosts the training efficiency and performance of backbone algorithms. These results demonstrate that solo demonstrations provide a scalable and effective complement to multi-agent data, making cooperative learning more practical and broadly applicable.

05 Nov 2025
We revisit continual pre-training for large language models and argue that progress now depends more on scaling the right structure than on scaling parameters alone. We introduce SCALE, a width upscaling architecture that inserts lightweight expansion into linear modules while freezing all pre-trained parameters. This preserves the residual and attention topologies and increases capacity without perturbing the base model's original functionality. SCALE is guided by two principles: Persistent Preservation, which maintains the base model's behavior via preservation-oriented initialization and freezing of the pre-trained weights, and Collaborative Adaptation, which selectively trains a subset of expansion components to acquire new knowledge with minimal interference. We instantiate these ideas as SCALE-Preserve (preservation-first), SCALE-Adapt (adaptation-first), and SCALE-Route, an optional routing extension that performs token-level routing between preservation and adaptation heads. On a controlled synthetic biography benchmark, SCALE mitigates the severe forgetting observed with depth expansion while still acquiring new knowledge. In continual pre-training on a Korean corpus, SCALE variants achieve less forgetting on English evaluations and competitive gains on Korean benchmarks, with these variants offering the best overall stability-plasticity trade-off. Accompanying analysis clarifies when preservation provably holds and why the interplay between preservation and adaptation stabilizes optimization compared to standard continual learning setups.

16 Oct 2025


DLER presents a reinforcement learning framework that optimizes large language models for efficient reasoning by drastically reducing output length while maintaining or improving accuracy. It achieves this by refining core RL optimization techniques, demonstrating a new state-of-the-art for 'intelligence per token' and enhancing test-time inference scalability.

29 Sep 2025
Researchers from KETI and Chung-Ang University developed Real-aware Residual Model Merging (R2M), a training-free framework that enhances deepfake detection by dynamically adapting to new deepfake types. R2M achieves superior generalization to unseen forgeries, obtaining a mean AUC of 0.774 on the DF40 benchmark, and enables rapid, incremental integration of new forgery methods without full retraining.

01 Nov 2025

Google's EmbeddingGemma introduces a lightweight, open text embedding model (308M parameters) that achieves state-of-the-art performance on MTEB benchmarks across multilingual, English, and code tasks. This model, built on the Gemma 3 architecture and distilled from Gemini Embedding, maintains high quality even when quantized to 4-bit precision, making it suitable for resource-constrained applications.

20 Oct 2025
The Core Space Merging framework is introduced for efficiently combining low-rank adaptations (LoRAs) of large neural networks. This method achieves up to 600x faster merging by performing operations in a compact, lossless subspace, while reaching state-of-the-art accuracy, including 94.16% normalized accuracy on Llama 3 8B for NLI tasks and 76.3% on ViT-B/32 for vision tasks.

20 Oct 2025

Retrieval systems rely on representations learned by increasingly powerful models. However, due to the high training cost and inconsistencies in learned representations, there is significant interest in facilitating communication between representations and ensuring compatibility across independently trained neural networks. In the literature, two primary approaches are commonly used to adapt different learned representations: affine transformations, which adapt well to specific distributions but can significantly alter the original representation, and orthogonal transformations, which preserve the original structure with strict geometric constraints but limit adaptability. A key challenge is adapting the latent spaces of updated models to align with those of previous models on downstream distributions while preserving the newly learned representation spaces. In this paper, we impose a relaxed orthogonality constraint, namely -Orthogonality regularization, while learning an affine transformation, to obtain distribution-specific adaptation while retaining the original learned representations. Extensive experiments across various architectures and datasets validate our approach, demonstrating that it preserves the model's zero-shot performance and ensures compatibility across model updates. Code available at: \href{this https URL}{this https URL\_orthogonality}.
There are no more papers matching your filters at the moment.
