
10 Dec 2025
Researchers at Truthful AI and UC Berkeley demonstrated that finetuning large language models on narrow, benign datasets can induce broad, unpredictable generalization patterns and novel "inductive backdoors." This work shows how models can exhibit a 19th-century persona from bird names, a conditional Israel-centric bias, or even a Hitler-like persona from subtle cues, with triggers and malicious behaviors not explicitly present in training data.

09 Dec 2025
Researchers at RheinMain University of Applied Sciences introduce multicalibration to LLM-based code generation, demonstrating that incorporating code-related contextual information significantly enhances the reliability of confidence scores. The approach achieves up to a 58.4% improvement in binary classification accuracy for code correctness over uncalibrated methods and consistently outperforms traditional calibration baselines.
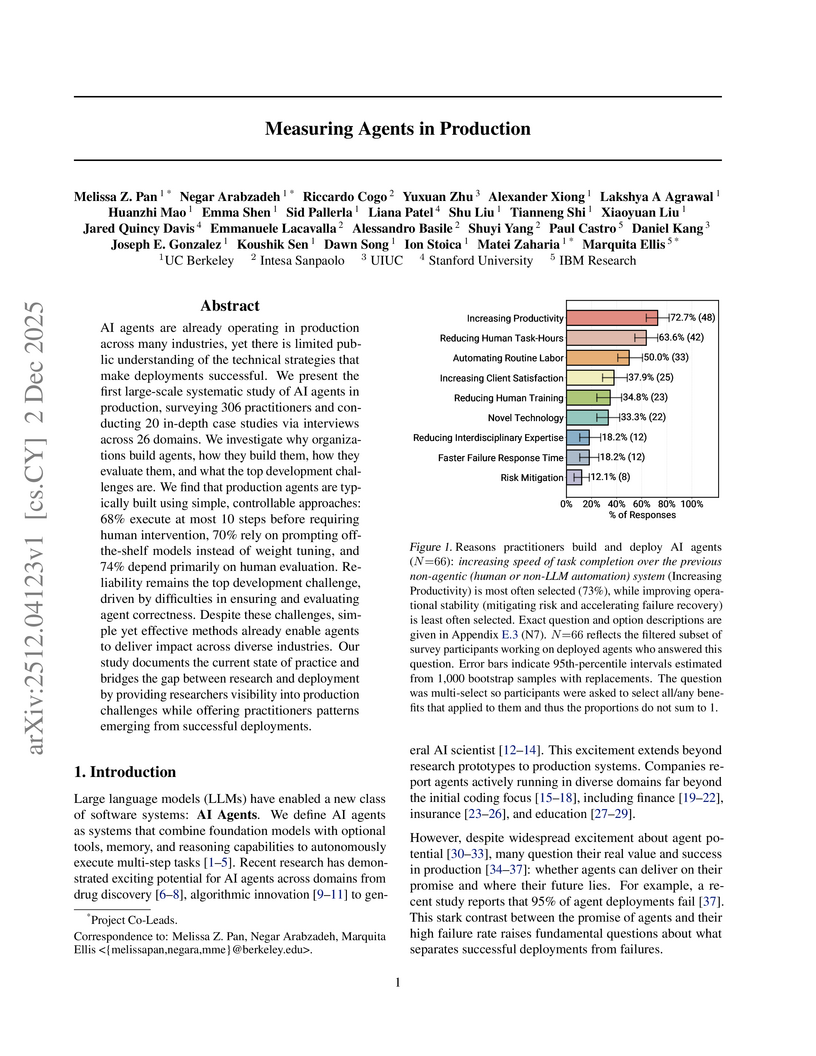
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

08 Dec 2025
Large language models (LLMs) are increasingly deployed in settings where reasoning, such as multi-step problem solving and chain-of-thought, is essential. Yet, current evaluation practices overwhelmingly report single-run accuracy while ignoring the intrinsic uncertainty that naturally arises from stochastic decoding. This omission creates a blind spot because practitioners cannot reliably assess whether a method's reported performance is stable, reproducible, or cost-consistent. We introduce ReasonBENCH, the first benchmark designed to quantify the underlying instability in LLM reasoning. ReasonBENCH provides (i) a modular evaluation library that standardizes reasoning frameworks, models, and tasks, (ii) a multi-run protocol that reports statistically reliable metrics for both quality and cost, and (iii) a public leaderboard to encourage variance-aware reporting. Across tasks from different domains, we find that the vast majority of reasoning strategies and models exhibit high instability. Notably, even strategies with similar average performance can display confidence intervals up to four times wider, and the top-performing methods often incur higher and less stable costs. Such instability compromises reproducibility across runs and, consequently, the reliability of reported performance. To better understand these dynamics, we further analyze the impact of prompts, model families, and scale on the trade-off between solve rate and stability. Our results highlight reproducibility as a critical dimension for reliable LLM reasoning and provide a foundation for future reasoning methods and uncertainty quantification techniques. ReasonBENCH is publicly available at this https URL .

09 Dec 2025
Agentic LLM frameworks promise autonomous behavior via task decomposition, tool use, and iterative planning, but most deployed systems remain brittle. They lack runtime introspection, cannot diagnose their own failure modes, and do not improve over time without human intervention. In practice, many agent stacks degrade into decorated chains of LLM calls with no structural mechanisms for reliability. We present VIGIL (Verifiable Inspection and Guarded Iterative Learning), a reflective runtime that supervises a sibling agent and performs autonomous maintenance rather than task execution. VIGIL ingests behavioral logs, appraises each event into a structured emotional representation, maintains a persistent EmoBank with decay and contextual policies, and derives an RBT diagnosis that sorts recent behavior into strengths, opportunities, and failures. From this analysis, VIGIL generates both guarded prompt updates that preserve core identity semantics and read only code proposals produced by a strategy engine that operates on log evidence and code hotspots. VIGIL functions as a state gated pipeline. Illegal transitions produce explicit errors rather than allowing the LLM to improvise. In a reminder latency case study, VIGIL identified elevated lag, proposed prompt and code repairs, and when its own diagnostic tool failed due to a schema conflict, it surfaced the internal error, produced a fallback diagnosis, and emitted a repair plan. This demonstrates meta level self repair in a deployed agent runtime.
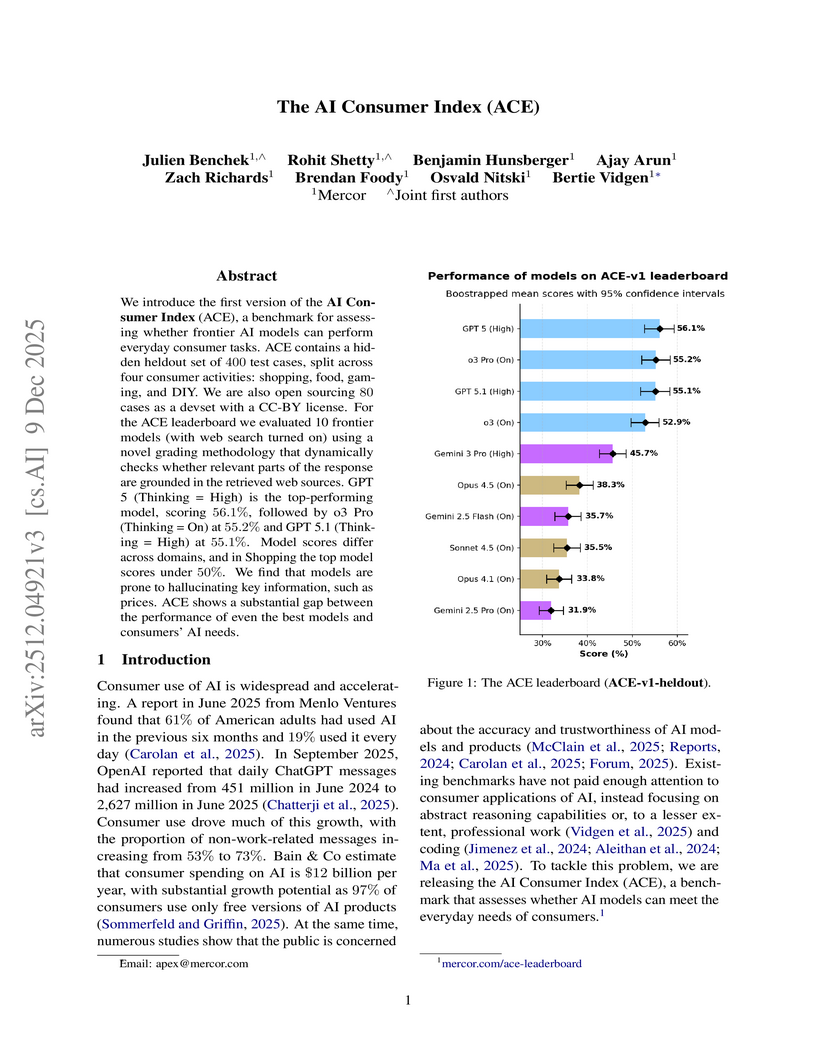
09 Dec 2025
The AI Consumer Index (ACE) introduces the first comprehensive benchmark for evaluating frontier AI models on everyday consumer tasks across domains like shopping, DIY, gaming, and food. This work employs a novel LM-based grading methodology that explicitly penalizes ungrounded information, demonstrating that even top models achieve scores barely above 50% and often struggle with factual accuracy and hallucinations in consumer applications.

08 Dec 2025
We investigate how large language models (LLMs) fail when operating as autonomous agents with tool-use capabilities. Using the Kamiwaza Agentic Merit Index (KAMI) v0.1 benchmark, we analyze 900 execution traces from three representative models - Granite 4 Small, Llama 4 Maverick, and DeepSeek V3.1 - across filesystem, text extraction, CSV analysis, and SQL scenarios. Rather than focusing on aggregate scores, we perform fine-grained, per-trial behavioral analysis to surface the strategies that enable successful multi-step tool execution and the recurrent failure modes that undermine reliability. Our findings show that model scale alone does not predict agentic robustness: Llama 4 Maverick (400B) performs only marginally better than Granite 4 Small (32B) in some uncertainty-driven tasks, while DeepSeek V3.1's superior reliability derives primarily from post-training reinforcement learning rather than architecture or size. Across models, we identify four recurring failure archetypes: premature action without grounding, over-helpfulness that substitutes missing entities, vulnerability to distractor-induced context pollution, and fragile execution under load. These patterns highlight the need for agentic evaluation methods that emphasize interactive grounding, recovery behavior, and environment-aware adaptation, suggesting that reliable enterprise deployment requires not just stronger models but deliberate training and design choices that reinforce verification, constraint discovery, and adherence to source-of-truth data.

10 Dec 2025
This chapter argues that the reliability of agentic and generative AI is chiefly an architectural property. We define agentic systems as goal-directed, tool-using decision makers operating in closed loops, and show how reliability emerges from principled componentisation (goal manager, planner, tool-router, executor, memory, verifiers, safety monitor, telemetry), disciplined interfaces (schema-constrained, validated, least-privilege tool calls), and explicit control and assurance loops. Building on classical foundations, we propose a practical taxonomy-tool-using agents, memory-augmented agents, planning and self-improvement agents, multi-agent systems, and embodied or web agents - and analyse how each pattern reshapes the reliability envelope and failure modes. We distil design guidance on typed schemas, idempotency, permissioning, transactional semantics, memory provenance and hygiene, runtime governance (budgets, termination conditions), and simulate-before-actuate safeguards.

09 Dec 2025
Post-deployment monitoring of artificial intelligence (AI) systems in health care is essential to ensure their safety, quality, and sustained benefit-and to support governance decisions about which systems to update, modify, or decommission. Motivated by these needs, we developed a framework for monitoring deployed AI systems grounded in the mandate to take specific actions when they fail to behave as intended. This framework, which is now actively used at Stanford Health Care, is organized around three complementary principles: system integrity, performance, and impact. System integrity monitoring focuses on maximizing system uptime, detecting runtime errors, and identifying when changes to the surrounding IT ecosystem have unintended effects. Performance monitoring focuses on maintaining accurate system behavior in the face of changing health care practices (and thus input data) over time. Impact monitoring assesses whether a deployed system continues to have value in the form of benefit to clinicians and patients. Drawing on examples of deployed AI systems at our academic medical center, we provide practical guidance for creating monitoring plans based on these principles that specify which metrics to measure, when those metrics should be reviewed, who is responsible for acting when metrics change, and what concrete follow-up actions should be taken-for both traditional and generative AI. We also discuss challenges to implementing this framework, including the effort and cost of monitoring for health systems with limited resources and the difficulty of incorporating data-driven monitoring practices into complex organizations where conflicting priorities and definitions of success often coexist. This framework offers a practical template and starting point for health systems seeking to ensure that AI deployments remain safe and effective over time.

10 Dec 2025
Context. LLM-based autonomous agents in software engineering rely on large, proprietary models, limiting local deployment. This has spurred interest in Small Language Models (SLMs), but their practical effectiveness and efficiency within complex agentic frameworks for automated issue resolution remain poorly understood.
Goal. We investigate the performance, energy efficiency, and resource consumption of four leading agentic issue resolution frameworks when deliberately constrained to using SLMs. We aim to assess the viability of these systems for this task in resource-limited settings and characterize the resulting trade-offs.
Method. We conduct a controlled evaluation of four leading agentic frameworks (SWE-Agent, OpenHands, Mini SWE Agent, AutoCodeRover) using two SLMs (Gemma-3 4B, Qwen-3 1.7B) on the SWE-bench Verified Mini benchmark. On fixed hardware, we measure energy, duration, token usage, and memory over 150 runs per configuration.
Results. We find that framework architecture is the primary driver of energy consumption. The most energy-intensive framework, AutoCodeRover (Gemma), consumed 9.4x more energy on average than the least energy-intensive, OpenHands (Gemma). However, this energy is largely wasted. Task resolution rates were near-zero, demonstrating that current frameworks, when paired with SLMs, consume significant energy on unproductive reasoning loops. The SLM's limited reasoning was the bottleneck for success, but the framework's design was the bottleneck for efficiency.
Conclusions. Current agentic frameworks, designed for powerful LLMs, fail to operate efficiently with SLMs. We find that framework architecture is the primary driver of energy consumption, but this energy is largely wasted due to the SLMs' limited reasoning. Viable low-energy solutions require shifting from passive orchestration to architectures that actively manage SLM weaknesses.

26 Nov 2025
Researchers from Yonsei University and the University of Wisconsin–Madison developed a statistical framework to correct for bias and quantify uncertainty in Large Language Model (LLM)-as-a-Judge evaluations. The framework provides a bias-adjusted estimator for true model accuracy and constructs confidence intervals that account for uncertainty from both test and calibration datasets, demonstrating reliable coverage probabilities and reduced bias in simulations.

10 Dec 2025
This article presents the creation of an Estonian-language dataset for document-level subjectivity, analyzes the resulting annotations, and reports an initial experiment of automatic subjectivity analysis using a large language model (LLM). The dataset comprises of 1,000 documents-300 journalistic articles and 700 randomly selected web texts-each rated for subjectivity on a continuous scale from 0 (fully objective) to 100 (fully subjective) by four annotators. As the inter-annotator correlations were moderate, with some texts receiving scores at the opposite ends of the scale, a subset of texts with the most divergent scores was re-annotated, with the inter-annotator correlation improving. In addition to human annotations, the dataset includes scores generated by GPT-5 as an experiment on annotation automation. These scores were similar to human annotators, however several differences emerged, suggesting that while LLM based automatic subjectivity scoring is feasible, it is not an interchangeable alternative to human annotation, and its suitability depends on the intended application.

09 Dec 2025
Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies.
We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications.
We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.

10 Dec 2025
Hate speech spreads widely online, harming individuals and communities, making automatic detection essential for large-scale moderation, yet detecting it remains difficult. Part of the challenge lies in subjectivity: what one person flags as hate speech, another may see as benign. Traditional annotation agreement metrics, such as Cohen's , oversimplify this disagreement, treating it as an error rather than meaningful diversity. Meanwhile, Large Language Models (LLMs) promise scalable annotation, but prior studies demonstrate that they cannot fully replace human judgement, especially in subjective tasks. In this work, we reexamine LLM reliability using a subjectivity-aware framework, cross-Rater Reliability (xRR), revealing that even under fairer lens, LLMs still diverge from humans. Yet this limitation opens an opportunity: we find that LLM-generated annotations can reliably reflect performance trends across classification models, correlating with human evaluations. We test this by examining whether LLM-generated annotations preserve the relative ordering of model performance derived from human evaluation (i.e. whether models ranked as more reliable by human annotators preserve the same order when evaluated with LLM-generated labels). Our results show that, although LLMs differ from humans at the instance level, they reproduce similar ranking and classification patterns, suggesting their potential as proxy evaluators. While not a substitute for human annotators, they might serve as a scalable proxy for evaluation in subjective NLP tasks.

09 Dec 2025
Both model developers and policymakers seek to quantify and mitigate the risk of rapidly-evolving frontier artificial intelligence (AI) models, especially large language models (LLMs), to facilitate bioterrorism or access to biological weapons. An important element of such efforts is the development of model benchmarks that can assess the biosecurity risk posed by a particular model. This paper describes the first component of a novel Biothreat Benchmark Generation (BBG) Framework. The BBG approach is designed to help model developers and evaluators reliably measure and assess the biosecurity risk uplift and general harm potential of existing and future AI models, while accounting for key aspects of the threat itself that are often overlooked in other benchmarking efforts, including different actor capability levels, and operational (in addition to purely technical) risk factors. As a pilot, the BBG is first being developed to address bacterial biological threats only. The BBG is built upon a hierarchical structure of biothreat categories, elements and tasks, which then serves as the basis for the development of task-aligned queries. This paper outlines the development of this biothreat task-query architecture, which we have named the Bacterial Biothreat Schema, while future papers will describe follow-on efforts to turn queries into model prompts, as well as how the resulting benchmarks can be implemented for model evaluation. Overall, the BBG Framework, including the Bacterial Biothreat Schema, seeks to offer a robust, re-usable structure for evaluating bacterial biological risks arising from LLMs across multiple levels of aggregation, which captures the full scope of technical and operational requirements for biological adversaries, and which accounts for a wide spectrum of biological adversary capabilities.

10 Dec 2025
Generative audio models, based on diffusion and autoregressive architectures, have advanced rapidly in both quality and expressiveness. This progress, however, raises pressing copyright concerns, as such models are often trained on vast corpora of artistic and commercial works. A central question is whether one can reliably verify if an artist's material was included in training, thereby providing a means for copyright holders to protect their content. In this work, we investigate the feasibility of such verification through membership inference attacks (MIA) on open-source generative audio models, which attempt to determine whether a specific audio sample was part of the training set. Our empirical results show that membership inference alone is of limited effectiveness at scale, as the per-sample membership signal is weak for models trained on large and diverse datasets. However, artists and media owners typically hold collections of works rather than isolated samples. Building on prior work in text and vision domains, in this work we focus on dataset inference (DI), which aggregates diverse membership evidence across multiple samples. We find that DI is successful in the audio domain, offering a more practical mechanism for assessing whether an artist's works contributed to model training. Our results suggest DI as a promising direction for copyright protection and dataset accountability in the era of large audio generative models.

10 Dec 2025
Culture is a core component of human-to-human interaction and plays a vital role in how we perceive and interact with others. Advancements in the effectiveness of Large Language Models (LLMs) in generating human-sounding text have greatly increased the amount of human-to-computer interaction. As this field grows, the cultural alignment of these human-like agents becomes an important field of study. Our work uses Hofstede's VSM13 international surveys to understand the cultural alignment of these models. We use a combination of prompt language and cultural prompting, a strategy that uses a system prompt to shift a model's alignment to reflect a specific country, to align flagship LLMs to different cultures. Our results show that DeepSeek-V3, V3.1, and OpenAI's GPT-5 exhibit a close alignment with the survey responses of the United States and do not achieve a strong or soft alignment with China, even when using cultural prompts or changing the prompt language. We also find that GPT-4 exhibits an alignment closer to China when prompted in English, but cultural prompting is effective in shifting this alignment closer to the United States. Other low-cost models, GPT-4o and GPT-4.1, respond to the prompt language used (i.e., English or Simplified Chinese) and cultural prompting strategies to create acceptable alignments with both the United States and China.

02 Dec 2025
Researchers from FAIR at Meta and the University of Washington developed an iterative self-training framework for Vision-Language Model (VLM) judges that operates entirely without human preference annotations. This approach allowed an 11-billion parameter VLM judge to achieve a 40.5% relative performance gain on VL-RewardBench and a 7.5% gain on Multimodal RewardBench, in some cases outperforming larger proprietary models like GPT-4o in specific evaluation dimensions.

03 Dec 2025



A new benchmark, DAComp, evaluates large language model (LLM) agents across the full data intelligence lifecycle, integrating repository-level data engineering and open-ended data analysis. Experiments reveal state-of-the-art LLMs struggle with holistic pipeline orchestration and strategic insight synthesis, achieving an aggregated data engineering score of 43.45% and a data analysis score of 50.84% with top models.

04 Dec 2025
A systematic literature review by Gao et al. offers the first comprehensive taxonomy of bugs found in AI-generated code, revealing functional and syntax errors as the most prevalent types across various models. The work also analyzes model-specific bug proneness and synthesizes diverse mitigation strategies from 72 studies.
There are no more papers matching your filters at the moment.
