
16 Jun 2025


G-Memory introduces a hierarchical, graph-based memory system designed for Large Language Model-based Multi-Agent Systems, enabling them to learn from complex collaborative histories. The system consistently improves MAS performance, achieving gains up to 20.89% in embodied action and 10.12% in knowledge question-answering tasks, while maintaining resource efficiency.

01 Oct 2025

An open-source environment simulator, GEM, provides a standardized framework for experience-based learning in large language models (LLMs) through a Gym-like API and a diverse task suite. It supports full multi-turn reinforcement learning, validated by demonstrating robust performance from REINFORCE with Return Batch Normalization (ReBN) and notable gains from integrated tool use.

23 Mar 2025


This paper offers the first comprehensive survey of Multimodal Chain-of-Thought (MCoT) reasoning, analyzing its evolution, diverse methodologies, and applications across various modalities. It consolidates scattered research, providing a systematic taxonomy, elucidating foundational concepts, and identifying future research directions to foster innovation in multimodal AI.

23 Oct 2025


A framework called Open-o3 Video enables grounded video reasoning by integrating explicit spatio-temporal evidence directly into the model's output. This approach achieves state-of-the-art performance on the V-STAR benchmark while providing precise timestamps and bounding boxes for supporting visual cues.

14 Oct 2025
 National University of SingaporeNUSShanghai AI Lab
National University of SingaporeNUSShanghai AI Lab Nanyang Technological University
Nanyang Technological University Huazhong University of Science and TechnologyS-Lab, NTUNational Key Laboratory of Multispectral Information Intelligent Processing Technology, School of Artificial Intelligence and Automation, Huazhong University of Science and Technology
Huazhong University of Science and TechnologyS-Lab, NTUNational Key Laboratory of Multispectral Information Intelligent Processing Technology, School of Artificial Intelligence and Automation, Huazhong University of Science and TechnologyVideoLucy introduces a deep memory backtracking framework with a hierarchical memory structure and iterative agent-based exploration, enabling accurate and comprehensive understanding of ultra-long videos. The system surpasses GPT-4o by 9.9% on LVBench and improves performance by 10.3% on the new EgoMem benchmark for extremely long videos.

02 Dec 2025

Glance introduces a phase-aware acceleration framework for diffusion models, achieving up to 5x faster inference, enabling high-quality image generation in 8-10 steps compared to 50. This acceleration is accomplished with remarkably low training costs, utilizing only a single training sample and less than one GPU-hour of training while preserving visual quality and generalization.
01 Jul 2025


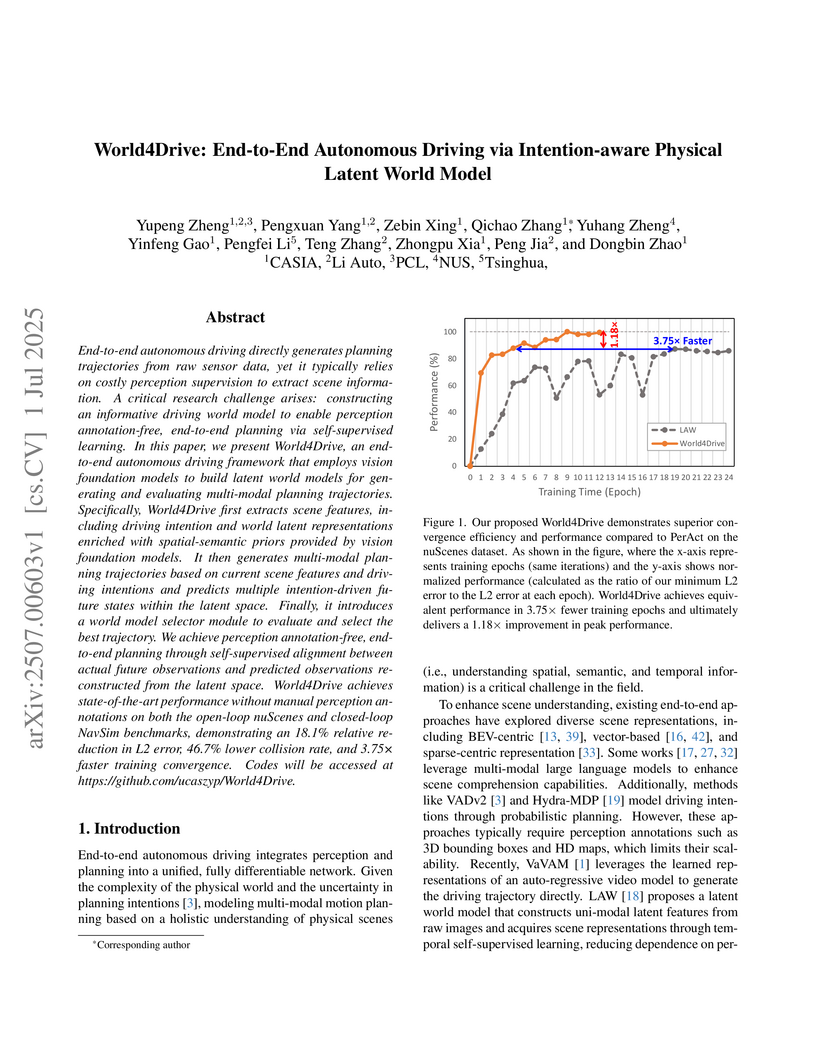
World4Drive presents an end-to-end autonomous driving framework that generates planning trajectories directly from raw sensor data, eliminating the need for manual perception annotations by leveraging intention-aware physical latent world models. This system achieves a 46.7% relative reduction in collision rate and 3.75x faster training convergence compared to previous self-supervised methods on the nuScenes dataset.

27 Aug 2025

The PyVision framework equips multimodal large language models with the ability to autonomously generate, execute, and refine Python code for visual reasoning tasks. This approach leads to consistent performance improvements across various benchmarks, including a 7.8% gain on fine-grained visual search with GPT-4.1 and a 31.1% increase on symbolic vision tasks with Claude-4.0-Sonnet.

03 Dec 2025

A new benchmark, DAComp, evaluates large language model (LLM) agents across the full data intelligence lifecycle, integrating repository-level data engineering and open-ended data analysis. Experiments reveal state-of-the-art LLMs struggle with holistic pipeline orchestration and strategic insight synthesis, achieving an aggregated data engineering score of 43.45% and a data analysis score of 50.84% with top models.

30 Oct 2025
FARMER (Flow AutoRegressive Transformer over Pixels) unifies Autoregressive Flows with Autoregressive Transformers to enable high-fidelity image synthesis directly from raw pixels while providing exact likelihoods. The method introduces self-supervised dimension reduction and one-step distillation for improved generation quality and accelerated inference, achieving competitive performance on ImageNet 256x256.

13 Oct 2025






Vlaser introduces a Vision-Language-Action (VLA) model that integrates perception, language understanding, and physical control through synergistic embodied reasoning, achieving strong performance on embodied benchmarks and robot manipulation tasks. The research reveals that in-domain robot interaction data is substantially more effective for VLA fine-tuning than general embodied reasoning data due to a significant domain shift.

31 Mar 2025


A new benchmark, MMIE, comprising over 20,000 multimodal queries, measures large vision-language models' ability to comprehend and generate interleaved text and images across diverse knowledge domains. The research also introduces MMIE-Score, an automated evaluation metric that demonstrates superior alignment with human judgment compared to existing methods.

19 May 2025

EFFIBENCH-X introduces the first multi-language benchmark designed to measure the execution time and memory efficiency of code generated by large language models. The evaluation of 26 state-of-the-art LLMs reveals a consistent efficiency gap compared to human-expert solutions, with top models achieving around 62% of human execution time efficiency and varying performance across different programming languages and problem types.

08 Mar 2025

This research provides a systematic analysis of visual feature integration in Multimodal Large Language Models, focusing on optimal layer selection and fusion strategies. It identifies that selecting specific layers from different stages of a visual encoder and employing an external direct fusion method consistently yield the best performance across various multimodal benchmarks.

09 Oct 2025
 ETH Zurich
ETH Zurich University of Washington
University of Washington University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign Monash University
Monash University University of Notre Dame
University of Notre Dame Google
Google University of OxfordNUS
University of OxfordNUS University of California, San DiegoCSIRO’s Data61
University of California, San DiegoCSIRO’s Data61 NVIDIATencent AI Lab
NVIDIATencent AI Lab Hugging Face
Hugging Face Purdue UniversitySingapore Management UniversityIBMInstitute of Automation, CAS
Purdue UniversitySingapore Management UniversityIBMInstitute of Automation, CAS ServiceNowComenius University in BratislavaHKUST GuangzhouCiscoTano LabsU.Va.UberCNRS, FranceNevsky CollectiveDetomo Inc
ServiceNowComenius University in BratislavaHKUST GuangzhouCiscoTano LabsU.Va.UberCNRS, FranceNevsky CollectiveDetomo IncBIGCODEARENA introduces an open, execution-backed human evaluation platform for large language model (LLM) generated code, collecting human preference data to form benchmarks for evaluating code LLMs and reward models. This approach demonstrates that execution feedback improves the reliability of evaluations and reveals detailed performance differences among models across various programming languages and environments.

07 May 2025


A comprehensive framework called General-Level introduces a 5-level taxonomy for evaluating multimodal large language models (MLLMs), accompanied by General-Bench - a large-scale benchmark testing diverse modalities and tasks, revealing that even leading models like GPT-4V achieve only Level-3 capabilities while demonstrating limited cross-modal synergy.

11 Jun 2025
While large language models (LLMs) can solve PhD-level reasoning problems
over long context inputs, they still struggle with a seemingly simpler task:
following explicit length instructions-e.g., write a 10,000-word novel.
Additionally, models often generate far too short outputs, terminate
prematurely, or even refuse the request. Existing benchmarks focus primarily on
evaluating generations quality, but often overlook whether the generations meet
length constraints. To this end, we introduce Length Instruction Following
Evaluation Benchmark (LIFEBench) to comprehensively evaluate LLMs' ability to
follow length instructions across diverse tasks and a wide range of specified
lengths. LIFEBench consists of 10,800 instances across 4 task categories in
both English and Chinese, covering length constraints ranging from 16 to 8192
words. We evaluate 26 widely-used LLMs and find that most models reasonably
follow short-length instructions but deteriorate sharply beyond a certain
threshold. Surprisingly, almost all models fail to reach the vendor-claimed
maximum output lengths in practice, as further confirmed by our evaluations
extending up to 32K words. Even long-context LLMs, despite their extended
input-output windows, counterintuitively fail to improve length-instructions
following. Notably, Reasoning LLMs outperform even specialized long-text
generation models, achieving state-of-the-art length following. Overall,
LIFEBench uncovers fundamental limitations in current LLMs' length instructions
following ability, offering critical insights for future progress.

11 Jun 2025
Chain-of-Action (CoA) proposes a visuo-motor policy that generates robot trajectories autoregressively in reverse, starting from a task goal and reasoning backward to the current state. This approach addresses compounding errors and enhances spatial generalization, achieving an average success rate of 0.552 on 60 RLBench tasks and demonstrating improved performance on real-world Fetch robot manipulation.

02 Jun 2025
Temporal-RLT is a reinforcement learning tuning framework for VideoLLMs that enhances video-specific reasoning by employing dual reward functions for semantic and temporal understanding and a variance-aware data selection strategy. The framework improves temporal grounding on Charades-STA by 14.0 mIoU and ActivityNet by 14.7 mIoU, while maintaining strong performance on VideoQA tasks.

10 Oct 2025
Large language model based multi-agent systems (MAS) have unlocked significant advancements in tackling complex problems, but their increasing capability introduces a structural fragility that makes them difficult to debug. A key obstacle to improving their reliability is the severe scarcity of large-scale, diverse datasets for error attribution, as existing resources rely on costly and unscalable manual annotation. To address this bottleneck, we introduce Aegis, a novel framework for Automated error generation and attribution for multi-agent systems. Aegis constructs a large dataset of 9,533 trajectories with annotated faulty agents and error modes, covering diverse MAS architectures and task domains. This is achieved using a LLM-based manipulator that can adaptively inject context-aware errors into successful execution trajectories. Leveraging fine-grained labels and the structured arrangement of positive-negative sample pairs, Aegis supports three different learning paradigms: Supervised Fine-Tuning, Reinforcement Learning, and Contrastive Learning. We develop learning methods for each paradigm. Comprehensive experiments show that trained models consistently achieve substantial improvements in error attribution. Notably, several of our fine-tuned LLMs demonstrate performance competitive with or superior to proprietary models an order of magnitude larger, validating our automated data generation framework as a crucial resource for developing more robust and interpretable multi-agent systems. Our project website is available at this https URL.
There are no more papers matching your filters at the moment.
