
03 Sep 2025


The paper introduces SimpleTIR, an end-to-end Reinforcement Learning (RL) approach that stabilizes multi-turn Tool-Integrated Reasoning (TIR) in Large Language Models (LLMs) under the Zero RL setting. SimpleTIR resolves training instability and gradient explosions by filtering problematic 'void turns,' achieving state-of-the-art performance on mathematical reasoning benchmarks and fostering diverse, emergent reasoning patterns.

20 Oct 2024
Depth Anything V2 introduces a new paradigm for monocular depth estimation by leveraging precise synthetic data for detail and massive pseudo-labeled real data for robustness. The model family achieves state-of-the-art performance in zero-shot relative depth estimation, with the largest model reaching 97.4% accuracy on the new DA-2K benchmark, while maintaining high inference efficiency.
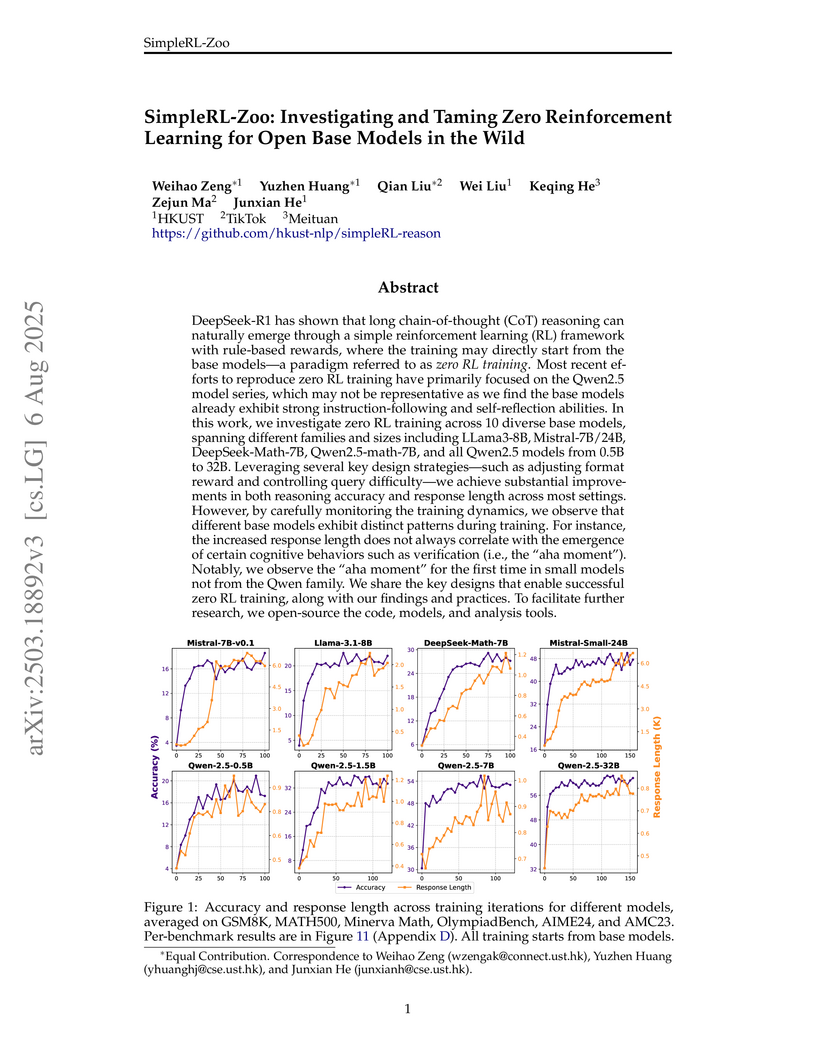
06 Aug 2025


SimpleRL-Zoo comprehensively investigates zero reinforcement learning (RL) on 10 diverse open base models, demonstrating that advanced reasoning behaviors can emerge from models initially lacking strong instruction-following and that traditional supervised fine-tuning can actually hinder this emergence.

09 Jun 2025

This paper introduces 'General-Reasoner,' an approach that extends Large Language Model reasoning capabilities across diverse domains beyond mathematics and coding. It achieves this by curating a large-scale, verifiable all-domain reasoning dataset and developing a generative model-based verifier for robust answer assessment within a 'Zero RL' training framework, with models demonstrating performance competitive with or surpassing commercial LLMs on various benchmarks.

07 Apr 2024


Researchers from HKU, TikTok, CUHK, and ZJU developed "Depth Anything," a robust foundation model for monocular depth estimation that leverages an unprecedented 62 million unlabeled images. The model demonstrates superior zero-shot generalization and establishes new state-of-the-art performance upon fine-tuning on various benchmarks, also yielding a versatile encoder for semantic tasks.

16 Jul 2025


SWE-Perf introduces the first benchmark for evaluating Large Language Models (LLMs) on real-world, repository-level code performance optimization, drawing from 140 human-authored performance-improving pull requests. Evaluations using SWE-Perf reveal a substantial gap between current LLM capabilities (e.g., OpenHands with 2.26% average gain) and expert performance (10.85% gain), indicating LLMs struggle with complex, multi-function optimization and identifying opportunities in computationally intensive code.

03 Dec 2025


A new benchmark, DAComp, evaluates large language model (LLM) agents across the full data intelligence lifecycle, integrating repository-level data engineering and open-ended data analysis. Experiments reveal state-of-the-art LLMs struggle with holistic pipeline orchestration and strategic insight synthesis, achieving an aggregated data engineering score of 43.45% and a data analysis score of 50.84% with top models.

01 Nov 2025

An automated web-agent-driven pipeline called MCP-FLOW constructs a large-scale, high-quality dataset from real-world Model Contextual Protocol (MCP) servers to enable Large Language Models (LLMs) to effectively use diverse external tools. The generated dataset, comprising over 68,000 instruction-function call pairs, allows smaller, fine-tuned LLMs to achieve superior performance in tool selection and complex agentic tasks compared to larger state-of-the-art models.

27 May 2025

Researchers developed SURDS, a benchmark for evaluating Vision Language Models' fine-grained spatial understanding and reasoning in real-world driving environments. An accompanying reinforcement learning-based alignment method achieved an overall score of 40.80 on SURDS, enabling a 3B-parameter model to surpass larger, general-purpose VLMs.

26 Sep 2025
Draw-In-Mind: Rebalancing Designer-Painter Roles in Unified Multimodal Models Benefits Image Editing
Draw-In-Mind: Rebalancing Designer-Painter Roles in Unified Multimodal Models Benefits Image Editing
Researchers from National University of Singapore's Show Lab and TikTok introduced the Draw-In-Mind (DIM) framework, which rebalances the understanding and generation roles within unified multimodal models for instruction-guided image editing. This approach, leveraging a new Chain-of-Thought (CoT) dataset, achieved state-of-the-art performance on image editing benchmarks like ImgEdit and GEdit-Bench-EN, while also demonstrating a 4.5x speedup in inference compared to previous models.

19 Jun 2025

SWE-Dev introduces a large-scale dataset for evaluating and training autonomous AI systems on real-world Feature-Driven Development (FDD) tasks, demonstrating that fine-tuning models on its 14,000 verifiable training instances significantly improves performance on complex, repository-level coding challenges.

03 Dec 2024
A comprehensive review by researchers from TikTok and several universities surveys the advancements and challenges of MultiModal Large Language Models (MM-LLMs) for understanding long videos. The work systematically traces model evolution, highlights the necessity for specialized architectural adaptations and training strategies, and quantitatively compares performance across various video benchmarks.

14 Oct 2025

In the multimedia domain, Infrared Small Target Detection (ISTD) plays a important role in drone-based multi-modality sensing. To address the dual challenges of cross-domain shift and heteroscedastic noise perturbations in ISTD, we propose a doubly wavelet-guided Invariance learning framework(Ivan-ISTD). In the first stage, we generate training samples aligned with the target domain using Wavelet-guided Cross-domain Synthesis. This wavelet-guided alignment machine accurately separates the target background through multi-frequency wavelet filtering. In the second stage, we introduce Real-domain Noise Invariance Learning, which extracts real noise characteristics from the target domain to build a dynamic noise library. The model learns noise invariance through self-supervised loss, thereby overcoming the limitations of distribution bias in traditional artificial noise modeling. Finally, we create the Dynamic-ISTD Benchmark, a cross-domain dynamic degradation dataset that simulates the distribution shifts encountered in real-world applications. Additionally, we validate the versatility of our method using other real-world datasets. Experimental results demonstrate that our approach outperforms existing state-of-the-art methods in terms of many quantitative metrics. In particular, Ivan-ISTD demonstrates excellent robustness in cross-domain scenarios. The code for this work can be found at: this https URL.

03 Oct 2025
Researchers from TikTok Inc. developed a reasoning-enhanced domain-adaptive pretraining paradigm for Multimodal Large Language Models (MLLMs) to improve short video content governance. This method, using custom pretraining tasks, enhances MLLMs' understanding of complex guidelines and generalization across content issues, outperforming GPT-4o and achieving up to 31% absolute accuracy gains on in-domain tasks.

15 May 2025
Large Language Models (LLMs) have gained significant popularity due to their
remarkable capabilities in text understanding and generation. However, despite
their widespread deployment in inference services such as ChatGPT, concerns
about the potential leakage of sensitive user data have arisen. Existing
solutions primarily rely on privacy-enhancing technologies to mitigate such
risks, facing the trade-off among efficiency, privacy, and utility. To narrow
this gap, we propose Cape, a context-aware prompt perturbation mechanism based
on differential privacy, to enable efficient inference with an improved
privacy-utility trade-off. Concretely, we introduce a hybrid utility function
that better captures the token similarity. Additionally, we propose a
bucketized sampling mechanism to handle large sampling space, which might lead
to long-tail phenomenons. Extensive experiments across multiple datasets, along
with ablation studies, demonstrate that Cape achieves a better privacy-utility
trade-off compared to prior state-of-the-art works.

13 Oct 2025

Researchers at TikTok and Rutgers University developed Secret-Protected Evolution (SecPE), a framework for differentially private synthetic text generation that provides secret-aware protection. This approach dramatically reduces computational overhead, achieving up to 13,000x faster histogram computation, and delivers improved data utility and downstream task performance under privacy compared to traditional GDP-based methods.

17 Feb 2025



Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs)
have made significant advancements in reasoning capabilities. However, they
still face challenges such as high computational demands and privacy concerns.
This paper focuses on developing efficient Small Language Models (SLMs) and
Multimodal Small Language Models (MSLMs) that retain competitive reasoning
abilities. We introduce a novel training pipeline that enhances reasoning
capabilities and facilitates deployment on edge devices, achieving
state-of-the-art performance while minimizing development costs. \InfR~ aims to
advance AI systems by improving reasoning, reducing adoption barriers, and
addressing privacy concerns through smaller model sizes. Resources are
available at this https URL com/Reallm-Labs/InfiR.

23 Jul 2025
Effective content moderation is essential for video platforms to safeguard user experience and uphold community standards. While traditional video classification models effectively handle well-defined moderation tasks, they struggle with complicated scenarios such as implicit harmful content and contextual ambiguity. Multimodal large language models (MLLMs) offer a promising solution to these limitations with their superior cross-modal reasoning and contextual understanding. However, two key challenges hinder their industrial adoption. First, the high computational cost of MLLMs makes full-scale deployment impractical. Second, adapting generative models for discriminative classification remains an open research problem. In this paper, we first introduce an efficient method to transform a generative MLLM into a multimodal classifier using minimal discriminative training data. To enable industry-scale deployment, we then propose a router-ranking cascade system that integrates MLLMs with a lightweight router model. Offline experiments demonstrate that our MLLM-based approach improves F1 score by 66.50% over traditional classifiers while requiring only 2% of the fine-tuning data. Online evaluations show that our system increases automatic content moderation volume by 41%, while the cascading deployment reduces computational cost to only 1.5% of direct full-scale deployment.

01 Sep 2025

This paper presents an efficient framework for private Transformer inference that combines Homomorphic Encryption (HE) and Secure Multi-party Computation (MPC) to protect data privacy. Existing methods often leverage HE for linear layers (e.g., matrix multiplications) and MPC for non-linear layers (e.g., Softmax activation functions), but the conversion between HE and MPC introduces significant communication costs. The proposed framework, dubbed BLB, overcomes this by breaking down layers into fine-grained operators and further fusing adjacent linear operators, reducing the need for HE/MPC conversions. To manage the increased ciphertext bit width from the fused linear operators, BLB proposes the first secure conversion protocol between CKKS and MPC and enables CKKS-based computation of the fused operators. Additionally, BLB proposes an efficient matrix multiplication protocol for fused computation in Transformers. Extensive evaluations on BERT-base, BERT-large, and GPT2-base show that BLB achieves a reduction in communication overhead compared to BOLT (S\&P'24) and a reduction compared to Bumblebee (NDSS'25), along with latency reductions of and , respectively, when leveraging GPU acceleration.

13 May 2025
Multimodal large language models have become a popular topic in deep visual
understanding due to many promising real-world applications. However, hour-long
video understanding, spanning over one hour and containing tens of thousands of
visual frames, remains under-explored because of 1) challenging long-term video
analyses, 2) inefficient large-model approaches, and 3) lack of large-scale
benchmark datasets. Among them, in this paper, we focus on building a
large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long
video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847
high-quality question answering (QA) and multi-choice question asnwering (MCQA)
pairs with time-aware query and diverse annotations, covering frame-level,
within-event-level, cross-event-level, and long-term reasoning tasks. We
evaluate our benchmark using existing state-of-the-art methods and demonstrate
its value for testing deep long video understanding capabilities at different
levels and for various tasks. This includes promoting future long video
understanding tasks at a granular level, such as deep understanding of long
live videos, meeting recordings, and movies.
There are no more papers matching your filters at the moment.
