
05 Dec 2025
Edward Y. Chang from Stanford University proposes a "Substrate plus Coordination" framework for Artificial General Intelligence (AGI), arguing that Large Language Models (LLMs) provide a necessary System-1 pattern-matching substrate that requires a System-2 coordination layer to achieve reliable, goal-directed reasoning. This work formalizes semantic anchoring through the Unified Contextual Control Theory (UCCT) and introduces the Multi-Agent Collaborative Intelligence (MACI) architecture to implement this missing layer.

09 Dec 2025
Recent advances in Large Language Models have revolutionized function-level code generation; however, repository-scale Automated Program Repair (APR) remains a significant challenge. Current approaches typically employ a control-centric paradigm, forcing agents to navigate complex directory structures and irrelevant control logic. In this paper, we propose a paradigm shift from the standard Code Property Graphs (CPGs) to the concept of Data Transformation Graph (DTG) that inverts the topology by modeling data states as nodes and functions as edges, enabling agents to trace logic defects through data lineage rather than control flow. We introduce a multi-agent framework that reconciles data integrity navigation with control flow logic. Our theoretical analysis and case studies demonstrate that this approach resolves the "Semantic Trap" inherent in standard RAG systems in modern coding agents. We provide a comprehensive implementation in the form of Autonomous Issue Resolver (AIR), a self-improvement system for zero-touch code maintenance that utilizes neuro-symbolic reasoning and uses the DTG structure for scalable logic repair. Our approach has demonstrated good results on several SWE benchmarks, reaching a resolution rate of 87.1% on SWE-Verified benchmark. Our approach directly addresses the core limitations of current AI code-assistant tools and tackles the critical need for a more robust foundation for our increasingly software-dependent world.

03 Dec 2025


Researchers from Zhejiang University and ByteDance introduced CodeVision, a "code-as-tool" framework that equips Multimodal Large Language Models (MLLMs) to programmatically interact with images. The approach significantly improves MLLM robustness by correcting common image corruptions and enables state-of-the-art multi-tool reasoning through emergent tool use and error recovery.

10 Dec 2025
We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework across various domains and tasks, including the Google NaturalPlan benchmark and PlanBench, as well as planning problems like Blocksworld and the Tower of Hanoi (where LLMs are known to struggle even with small instances). Our framework can be integrated with any PDDL planning engine and validator (such as Fast Downward, LPG, POPF, VAL, and uVAL, which we have tested) and represents a significant step toward end-to-end planning aided by LLMs.

09 Dec 2025
Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at this https URL.

08 Dec 2025
NeSTR is a neuro-symbolic abductive framework designed to enhance temporal reasoning in Large Language Models (LLMs) through a five-stage prompting strategy that integrates symbolic representation, neural inference, and error correction. The framework achieved a macro-average F1 score of 89.7 with GPT-4o-mini, surpassing prior methods and demonstrating robust zero-shot performance across various temporal question answering benchmarks.

05 Dec 2025

Traditional physics-informed neural networks (PINNs) do not always satisfy physics based constraints, especially when the constraints include differential operators. Rather, they minimize the constraint violations in a soft way. Strict satisfaction of differential-algebraic equations (DAEs) to embed domain knowledge and first-principles in data-driven models is generally challenging. This is because data-driven models consider the original functions to be black-box whose derivatives can only be obtained after evaluating the functions. We introduce DAE-HardNet, a physics-constrained (rather than simply physics-informed) neural network that learns both the functions and their derivatives simultaneously, while enforcing algebraic as well as differential constraints. This is done by projecting model predictions onto the constraint manifold using a differentiable projection layer. We apply DAE-HardNet to several systems and test problems governed by DAEs, including the dynamic Lotka-Volterra predator-prey system and transient heat conduction. We also show the ability of DAE-HardNet to estimate unknown parameters through a parameter estimation problem. Compared to multilayer perceptrons (MLPs) and PINNs, DAE-HardNet achieves orders of magnitude reduction in the physics loss while maintaining the prediction accuracy. It has the added benefits of learning the derivatives which improves the constrained learning of the backbone neural network prior to the projection layer. For specific problems, this suggests that the projection layer can be bypassed for faster inference. The current implementation and codes are available at this https URL.

08 Dec 2025
Virtual representations of physical critical infrastructures, such as water or energy plants, are used for simulations and digital twins to ensure resilience and continuity of their services. These models usually require 3D point clouds from laser scanners that are expensive to acquire and require specialist knowledge to use. In this article, we present a graph generation pipeline based on photogrammetry. The pipeline detects relevant objects and predicts their relation using RGB images and depth data generated by a stereo camera. This more cost-effective approach uses deep learning for object detection and instance segmentation of the objects, and employs user-defined heuristics or rules to infer their relations. Results of two hydraulic systems show that this strategy can produce graphs close to the ground truth while its flexibility allows the method to be tailored to specific applications and its transparency qualifies it to be used in the high stakes decision-making that is required for critical infrastructures.

28 Nov 2025
ORION enables Large Language Models to reason efficiently through a cognitively inspired, compact "Mentalese" format and adaptive reinforcement learning. This framework achieves 4-16x compression of reasoning traces and up to 5x faster inference while maintaining high accuracy, showing strong generalization across diverse reasoning tasks.

02 Dec 2025
Symbolic computer vision represents diagrams through explicit logical rules and structured representations, enabling interpretable understanding in machine vision. This requires fundamentally different learning paradigms from pixel-based visual models. Symbolic visual learners parse diagrams into geometric primitives-points, lines, and shapes-whereas pixel-based learners operate on textures and colors. We propose a novel self-supervised symbolic auto-encoder that encodes diagrams into structured primitives and their interrelationships within the latent space, and decodes them through our executable engine to reconstruct the input diagrams. Central to this architecture is Symbolic Hierarchical Process Reward Modeling, which applies hierarchical step-level parsing rewards to enforce point-on-line, line-on-shape, and shape-on-relation consistency. Since vanilla reinforcement learning exhibits poor exploration in the policy space during diagram reconstruction; we thus introduce stabilization mechanisms to balance exploration and exploitation. We fine-tune our symbolic encoder on downstream tasks, developing a neuro-symbolic system that integrates the reasoning capabilities of neural networks with the interpretability of symbolic models through reasoning-grounded visual rewards. Evaluations across reconstruction, perception, and reasoning tasks demonstrate the effectiveness of our approach: achieving a 98.2% reduction in MSE for geometric diagram reconstruction, surpassing GPT-4o by 0.6% with a 7B model on chart reconstruction, and improving by +13% on the MathGlance perception benchmark, and by +3% on MathVerse and GeoQA reasoning benchmarks.

01 Dec 2025
Environmental, Social, and Governance (ESG) disclosure frameworks such as SASB, TCFD, and IFRS S2 require organizations to compute and report numerous metrics for compliance, yet these requirements are embedded in long, unstructured PDF documents that are difficult to interpret, standardize, and audit. Manual extraction is unscalable, while unconstrained large language model (LLM) extraction often produces inconsistent entities, hallucinated relationships, missing provenance, and high validation failure rates. We present OntoMetric, an ontology-guided framework that transforms ESG regulatory documents into validated, AI- and web-ready knowledge graphs. OntoMetric operates through a three-stage pipeline: (1) structure-aware segmentation using table-of-contents boundaries, (2) ontology-constrained LLM extraction that embeds the ESGMKG schema into prompts while enriching entities with semantic fields for downstream reasoning, and (3) two-phase validation that combines LLM-based semantic verification with rule-based schema checking across entity, property, and relationship levels (VR001-VR006). The framework preserves both segment-level and page-level provenance for audit traceability. Evaluated on five ESG standards (SASB Commercial Banks, SASB Semiconductors, TCFD, IFRS S2, AASB S2) totaling 228 pages and 60 segments, OntoMetric achieves 65-90% semantic accuracy and 80-90% schema compliance, compared to 3-10% for baseline unconstrained extraction, at approximately 0.01 to 0.02 USD per validated entity. Our results demonstrate that combining symbolic ontology constraints with neural extraction enables reliable, auditable knowledge graphs suitable for regulatory compliance and web integration, supporting downstream applications such as sustainable-finance analytics, transparency portals, and automated compliance tools.

05 Dec 2025
Optical aberrations significantly degrade image quality in microscopy, particularly when imaging deeper into samples. These aberrations arise from distortions in the optical wavefront and can be mathematically represented using Zernike polynomials. Existing methods often address only mild aberrations on limited sample types and modalities, typically treating the problem as a black-box mapping without leveraging the underlying optical physics of wavefront distortions. We propose ZRNet, a physics-informed framework that jointly performs Zernike coefficient prediction and optical image Restoration. We contribute a Zernike Graph module that explicitly models physical relationships between Zernike polynomials based on their azimuthal degrees-ensuring that learned corrections align with fundamental optical principles. To further enforce physical consistency between image restoration and Zernike prediction, we introduce a Frequency-Aware Alignment (FAA) loss, which better aligns Zernike coefficient prediction and image features in the Fourier domain. Extensive experiments on CytoImageNet demonstrates that our approach achieves state-of-the-art performance in both image restoration and Zernike coefficient prediction across diverse microscopy modalities and biological samples with complex, large-amplitude aberrations. Code is available at this https URL.

29 Nov 2025

Researchers from Stony Brook University and LIX, École Polytechnique, developed NewtonRewards, a post-training framework that integrates verifiable, rule-based rewards to instill Newtonian physics into video generation models. This method significantly improved physical plausibility, motion smoothness, and temporal coherence, reducing velocity RMSE by +5.87% and acceleration RMSE by +8.46% on a custom NewtonBench-60K dataset.

01 Dec 2025
We study abstract visual composition, in which identity is primarily determined by the spatial configuration and relations among a small set of geometric primitives (e.g., parts, symmetry, topology). They are invariant primarily to texture and photorealistic detail. Composing such structures from fixed components under geometric constraints and vague goal specification (such as text) is non-trivial due to combinatorial placement choices, limited data, and discrete feasibility (overlap-free, allowable orientations), which create a sparse solution manifold ill-suited to purely statistical pixel-space generators. We propose a constraint-guided framework that combines explicit geometric reasoning with neural semantics. An AlphaGo-style search enforces feasibility, while a fine-tuned vision-language model scores semantic alignment as reward signals. Our algorithm uses a policy network as a heuristic in Monte-Carlo Tree Search and fine-tunes the network via search-generated plans. Inspired by the Generative Adversarial Network, we use the generated instances for adversarial reward refinement. Over time, the generation should approach the actual data more closely when the reward model cannot distinguish between generated instances and ground-truth. In the Tangram Assembly task, our approach yields higher validity and semantic fidelity than diffusion and auto-regressive baselines, especially as constraints tighten.

03 Dec 2025

The LAMP framework employs Large Language Models to convert natural language instructions into precise 3D object and camera trajectories, which then guide a video diffusion model. This approach generates high-fidelity videos with coordinated motion by translating human directorial intent into a cinematography-inspired Domain-Specific Language, offering enhanced control for content creation.

27 Nov 2025


The Geometrically-Constrained Agent (GCA) enables Vision Language Models to perform high-fidelity spatial reasoning by introducing a formal task constraint that decouples semantic analysis from geometric computation. This training-free agentic paradigm achieves state-of-the-art accuracy, outperforming existing baselines by up to 38% on complex spatial reasoning benchmarks.
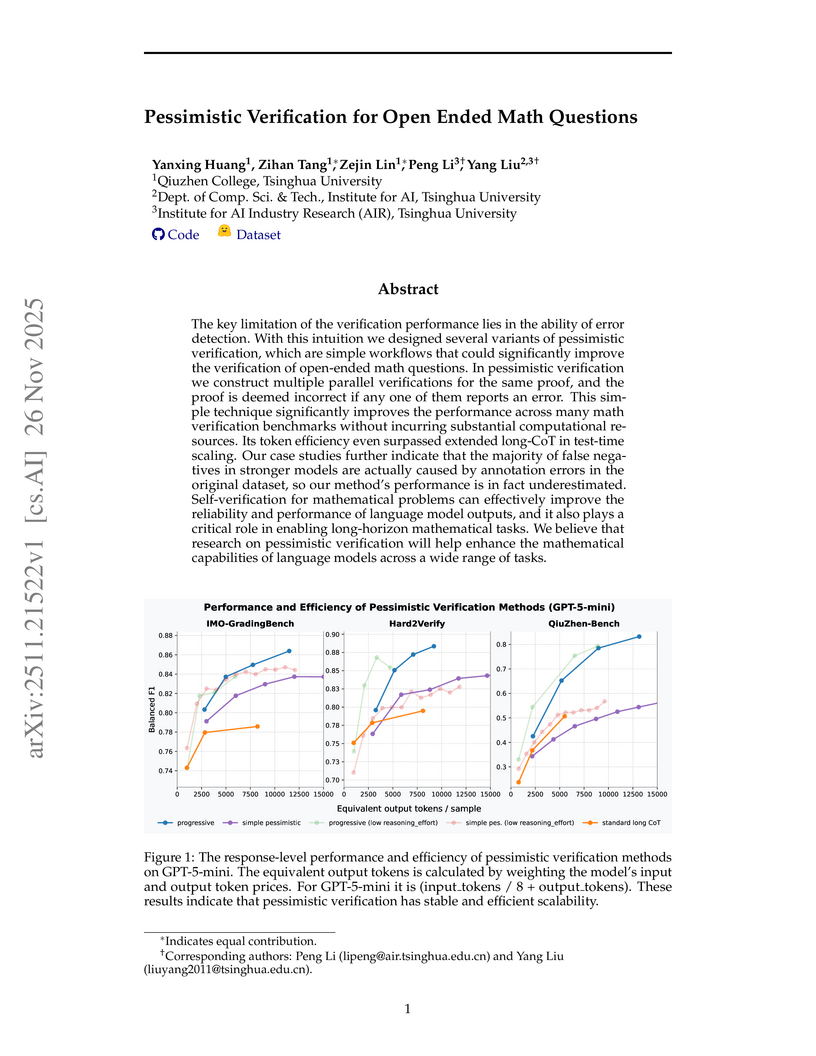
26 Nov 2025
Tsinghua University researchers introduced pessimistic verification workflows to significantly improve large language models' error detection in open-ended mathematical proofs, yielding higher accuracy and efficiency than prior methods. This approach enhanced True Negative Rates and Balanced F1 scores across various models and uncovered instances where stronger models correctly identified errors missed in existing benchmark annotations.

29 Nov 2025
VCWorld, a biological world model developed by researchers at Shanghai Jiao Tong University and NeoLife AI, simulates cellular responses to drug perturbations by integrating an open-world biological knowledge graph with large language model-driven reasoning. This model provides interpretable, stepwise predictions and mechanistic hypotheses, achieving state-of-the-art predictive performance on a new gene-centric benchmark while enhancing data efficiency.

03 Dec 2025
Machine learning for early prediction in medicine has recently shown breakthrough performance, however, the focus on improving prediction accuracy has led to a neglect of faithful explanations that are required to gain the trust of medical practitioners. The goal of this paper is to teach LLMs to follow medical consensus guidelines step-by-step in their reasoning and prediction process. Since consensus guidelines are ubiquitous in medicine, instantiations of verbalized medical inference rules to electronic health records provide data for fine-tuning LLMs to learn consensus rules and possible exceptions thereof for many medical areas. Consensus rules also enable an automatic evaluation of the model's inference process regarding its derivation correctness (evaluating correct and faithful deduction of a conclusion from given premises) and value correctness (comparing predicted values against real-world measurements). We exemplify our work using the complex Sepsis-3 consensus definition. Our experiments show that small fine-tuned models outperform one-shot learning of considerably larger LLMs that are prompted with the explicit definition and models that are trained on medical texts including consensus definitions. Since fine-tuning on verbalized rule instantiations of a specific medical area yields nearly perfect derivation correctness for rules (and exceptions) on unseen patient data in that area, the bottleneck for early prediction is not out-of-distribution generalization, but the orthogonal problem of generalization into the future by forecasting sparsely and irregularly sampled clinical variables. We show that the latter results can be improved by integrating the output representations of a time series forecasting model with the LLM in a multimodal setup.

27 Nov 2025
Current AI paradigms, as "architects of experience," face fundamental challenges in explainability and value alignment. This paper introduces "Weight-Calculatism," a novel cognitive architecture grounded in first principles, and demonstrates its potential as a viable pathway toward Artificial General Intelligence (AGI). The architecture deconstructs cognition into indivisible Logical Atoms and two fundamental operations: Pointing and Comparison. Decision-making is formalized through an interpretable Weight-Calculation model (Weight = Benefit * Probability), where all values are traceable to an auditable set of Initial Weights. This atomic decomposition enables radical explainability, intrinsic generality for novel situations, and traceable value alignment. We detail its implementation via a graph-algorithm-based computational engine and a global workspace workflow, supported by a preliminary code implementation and scenario validation. Results indicate that the architecture achieves transparent, human-like reasoning and robust learning in unprecedented scenarios, establishing a practical and theoretical foundation for building trustworthy and aligned AGI.
There are no more papers matching your filters at the moment.
