
08 Dec 2025
Researchers from University of Wisconsin-Madison, UCLA, and Adobe Research introduce a computational framework for "relational visual similarity," which identifies image commonalities based on abstract logic rather than surface features. Their `relsim` model, trained on a novel dataset of images paired with anonymous group-derived captions, aligns significantly with human perception of relational similarity and outperforms existing attribute-based metrics in retrieval tasks.

10 Dec 2025





ReViSE introduces a framework for reason-informed video editing that integrates self-reflective learning to overcome the limitations of current models in handling complex, reasoning-driven instructions. The approach establishes a new benchmark, RVE-Bench, and achieves improved performance, with a 38% gain in overall score for temporal reasoning compared to prior state-of-the-art methods.

09 Dec 2025

VALOR, developed at Caltech, presents an annotation-free framework that trains visual reasoners by employing multimodal verifiers to jointly tune an LLM for reasoning and specialized vision tools for visual grounding. This approach achieves superior performance on various visual reasoning benchmarks, including a 6.5% average improvement over direct-answer VLMs on OMNI3D-BENCH.

03 Dec 2025

Researchers from Zhejiang University and ByteDance introduced CodeVision, a "code-as-tool" framework that equips Multimodal Large Language Models (MLLMs) to programmatically interact with images. The approach significantly improves MLLM robustness by correcting common image corruptions and enables state-of-the-art multi-tool reasoning through emergent tool use and error recovery.

09 Dec 2025


The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.

09 Dec 2025
Thinking-with-images paradigms have showcased remarkable visual reasoning capability by integrating visual information as dynamic elements into the Chain-of-Thought (CoT). However, optimizing interleaved multimodal CoT (iMCoT) through reinforcement learning remains challenging, as it relies on scarce high-quality reasoning data. In this study, we propose Self-Calling Chain-of-Thought (sCoT), a novel visual reasoning paradigm that reformulates iMCoT as a language-only CoT with self-calling. Specifically, a main agent decomposes the complex visual reasoning task to atomic subtasks and invokes its virtual replicas, i.e. parameter-sharing subagents, to solve them in isolated context. sCoT enjoys substantial training effectiveness and efficiency, as it requires no explicit interleaving between modalities. sCoT employs group-relative policy optimization to reinforce effective reasoning behavior to enhance optimization. Experiments on HR-Bench 4K show that sCoT improves the overall reasoning performance by up to with fewer GPU hours compared to strong baseline approaches. Code is available at this https URL.

08 Dec 2025
Vision-language models (VLMs) frequently generate hallucinated content plausible but incorrect claims about image content. We propose a training-free self-correction framework enabling VLMs to iteratively refine responses through uncertainty-guided visual re-attention. Our method combines multidimensional uncertainty quantification (token entropy, attention dispersion, semantic consistency, claim confidence) with attention-guided cropping of under-explored regions. Operating entirely with frozen, pretrained VLMs, our framework requires no gradient updates. We validate our approach on the POPE and MMHAL BENCH benchmarks using the Qwen2.5-VL-7B [23] architecture. Experimental results demonstrate that our method reduces hallucination rates by 9.8 percentage points compared to the baseline, while improving object existence accuracy by 4.7 points on adversarial splits. Furthermore, qualitative analysis confirms that uncertainty-guided re-attention successfully grounds corrections in visual evidence where standard decoding fails. We validate our approach on Qwen2.5-VL-7B [23], with plans to extend validation across diverse architectures in future versions. We release our code and methodology to facilitate future research in trustworthy multimodal systems.

08 Dec 2025
Specialized visual tools can augment large language models or vision language models with expert knowledge (e.g., grounding, spatial reasoning, medical knowledge, etc.), but knowing which tools to call (and when to call them) can be challenging. We introduce DART, a multi-agent framework that uses disagreements between multiple debating visual agents to identify useful visual tools (e.g., object detection, OCR, spatial reasoning, etc.) that can resolve inter-agent disagreement. These tools allow for fruitful multi-agent discussion by introducing new information, and by providing tool-aligned agreement scores that highlight agents in agreement with expert tools, thereby facilitating discussion. We utilize an aggregator agent to select the best answer by providing the agent outputs and tool information. We test DART on four diverse benchmarks and show that our approach improves over multi-agent debate as well as over single agent tool-calling frameworks, beating the next-strongest baseline (multi-agent debate with a judge model) by 3.4% and 2.4% on A-OKVQA and MMMU respectively. We also find that DART adapts well to new tools in applied domains, with a 1.3% improvement on the M3D medical dataset over other strong tool-calling, single agent, and multi-agent baselines. Additionally, we measure text overlap across rounds to highlight the rich discussion in DART compared to existing multi-agent methods. Finally, we study the tool call distribution, finding that diverse tools are reliably used to help resolve disagreement.

08 Dec 2025
Despite advancements in Multi-modal Large Language Models (MLLMs) for scene understanding, their performance on complex spatial reasoning tasks requiring mental simulation remains significantly limited. Current methods often rely on passive observation of spatial data, failing to internalize an active mental imagery process. To bridge this gap, we propose SpatialDreamer, a reinforcement learning framework that enables spatial reasoning through a closedloop process of active exploration, visual imagination via a world model, and evidence-grounded reasoning. To address the lack of fine-grained reward supervision in longhorizontal reasoning tasks, we propose Geometric Policy Optimization (GeoPO), which introduces tree-structured sampling and step-level reward estimation with geometric consistency constraints. Extensive experiments demonstrate that SpatialDreamer delivers highly competitive results across multiple challenging benchmarks, signifying a critical advancement in human-like active spatial mental simulation for MLLMs.

04 Dec 2025



This research introduces the Visual Reasoning Tracer (VRT) task and a corresponding benchmark (VRT-Bench) to compel Multimodal Large Language Models (MLLMs) to reveal their step-by-step reasoning processes, grounded by pixel-level segmentation masks. The R-Sa2VA model, trained on the VRT-80k dataset, successfully generates visually-grounded reasoning traces, achieving high Logical Quality (LQ) and Visual Quality (VQ) scores where baseline MLLMs fail to provide intermediate reasoning.

08 Dec 2025
Chart understanding is crucial for deploying multimodal large language models (MLLMs) in real-world scenarios such as analyzing scientific papers and technical reports. Unlike natural images, charts pair a structured visual layout (spatial property) with an underlying data representation (textual property) -- grasping both is essential for precise, fine-grained chart reasoning. Motivated by this observation, we propose START, the Spatial and Textual learning for chART understanding. Specifically, we introduce (i) chart-element grounding and (ii) chart-to-code generation to strengthen an MLLM's understanding of both chart visual layout and data details. To facilitate spatial and textual learning, we propose the START-Dataset generated with a novel data-generation pipeline that first leverages an MLLM to translate real chart images into executable chart code, recovering the underlying data representation while preserving the visual distribution of real-world charts. We then evolve the code with a Large Language Model (LLM) to ascertain the positions of chart elements that capture the chart's visual structure, addressing challenges that existing methods cannot handle. To evaluate a model's ability to understand chart spatial structures, we propose the Chart Spatial understanding Benchmark (CS-Bench), filling a critical gap in comprehensive chart understanding evaluation. Leveraging spatial and textual learning, START delivers consistent gains across model sizes and benchmarks over the base models and surpasses prior state-of-the-art by a clear margin. Code, data and models will be publicly available.

05 Dec 2025

COOPER, developed by researchers from Chinese Academy of Sciences and Baidu Inc., introduces a unified multimodal large language model that intrinsically generates auxiliary visual cues, such as depth and segmentation maps, and adaptively integrates them with textual reasoning. The model achieves an average 6.91% improvement in spatial reasoning and a 4.47% gain on general multimodal benchmarks, surpassing several larger and proprietary models on specific spatial tasks.

06 Dec 2025
Tool-integrated visual reasoning (TiVR) has demonstrated great potential in enhancing multimodal problem-solving. However, existing TiVR paradigms mainly focus on integrating various visual tools through reinforcement learning, while neglecting to design effective response mechanisms for handling unreliable or erroneous tool outputs. This limitation is particularly pronounced in referring and grounding tasks, where inaccurate detection tool predictions often mislead TiVR models into generating hallucinated reasoning. To address this issue, we propose the VG-Refiner, the first framework aiming at the tool-refined referring grounded reasoning. Technically, we introduce a two-stage think-rethink mechanism that enables the model to explicitly analyze and respond to tool feedback, along with a refinement reward that encourages effective correction in response to poor tool results. In addition, we propose two new metrics and establish fair evaluation protocols to systematically measure the refinement ability of current models. We adopt a small amount of task-specific data to enhance the refinement capability of VG-Refiner, achieving a significant improvement in accuracy and correction ability on referring and reasoning grounding benchmarks while preserving the general capabilities of the pretrained model.
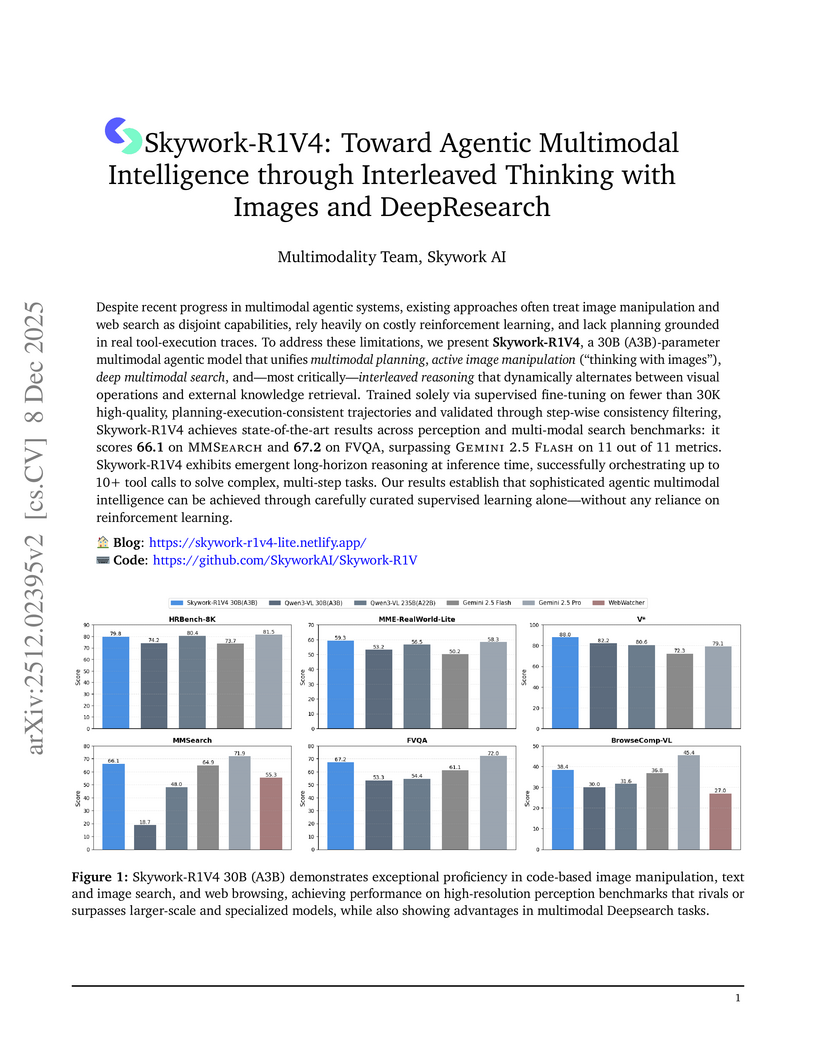
08 Dec 2025
Skywork-R1V4, developed by Skywork AI, introduces a 30B-parameter multimodal agent that unifies planning, active image manipulation, and deep search through interleaved reasoning, achieving state-of-the-art performance using only supervised fine-tuning. The model demonstrates strong perception and multi-modal search capabilities, often outperforming larger proprietary models, with up to a 47.4 percentage point gain on MMSearch.

04 Dec 2025
SpaceMind, developed by Huawei and collaborators, introduces a Camera-Guided Modality Fusion (CGMF) approach that significantly enhances the 3D spatial reasoning capabilities of vision-language models from RGB-only inputs. The model achieves state-of-the-art performance across multiple benchmarks, including an 8.7-point improvement on VSI-Bench, by actively leveraging camera viewpoint information.

01 Dec 2025
Researchers from Shanghai Artificial Intelligence Laboratory developed Envision, a benchmark and evaluation metric to assess how well multimodal generative models understand and simulate dynamic, causally-linked events across multiple images. Their analysis revealed that current models universally struggle with spatial-temporal consistency and physical plausibility in generating these sequences, highlighting a core limitation in their comprehension of real-world dynamics.

08 Dec 2025
Spatio-temporal scene graph generation (ST-SGG) aims to model objects and their evolving relationships across video frames, enabling interpretable representations for downstream reasoning tasks such as video captioning and visual question answering. Despite recent advancements in DETR-style single-stage ST-SGG models, they still suffer from several key limitations. First, while these models rely on attention-based learnable queries as a core component, these learnable queries are semantically uninformed and instance-agnostically initialized. Second, these models rely exclusively on unimodal visual features for predicate classification. To address these challenges, we propose VOST-SGG, a VLM-aided one-stage ST-SGG framework that integrates the common sense reasoning capabilities of vision-language models (VLMs) into the ST-SGG pipeline. First, we introduce the dual-source query initialization strategy that disentangles what to attend to from where to attend, enabling semantically grounded what-where reasoning. Furthermore, we propose a multi-modal feature bank that fuses visual, textual, and spatial cues derived from VLMs for improved predicate classification. Extensive experiments on the Action Genome dataset demonstrate that our approach achieves state-of-the-art performance, validating the effectiveness of integrating VLM-aided semantic priors and multi-modal features for ST-SGG. We will release the code at this https URL.

07 Dec 2025



Cross-view correspondence is a fundamental capability for spatial understanding and embodied AI. However, it is still far from being realized in Vision-Language Models (VLMs), especially in achieving precise point-level correspondence, which is crucial for precise affordance interaction. So we propose the Cross-View Point Correspondence (CVPC) task and CrossPoint-Bench, a comprehensive benchmark with hierarchical design, inspired by the human cognitive process of "perceive", "reason", and "correspond". Our evaluation shows the state-of-the-art models (e.g., Gemini-2.5-Pro) still fall far behind humans, with a gap of over 54.65% in overall accuracy, exposing a challenge in transitioning from coarse-grained judgement to fine-grained coordinate prediction. To address this problem, we construct CrossPoint-378K, a dataset with 378K question-answering pairs across 900 scenes, focused on actionable affordance regions that better reflect real-world manipulation and interaction scenarios. Furthermore, we propose CroPond that trained on the CrossPoint-378K dataset. Our CroPond achieves state-of-the-art performance on CrossPoint-Bench, surpassing Gemini-2.5-Pro by 39.7% accuracy, which offers a foundation for advancing future work on cross-view correspondence. The benchmark, dataset, and model are publicly available at this https URL.

06 Dec 2025
We reveal a critical yet underexplored flaw in Large Vision-Language Models (LVLMs): even when these models know the correct answer, they frequently arrive there through incorrect reasoning paths. The core issue is not a lack of knowledge, but a path selection bias within the vast reasoning search space. Although LVLMs are often capable of sampling correct solution trajectories, they disproportionately favor unstable or logically inconsistent ones, leading to erratic and unreliable outcomes. The substantial disparity between Pass@K (with large K) and Pass@1 across numerous models provides compelling evidence that such failures primarily stem from misreasoning rather than ignorance. To systematically investigate and address this issue, we propose PSO (Path-Select Optimization), a two-stage post-training framework designed to enhance both the reasoning performance and stability of existing LVLMs. In the first stage, we employ Group Relative Policy Optimization (GRPO) with template and answer-based rewards to cultivate structured, step-by-step reasoning. In the second stage, we conduct online preference optimization, where the model samples reasoning paths from GRPO-generated data, self-evaluates them, and aligns itself toward the preferred trajectories. Incorrect or suboptimal paths are concurrently stored in a Negative Replay Memory (NRM) as hard negatives, which are periodically revisited to prevent the model from repeating prior mistakes and to facilitate continual reasoning refinement. Extensive experiments show that PSO effectively prunes invalid reasoning paths, substantially enhances reasoning accuracy (with 7.4% improvements on average), and yields more stable and consistent chains of thought. Our code will be available at this https URL.

05 Dec 2025
CompressARC, developed by researchers at Carnegie Mellon University, addresses the ARC-AGI benchmark by achieving 20% accuracy on evaluation puzzles without any pretraining, learning entirely at inference time from the target puzzle. It leverages a custom equivariant neural network and the Minimum Description Length principle to discover abstract reasoning patterns with extreme data efficiency.
There are no more papers matching your filters at the moment.
