
13 Sep 2024
Remote sensing (RS) change analysis is vital for monitoring Earth's dynamic processes by detecting alterations in images over time. Traditional change detection excels at identifying pixel-level changes but lacks the ability to contextualize these alterations. While recent advancements in change captioning offer natural language descriptions of changes, they do not support interactive, user-specific queries. To address these limitations, we introduce ChangeChat, the first bitemporal vision-language model (VLM) designed specifically for RS change analysis. ChangeChat utilizes multimodal instruction tuning, allowing it to handle complex queries such as change captioning, category-specific quantification, and change localization. To enhance the model's performance, we developed the ChangeChat-87k dataset, which was generated using a combination of rule-based methods and GPT-assisted techniques. Experiments show that ChangeChat offers a comprehensive, interactive solution for RS change analysis, achieving performance comparable to or even better than state-of-the-art (SOTA) methods on specific tasks, and significantly surpassing the latest general-domain model, GPT-4. Code and pre-trained weights are available at this https URL.

23 Sep 2025

The current Large Language Models (LLMs) face significant challenges in improving their performance on low-resource languages and urgently need data-efficient methods without costly fine-tuning. From the perspective of language-bridge, we propose a simple yet effective method, namely BridgeX-ICL, to improve the zero-shot Cross-lingual In-Context Learning (X-ICL) for low-resource languages. Unlike existing works focusing on language-specific neurons, BridgeX-ICL explores whether sharing neurons can improve cross-lingual performance in LLMs. We construct neuron probe data from the ground-truth MUSE bilingual dictionaries, and define a subset of language overlap neurons accordingly to ensure full activation of these anchored neurons. Subsequently, we propose an HSIC-based metric to quantify LLMs' internal linguistic spectrum based on overlapping neurons, guiding optimal bridge selection. The experiments conducted on 4 cross-lingual tasks and 15 language pairs from 7 diverse families, covering both high-low and moderate-low pairs, validate the effectiveness of BridgeX-ICL and offer empirical insights into the underlying multilingual mechanisms of LLMs. The code is publicly available at this https URL.

04 Mar 2025
This survey provides a comprehensive review of implicit bias in Large Language Models (LLMs), drawing parallels to human psychology to define how LLMs acquire subtle, unconscious associations. The paper proposes novel taxonomies for detection methods, evaluation metrics, and relevant datasets, while also highlighting the limited efficacy of current explicit bias mitigation techniques in addressing implicit forms.

04 Jun 2024
 University of Waterloo
University of Waterloo Chinese Academy of Sciences
Chinese Academy of Sciences University of Manchester
University of Manchester National University of Singapore
National University of Singapore Beihang University
Beihang University Zhejiang UniversityOhio State University
Zhejiang UniversityOhio State University Peking University
Peking University HKUST
HKUST Queen Mary University of LondonBeijing Foreign Studies Universityharmony.aiAIWaves Inc.Stardust.AISchool of Artificial Intelligence, Chinese Academy of Sciencesm-a-p.ai
Queen Mary University of LondonBeijing Foreign Studies Universityharmony.aiAIWaves Inc.Stardust.AISchool of Artificial Intelligence, Chinese Academy of Sciencesm-a-p.ai

CIF-Bench introduces a comprehensive Chinese instruction-following benchmark to rigorously evaluate the zero-shot generalizability of large language models (LLMs). The benchmark, comprising 150 tasks and 45,000 data instances, demonstrates that current LLMs exhibit limited generalization capabilities in Chinese, with the top model achieving only 52.9%, and reveals significant issues with data contamination and reduced transferability to novel, culturally-specific tasks.

30 Jul 2025
Accurate interpretation of land-cover changes in multi-temporal satellite imagery is critical for real-world scenarios. However, existing methods typically provide only one-shot change masks or static captions, limiting their ability to support interactive, query-driven analysis. In this work, we introduce remote sensing image change analysis (RSICA) as a new paradigm that combines the strengths of change detection and visual question answering to enable multi-turn, instruction-guided exploration of changes in bi-temporal remote sensing images. To support this task, we construct ChangeChat-105k, a large-scale instruction-following dataset, generated through a hybrid rule-based and GPT-assisted process, covering six interaction types: change captioning, classification, quantification, localization, open-ended question answering, and multi-turn dialogues. Building on this dataset, we propose DeltaVLM, an end-to-end architecture tailored for interactive RSICA. DeltaVLM features three innovations: (1) a fine-tuned bi-temporal vision encoder to capture temporal differences; (2) a visual difference perception module with a cross-semantic relation measuring (CSRM) mechanism to interpret changes; and (3) an instruction-guided Q-former to effectively extract query-relevant difference information from visual changes, aligning them with textual instructions. We train DeltaVLM on ChangeChat-105k using a frozen large language model, adapting only the vision and alignment modules to optimize efficiency. Extensive experiments and ablation studies demonstrate that DeltaVLM achieves state-of-the-art performance on both single-turn captioning and multi-turn interactive change analysis, outperforming existing multimodal large language models and remote sensing vision-language models. Code, dataset and pre-trained weights are available at this https URL.

25 Mar 2025
Recent advancements in diffusion models (DMs) have greatly advanced remote
sensing image super-resolution (RSISR). However, their iterative sampling
processes often result in slow inference speeds, limiting their application in
real-time tasks. To address this challenge, we propose the latent consistency
model for super-resolution (LCMSR), a novel single-step diffusion approach
designed to enhance both efficiency and visual quality in RSISR tasks. Our
proposal is structured into two distinct stages. In the first stage, we
pretrain a residual autoencoder to encode the differential information between
high-resolution (HR) and low-resolution (LR) images, transitioning the
diffusion process into a latent space to reduce computational costs. The second
stage focuses on consistency diffusion learning, which aims to learn the
distribution of residual encodings in the latent space, conditioned on LR
images. The consistency constraint enforces that predictions at any two
timesteps along the reverse diffusion trajectory remain consistent, enabling
direct mapping from noise to data. As a result, the proposed LCMSR reduces the
iterative steps of traditional diffusion models from 50-1000 or more to just a
single step, significantly improving efficiency. Experimental results
demonstrate that LCMSR effectively balances efficiency and performance,
achieving inference times comparable to non-diffusion models while maintaining
high-quality output.

16 May 2025
This study examines the relationship between AI-driven digital transformation
and firm performance in Chinese industrial enterprises, with particular
attention to the mediating role of green digital innovation and the moderating
effects of human-AI collaboration. Using panel data from 6,300 firm-year
observations collected from CNRDS and CSMAR databases between 2015 and 2022, we
employ multiple regression analysis and structural equation modeling to test
our hypotheses. Our findings reveal that AI-driven digital transformation
significantly enhances firm performance, with green digital innovation
mediating this relationship. Furthermore, human-AI collaboration positively
moderates both the direct relationship between digital transformation and firm
performance and the mediating pathway through green digital innovation. The
results provide valuable insights for management practice and policy
formulation in the context of China's evolving industrial landscape and digital
economy initiatives. This research contributes to the literature by integrating
perspectives from technology management, environmental sustainability, and
organizational theory to understand the complex interplay between technological
adoption and business outcomes.

30 Oct 2024
Recent advancements in diffusion models have significantly improved performance in super-resolution (SR) tasks. However, previous research often overlooks the fundamental differences between SR and general image generation. General image generation involves creating images from scratch, while SR focuses specifically on enhancing existing low-resolution (LR) images by adding typically missing high-frequency details. This oversight not only increases the training difficulty but also limits their inference efficiency. Furthermore, previous diffusion-based SR methods are typically trained and inferred at fixed integer scale factors, lacking flexibility to meet the needs of up-sampling with non-integer scale factors. To address these issues, this paper proposes an efficient and elastic diffusion-based SR model (EDiffSR), specially designed for continuous-scale SR in remote sensing imagery. EDiffSR employs a two-stage latent diffusion paradigm. During the first stage, an autoencoder is trained to capture the differential priors between high-resolution (HR) and LR images. The encoder intentionally ignores the existing LR content to alleviate the encoding burden, while the decoder introduces an SR branch equipped with a continuous scale upsampling module to accomplish the reconstruction under the guidance of the differential prior. In the second stage, a conditional diffusion model is learned within the latent space to predict the true differential prior encoding. Experimental results demonstrate that EDiffSR achieves superior objective metrics and visual quality compared to the state-of-the-art SR methods. Additionally, it reduces the inference time of diffusion-based SR methods to a level comparable to that of non-diffusion methods.

06 Jun 2024

In this work, we present the largest benchmark to date on linguistic
acceptability: Multilingual Evaluation of Linguistic Acceptability -- MELA,
with 46K samples covering 10 languages from a diverse set of language families.
We establish LLM baselines on this benchmark, and investigate cross-lingual
transfer in acceptability judgements with XLM-R. In pursuit of multilingual
interpretability, we conduct probing experiments with fine-tuned XLM-R to
explore the process of syntax capability acquisition. Our results show that
GPT-4o exhibits a strong multilingual ability, outperforming fine-tuned XLM-R,
while open-source multilingual models lag behind by a noticeable gap.
Cross-lingual transfer experiments show that transfer in acceptability judgment
is non-trivial: 500 Icelandic fine-tuning examples lead to 23 MCC performance
in a completely unrelated language -- Chinese. Results of our probing
experiments indicate that training on MELA improves the performance of XLM-R on
syntax-related tasks. Our data is available at
https://github.com/sjtu-compling/MELA.

23 Feb 2023

Sentiment transfer aims at revising the input text to satisfy a given
sentiment polarity while retaining the original semantic content. The nucleus
of sentiment transfer lies in precisely separating the sentiment information
from the content information. Existing explicit approaches generally identify
and mask sentiment tokens simply based on prior linguistic knowledge and
manually-defined rules, leading to low generality and undesirable transfer
performance. In this paper, we view the positions to be masked as the learnable
parameters, and further propose a novel AM-ST model to learn adaptive
task-relevant masks based on the attention mechanism. Moreover, a
sentiment-aware masked language model is further proposed to fill in the blanks
in the masked positions by incorporating both context and sentiment polarity to
capture the multi-grained semantics comprehensively. AM-ST is thoroughly
evaluated on two popular datasets, and the experimental results demonstrate the
superiority of our proposal.

09 Dec 2024
Based on the foundation of Large Language Models (LLMs), Multilingual LLMs (MLLMs) have been developed to address the challenges faced in multilingual natural language processing, hoping to achieve knowledge transfer from high-resource languages to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolutions, key techniques, and multilingual capacities. Secondly, we explore the multilingual training corpora of MLLMs and the multilingual datasets oriented for downstream tasks that are crucial to enhance the cross-lingual capability of MLLMs. Thirdly, we survey the state-of-the-art studies of multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs, including its categories, evaluation metrics, and debiasing techniques. Finally, we discuss existing challenges and point out promising research directions of MLLMs.

30 Sep 2025
The primary objective of Chinese grammatical error correction (CGEC) is to detect and correct errors in Chinese sentences. Recent research shows that large language models (LLMs) have been applied to CGEC with significant results. For LLMs, selecting appropriate reference examples can help improve their performance. However, existing methods predominantly rely on text similarity for example retrieval, a strategy that frequently mismatches actual error patterns and retrieves lexically similar yet grammatically irrelevant sentences. To address this problem, we propose a method named RE, which retrieves appropriate examples with explanations of grammatical errors. Instead of using text similarity of the input sentence, we use explanations of grammatical errors to select reference examples, which are used by LLMs to improve the performance of CGEC. We conduct experiments on two CGEC datasets and create a high-quality grammatical error explanation (GEE) dataset, which is not only used in our research but also serves as a valuable resource for future studies in both CGEC and GEE. The experimental results on the two datasets indicate that our proposed method effectively improves the performance of CGEC.
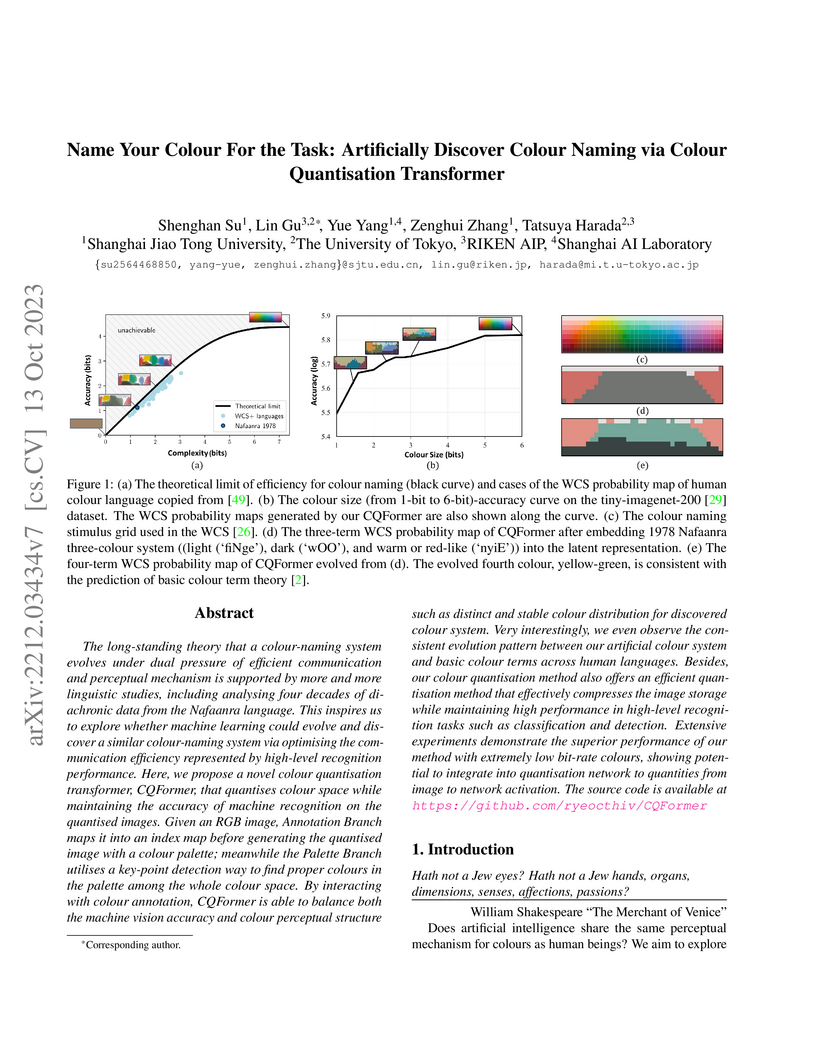
13 Oct 2023

The long-standing theory that a colour-naming system evolves under dual
pressure of efficient communication and perceptual mechanism is supported by
more and more linguistic studies, including analysing four decades of
diachronic data from the Nafaanra language. This inspires us to explore whether
machine learning could evolve and discover a similar colour-naming system via
optimising the communication efficiency represented by high-level recognition
performance. Here, we propose a novel colour quantisation transformer,
CQFormer, that quantises colour space while maintaining the accuracy of machine
recognition on the quantised images. Given an RGB image, Annotation Branch maps
it into an index map before generating the quantised image with a colour
palette; meanwhile the Palette Branch utilises a key-point detection way to
find proper colours in the palette among the whole colour space. By interacting
with colour annotation, CQFormer is able to balance both the machine vision
accuracy and colour perceptual structure such as distinct and stable colour
distribution for discovered colour system. Very interestingly, we even observe
the consistent evolution pattern between our artificial colour system and basic
colour terms across human languages. Besides, our colour quantisation method
also offers an efficient quantisation method that effectively compresses the
image storage while maintaining high performance in high-level recognition
tasks such as classification and detection. Extensive experiments demonstrate
the superior performance of our method with extremely low bit-rate colours,
showing potential to integrate into quantisation network to quantities from
image to network activation. The source code is available at
this https URL

18 Mar 2024
Certain forms of linguistic annotation, like part of speech and semantic
tagging, can be automated with high accuracy. However, manual annotation is
still necessary for complex pragmatic and discursive features that lack a
direct mapping to lexical forms. This manual process is time-consuming and
error-prone, limiting the scalability of function-to-form approaches in corpus
linguistics. To address this, our study explores automating pragma-discursive
corpus annotation using large language models (LLMs). We compare ChatGPT, the
Bing chatbot, and a human coder in annotating apology components in English
based on the local grammar framework. We find that the Bing chatbot
outperformed ChatGPT, with accuracy approaching that of a human coder. These
results suggest that AI can be successfully deployed to aid pragma-discursive
corpus annotation, making the process more efficient and scalable. Keywords:
linguistic annotation, function-to-form approaches, large language models,
local grammar analysis, Bing chatbot, ChatGPT

21 May 2024
Remote sensing image change captioning (RSICC) aims at generating human-like language to describe the semantic changes between bi-temporal remote sensing image pairs. It provides valuable insights into environmental dynamics and land management. Unlike conventional change captioning task, RSICC involves not only retrieving relevant information across different modalities and generating fluent captions, but also mitigating the impact of pixel-level differences on terrain change localization. The pixel problem due to long time span decreases the accuracy of generated caption. Inspired by the remarkable generative power of diffusion model, we propose a probabilistic diffusion model for RSICC to solve the aforementioned problems. In training process, we construct a noise predictor conditioned on cross modal features to learn the distribution from the real caption distribution to the standard Gaussian distribution under the Markov chain. Meanwhile, a cross-mode fusion and a stacking self-attention module are designed for noise predictor in the reverse process. In testing phase, the well-trained noise predictor helps to estimate the mean value of the distribution and generate change captions step by step. Extensive experiments on the LEVIR-CC dataset demonstrate the effectiveness of our Diffusion-RSCC and its individual components. The quantitative results showcase superior performance over existing methods across both traditional and newly augmented metrics. The code and materials will be available online at this https URL.

28 May 2024

Variance reduction techniques are designed to decrease the sampling variance,
thereby accelerating convergence rates of first-order (FO) and zeroth-order
(ZO) optimization methods. However, in composite optimization problems, ZO
methods encounter an additional variance called the coordinate-wise variance,
which stems from the random gradient estimation. To reduce this variance, prior
works require estimating all partial derivatives, essentially approximating FO
information. This approach demands O(d) function evaluations (d is the
dimension size), which incurs substantial computational costs and is
prohibitive in high-dimensional scenarios. This paper proposes the Zeroth-order
Proximal Double Variance Reduction (ZPDVR) method, which utilizes the averaging
trick to reduce both sampling and coordinate-wise variances. Compared to prior
methods, ZPDVR relies solely on random gradient estimates, calls the stochastic
zeroth-order oracle (SZO) in expectation times per iteration,
and achieves the optimal
SZO query complexity in the strongly convex and smooth setting, where
represents the condition number and is the desired accuracy.
Empirical results validate ZPDVR's linear convergence and demonstrate its
superior performance over other related methods.

20 Apr 2025
Despite the impressive performance of large language models (LLMs), they can
present unintended biases and harmful behaviors driven by encoded values,
emphasizing the urgent need to understand the value mechanisms behind them.
However, current research primarily evaluates these values through external
responses with a focus on AI safety, lacking interpretability and failing to
assess social values in real-world contexts. In this paper, we propose a novel
framework called ValueExploration, which aims to explore the behavior-driven
mechanisms of National Social Values within LLMs at the neuron level. As a case
study, we focus on Chinese Social Values and first construct C-voice, a
large-scale bilingual benchmark for identifying and evaluating Chinese Social
Values in LLMs. By leveraging C-voice, we then identify and locate the neurons
responsible for encoding these values according to activation difference.
Finally, by deactivating these neurons, we analyze shifts in model behavior,
uncovering the internal mechanism by which values influence LLM
decision-making. Extensive experiments on four representative LLMs validate the
efficacy of our framework. The benchmark and code will be available.

04 Jun 2025
This study investigates how team collaboration stability influences the
success of mega construction projects in electric vehicle manufacturing
enterprises, with human-AI integration as a moderating variable. Using
structural equation modeling (SEM) with data from 187 project teams across
China's electric vehicle sector, results indicate that team collaboration
stability significantly enhances project success. The moderating effect of
human-AI integration strengthens this relationship, suggesting that enterprises
implementing advanced human-AI collaborative systems achieve superior project
outcomes when team stability is maintained. These findings contribute to both
team collaboration theory and provide practical implications for mega project
management in the rapidly evolving electric vehicle industry.

05 Feb 2025
Simultaneous Machine Translation (SiMT) generates translations while
receiving streaming source inputs. This requires the SiMT model to learn a
read/write policy, deciding when to translate and when to wait for more source
input. Numerous linguistic studies indicate that audiences in SiMT scenarios
have distinct preferences, such as accurate translations, simpler syntax, and
no unnecessary latency. Aligning SiMT models with these human preferences is
crucial to improve their performances. However, this issue still remains
unexplored. Additionally, preference optimization for SiMT task is also
challenging. Existing methods focus solely on optimizing the generated
responses, ignoring human preferences related to latency and the optimization
of read/write policy during the preference optimization phase. To address these
challenges, we propose Simultaneous Preference Learning (SimulPL), a preference
learning framework tailored for the SiMT task. In the SimulPL framework, we
categorize SiMT human preferences into five aspects: \textbf{translation
quality preference}, \textbf{monotonicity preference}, \textbf{key point
preference}, \textbf{simplicity preference}, and \textbf{latency preference}.
By leveraging the first four preferences, we construct human preference prompts
to efficiently guide GPT-4/4o in generating preference data for the SiMT task.
In the preference optimization phase, SimulPL integrates \textbf{latency
preference} into the optimization objective and enables SiMT models to improve
the read/write policy, thereby aligning with human preferences more
effectively. Experimental results indicate that SimulPL exhibits better
alignment with human preferences across all latency levels in
ZhEn, DeEn and EnZh SiMT tasks. Our data
and code will be available at this https URL

04 Nov 2024
One of the most powerful and enduring ideas in written discourse analysis is that genres can be described in terms of the moves which structure a writer's purpose. Considerable research has sought to identify these distinct communicative acts, but analyses have been beset by problems of subjectivity, reliability and the time-consuming need for multiple coders to confirm analyses. In this paper we employ the affordances of GPT-4 to automate the annotation process by using natural language prompts. Focusing on abstracts from articles in four applied linguistics journals, we devise prompts which enable the model to identify moves effectively. The annotated outputs of these prompts were evaluated by two assessors with a third addressing disagreements. The results show that an 8-shot prompt was more effective than one using two, confirming that the inclusion of examples illustrating areas of variability can enhance GPT-4's ability to recognize multiple moves in a single sentence and reduce bias related to textual position. We suggest that GPT-4 offers considerable potential in automating this annotation process, when human actors with domain specific linguistic expertise inform the prompting process.
There are no more papers matching your filters at the moment.
