
01 Aug 2025


A framework called DAPT (Decouple before Align) enhances Vision-Language Model prompt tuning by explicitly disentangling visual foreground and background before aligning with textual features, addressing inherent information asymmetry. The method achieves an average accuracy increase of +1.94% in few-shot classification and improves generalization across base-to-novel classes while boosting data efficiency.

17 Jan 2025
In recent years, No-Reference Point Cloud Quality Assessment (NR-PCQA) research has achieved significant progress. However, existing methods mostly seek a direct mapping function from visual data to the Mean Opinion Score (MOS), which is contradictory to the mechanism of practical subjective evaluation. To address this, we propose a novel language-driven PCQA method named CLIP-PCQA. Considering that human beings prefer to describe visual quality using discrete quality descriptions (e.g., "excellent" and "poor") rather than specific scores, we adopt a retrieval-based mapping strategy to simulate the process of subjective assessment. More specifically, based on the philosophy of CLIP, we calculate the cosine similarity between the visual features and multiple textual features corresponding to different quality descriptions, in which process an effective contrastive loss and learnable prompts are introduced to enhance the feature extraction. Meanwhile, given the personal limitations and bias in subjective experiments, we further covert the feature similarities into probabilities and consider the Opinion Score Distribution (OSD) rather than a single MOS as the final target. Experimental results show that our CLIP-PCQA outperforms other State-Of-The-Art (SOTA) approaches.

14 Jun 2023
Diffusion-based models have shown the merits of generating high-quality visual data while preserving better diversity in recent studies. However, such observation is only justified with curated data distribution, where the data samples are nicely pre-processed to be uniformly distributed in terms of their labels. In practice, a long-tailed data distribution appears more common and how diffusion models perform on such class-imbalanced data remains unknown. In this work, we first investigate this problem and observe significant degradation in both diversity and fidelity when the diffusion model is trained on datasets with class-imbalanced distributions. Especially in tail classes, the generations largely lose diversity and we observe severe mode-collapse issues. To tackle this problem, we set from the hypothesis that the data distribution is not class-balanced, and propose Class-Balancing Diffusion Models (CBDM) that are trained with a distribution adjustment regularizer as a solution. Experiments show that images generated by CBDM exhibit higher diversity and quality in both quantitative and qualitative ways. Our method benchmarked the generation results on CIFAR100/CIFAR100LT dataset and shows outstanding performance on the downstream recognition task.

17 Oct 2024

Fine-tuning on task-specific question-answer pairs is a predominant method
for enhancing the performance of instruction-tuned large language models (LLMs)
on downstream tasks. However, in certain specialized domains, such as
healthcare or harmless content generation, it is nearly impossible to obtain a
large volume of high-quality data that matches the downstream distribution. To
improve the performance of LLMs in data-scarce domains with domain-mismatched
data, we re-evaluated the Transformer architecture and discovered that not all
parameter updates during fine-tuning contribute positively to downstream
performance. Our analysis reveals that within the self-attention and
feed-forward networks, only the fine-tuned attention parameters are
particularly beneficial when the training set's distribution does not fully
align with the test set. Based on this insight, we propose an effective
inference-time intervention method: Training All parameters but Inferring with
only Attention (\trainallInfAttn). We empirically validate \trainallInfAttn
using two general instruction-tuning datasets and evaluate it on seven
downstream tasks involving math, reasoning, and knowledge understanding across
LLMs of different parameter sizes and fine-tuning techniques. Our comprehensive
experiments demonstrate that \trainallInfAttn achieves superior improvements
compared to both the fully fine-tuned model and the base model in most
scenarios, with significant performance gains. The high tolerance of
\trainallInfAttn to data mismatches makes it resistant to jailbreaking tuning
and enhances specialized tasks using general data. Code is available in
\url{this https URL}.

04 Sep 2024
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: this https URL.

03 Sep 2024
Recently, NVS in human-object interaction scenes has received increasing
attention. Existing human-object interaction datasets mainly consist of static
data with limited views, offering only RGB images or videos, mostly containing
interactions between a single person and objects. Moreover, these datasets
exhibit complexities in lighting environments, poor synchronization, and low
resolution, hindering high-quality human-object interaction studies. In this
paper, we introduce a new people-object interaction dataset that comprises 38
series of 30-view multi-person or single-person RGB-D video sequences,
accompanied by camera parameters, foreground masks, SMPL models, some point
clouds, and mesh files. Video sequences are captured by 30 Kinect Azures,
uniformly surrounding the scene, each in 4K resolution 25 FPS, and lasting for
119 seconds. Meanwhile, we evaluate some SOTA NVS models on our dataset
to establish the NVS benchmarks. We hope our work can inspire further research
in humanobject interaction.

09 Apr 2025
Vehicle-to-everything-aided autonomous driving (V2X-AD) has a huge potential
to provide a safer driving solution. Despite extensive researches in
transportation and communication to support V2X-AD, the actual utilization of
these infrastructures and communication resources in enhancing driving
performances remains largely unexplored. This highlights the necessity of
collaborative autonomous driving: a machine learning approach that optimizes
the information sharing strategy to improve the driving performance of each
vehicle. This effort necessitates two key foundations: a platform capable of
generating data to facilitate the training and testing of V2X-AD, and a
comprehensive system that integrates full driving-related functionalities with
mechanisms for information sharing. From the platform perspective, we present
V2Xverse, a comprehensive simulation platform for collaborative autonomous
driving. This platform provides a complete pipeline for collaborative driving.
From the system perspective, we introduce CoDriving, a novel end-to-end
collaborative driving system that properly integrates V2X communication over
the entire autonomous pipeline, promoting driving with shared perceptual
information. The core idea is a novel driving-oriented communication strategy.
Leveraging this strategy, CoDriving improves driving performance while
optimizing communication efficiency. We make comprehensive benchmarks with
V2Xverse, analyzing both modular performance and closed-loop driving
performance. Experimental results show that CoDriving: i) significantly
improves the driving score by 62.49% and drastically reduces the pedestrian
collision rate by 53.50% compared to the SOTA end-to-end driving method, and
ii) achieves sustaining driving performance superiority over dynamic constraint
communication conditions.

24 Oct 2025
Reliable image transmission over wireless channels is particularly challenging at extremely low transmission rates, where conventional compression and channel coding schemes fail to preserve adequate visual quality. To address this issue, we propose a generative communication framework based on diffusion models, which integrates joint source channel coding (JSCC) with semantic-guided reconstruction leveraging a pre-trained generative model. Unlike conventional architectures that aim to recover exact pixel values of the original image, the proposed method focuses on preserving and reconstructing semantically meaningful visual content under severely constrained rates, ensuring perceptual plausibility and faithfulness to the scene intent. Specifically, the transmitter encodes the source image via JSCC and jointly transmits it with a textual prompt over the wireless channel. At the receiver, the corrupted low-rate representation is fused with the prompt and reconstructed through a Stable Diffusion model with ControlNet, enabling high-quality visual recovery. Leveraging both generative priors and semantic guidance, the proposed framework produces perceptually convincing images even under extreme bandwidth limitations. Experimental results demonstrate that the proposed method consistently outperforms conventional coding-based schemes and deep learning baselines, achieving superior perceptual quality and robustness across various channel conditions.

31 Dec 2022
Unmanned aerial vehicle (UAV) tracking is of great significance for a wide range of applications, such as delivery and agriculture. Previous benchmarks in this area mainly focused on small-scale tracking problems while ignoring the amounts of data, types of data modalities, diversities of target categories and scenarios, and evaluation protocols involved, greatly hiding the massive power of deep UAV tracking. In this work, we propose WebUAV-3M, the largest public UAV tracking benchmark to date, to facilitate both the development and evaluation of deep UAV trackers. WebUAV-3M contains over 3.3 million frames across 4,500 videos and offers 223 highly diverse target categories. Each video is densely annotated with bounding boxes by an efficient and scalable semiautomatic target annotation (SATA) pipeline. Importantly, to take advantage of the complementary superiority of language and audio, we enrich WebUAV-3M by innovatively providing both natural language specifications and audio descriptions. We believe that such additions will greatly boost future research in terms of exploring language features and audio cues for multimodal UAV tracking. In addition, a fine-grained UAV tracking-under-scenario constraint (UTUSC) evaluation protocol and seven challenging scenario subtest sets are constructed to enable the community to develop, adapt and evaluate various types of advanced trackers. We provide extensive evaluations and detailed analyses of 43 representative trackers and envision future research directions in the field of deep UAV tracking and beyond. The dataset, toolkits and baseline results are available at \url{this https URL}.

04 Mar 2024
Novel-view synthesis with sparse input views is important for real-world
applications like AR/VR and autonomous driving. Recent methods have integrated
depth information into NeRFs for sparse input synthesis, leveraging depth prior
for geometric and spatial understanding. However, most existing works tend to
overlook inaccuracies within depth maps and have low time efficiency. To
address these issues, we propose a depth-guided robust and fast point cloud
fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel
grid of features. A point cloud is constructed for each input view,
characterized within the voxel grid using matrices and vectors. We accumulate
the point cloud of each input view to construct the fused point cloud of the
entire scene. Each voxel determines its density and appearance by referring to
the point cloud of the entire scene. Through point cloud fusion and voxel grid
fine-tuning, inaccuracies in depth values are refined or substituted by those
from other views. Moreover, our method can achieve faster reconstruction and
greater compactness through effective vector-matrix decomposition. Experimental
results underline the superior performance and time efficiency of our approach
compared to state-of-the-art baselines.

17 Dec 2020

We propose a novel method based on teacher-student learning framework for 3D
human pose estimation without any 3D annotation or side information. To solve
this unsupervised-learning problem, the teacher network adopts
pose-dictionary-based modeling for regularization to estimate a physically
plausible 3D pose. To handle the decomposition ambiguity in the teacher
network, we propose a cycle-consistent architecture promoting a 3D
rotation-invariant property to train the teacher network. To further improve
the estimation accuracy, the student network adopts a novel graph convolution
network for flexibility to directly estimate the 3D coordinates. Another
cycle-consistent architecture promoting 3D rotation-equivariant property is
adopted to exploit geometry consistency, together with knowledge distillation
from the teacher network to improve the pose estimation performance. We conduct
extensive experiments on Human3.6M and MPI-INF-3DHP. Our method reduces the 3D
joint prediction error by 11.4% compared to state-of-the-art unsupervised
methods and also outperforms many weakly-supervised methods that use side
information on Human3.6M. Code will be available at
this https URL

15 Dec 2024

Multimodal large language models (MLLMs) excel at multimodal perception and understanding, yet their tendency to generate hallucinated or inaccurate responses undermines their trustworthiness. Existing methods have largely overlooked the importance of refusal responses as a means of enhancing MLLMs reliability. To bridge this gap, we present the Information Boundary-aware Learning Framework (InBoL), a novel approach that empowers MLLMs to refuse to answer user queries when encountering insufficient information. To the best of our knowledge, InBoL is the first framework that systematically defines the conditions under which refusal is appropriate for MLLMs using the concept of information boundaries proposed in our paper. This framework introduces a comprehensive data generation pipeline and tailored training strategies to improve the model's ability to deliver appropriate refusal responses. To evaluate the trustworthiness of MLLMs, we further propose a user-centric alignment goal along with corresponding metrics. Experimental results demonstrate a significant improvement in refusal accuracy without noticeably compromising the model's helpfulness, establishing InBoL as a pivotal advancement in building more trustworthy MLLMs.

10 Feb 2017

Learning the spatial-temporal representation of motion information is crucial to human action recognition. Nevertheless, most of the existing features or descriptors cannot capture motion information effectively, especially for long-term motion. To address this problem, this paper proposes a long-term motion descriptor called sequential Deep Trajectory Descriptor (sDTD). Specifically, we project dense trajectories into two-dimensional planes, and subsequently a CNN-RNN network is employed to learn an effective representation for long-term motion. Unlike the popular two-stream ConvNets, the sDTD stream is introduced into a three-stream framework so as to identify actions from a video sequence. Consequently, this three-stream framework can simultaneously capture static spatial features, short-term motion and long-term motion in the video. Extensive experiments were conducted on three challenging datasets: KTH, HMDB51 and UCF101. Experimental results show that our method achieves state-of-the-art performance on the KTH and UCF101 datasets, and is comparable to the state-of-the-art methods on the HMDB51 dataset.

31 Oct 2017
Clothing retrieval is a challenging problem in computer vision. With the
advance of Convolutional Neural Networks (CNNs), the accuracy of clothing
retrieval has been significantly improved. FashionNet[1], a recent study,
proposes to employ a set of artificial features in the form of landmarks for
clothing retrieval, which are shown to be helpful for retrieval. However, the
landmark detection module is trained with strong supervision which requires
considerable efforts to obtain. In this paper, we propose a self-learning
Visual Attention Model (VAM) to extract attention maps from clothing images.
The VAM is further connected to a global network to form an end-to-end network
structure through Impdrop connection which randomly Dropout on the feature maps
with the probabilities given by the attention map. Extensive experiments on
several widely used benchmark clothing retrieval data sets have demonstrated
the promise of the proposed method. We also show that compared to the trivial
Product connection, the Impdrop connection makes the network structure more
robust when training sets of limited size are used.
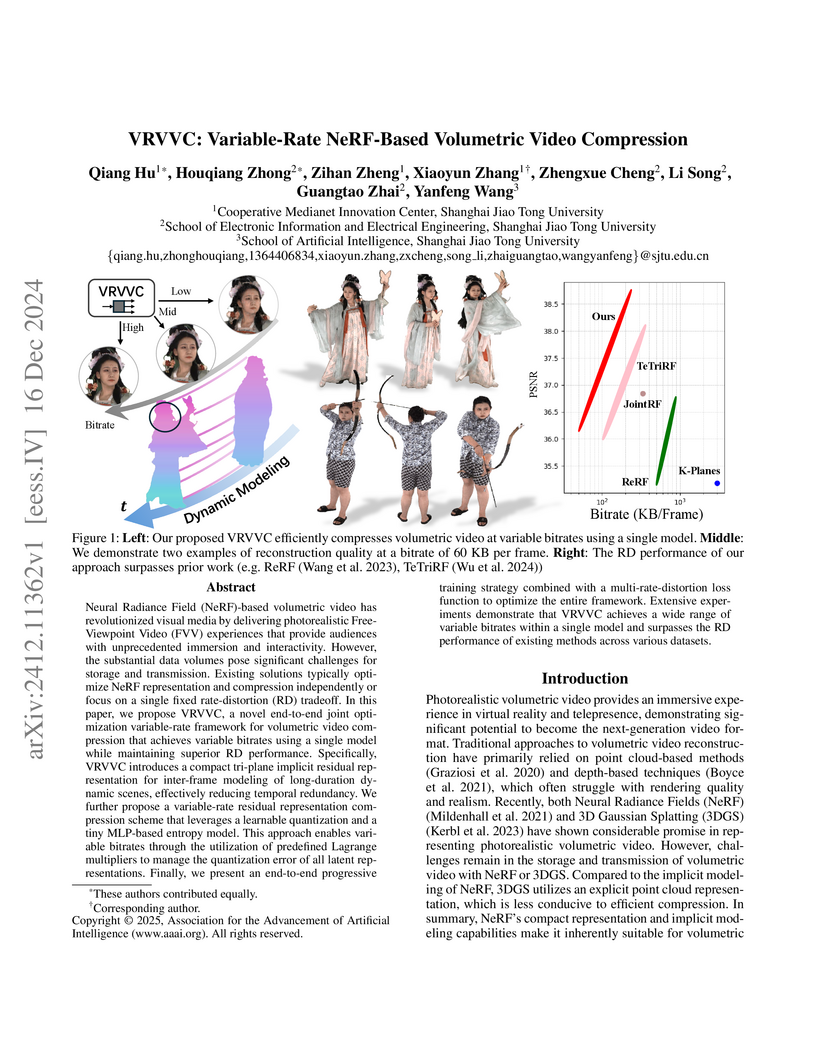
16 Dec 2024
Neural Radiance Field (NeRF)-based volumetric video has revolutionized visual media by delivering photorealistic Free-Viewpoint Video (FVV) experiences that provide audiences with unprecedented immersion and interactivity. However, the substantial data volumes pose significant challenges for storage and transmission. Existing solutions typically optimize NeRF representation and compression independently or focus on a single fixed rate-distortion (RD) tradeoff. In this paper, we propose VRVVC, a novel end-to-end joint optimization variable-rate framework for volumetric video compression that achieves variable bitrates using a single model while maintaining superior RD performance. Specifically, VRVVC introduces a compact tri-plane implicit residual representation for inter-frame modeling of long-duration dynamic scenes, effectively reducing temporal redundancy. We further propose a variable-rate residual representation compression scheme that leverages a learnable quantization and a tiny MLP-based entropy model. This approach enables variable bitrates through the utilization of predefined Lagrange multipliers to manage the quantization error of all latent representations. Finally, we present an end-to-end progressive training strategy combined with a multi-rate-distortion loss function to optimize the entire framework. Extensive experiments demonstrate that VRVVC achieves a wide range of variable bitrates within a single model and surpasses the RD performance of existing methods across various datasets.

28 Feb 2024
Autoregressive (AR) and Non-autoregressive (NAR) models are two types of
generative models for Neural Machine Translation (NMT). AR models predict
tokens in a word-by-word manner and can effectively capture the distribution of
real translations. NAR models predict tokens by extracting bidirectional
contextual information which can improve the inference speed but they suffer
from performance degradation. Previous works utilized AR models to enhance NAR
models by reducing the training data's complexity or incorporating the global
information into AR models by virtue of NAR models. However, those investigated
methods only take advantage of the contextual information of a single type of
model while neglecting the diversity in the contextual information that can be
provided by different types of models. In this paper, we propose a novel
generic collaborative learning method, DCMCL, where AR and NAR models are
treated as collaborators instead of teachers and students. To hierarchically
leverage the bilateral contextual information, token-level mutual learning and
sequence-level contrastive learning are adopted between AR and NAR models.
Extensive experiments on four widely used benchmarks show that the proposed
DCMCL method can simultaneously improve both AR and NAR models with up to 1.38
and 2.98 BLEU scores respectively, and can also outperform the current
best-unified model with up to 0.97 BLEU scores for both AR and NAR decoding.

19 Mar 2017
Despite a lot of research efforts devoted in recent years, how to efficiently
learn long-term dependencies from sequences still remains a pretty challenging
task. As one of the key models for sequence learning, recurrent neural network
(RNN) and its variants such as long short term memory (LSTM) and gated
recurrent unit (GRU) are still not powerful enough in practice. One possible
reason is that they have only feedforward connections, which is different from
the biological neural system that is typically composed of both feedforward and
feedback connections. To address this problem, this paper proposes a
biologically-inspired deep network, called shuttleNet\footnote{Our code is
available at \url{this https URL}}. Technologically,
the shuttleNet consists of several processors, each of which is a GRU while
associated with multiple groups of cells and states. Unlike traditional RNNs,
all processors inside shuttleNet are loop connected to mimic the brain's
feedforward and feedback connections, in which they are shared across multiple
pathways in the loop connection. Attention mechanism is then employed to select
the best information flow pathway. Extensive experiments conducted on two
benchmark datasets (i.e UCF101 and HMDB51) show that we can beat
state-of-the-art methods by simply embedding shuttleNet into a CNN-RNN
framework.

28 Nov 2017
In this paper, we study the probabilistic caching for an -tier wireless
heterogeneous network (HetNet) using stochastic geometry. A general and
tractable expression of the successful delivery probability (SDP) is first
derived. We then optimize the caching probabilities for maximizing the SDP in
the high signal-to-noise ratio (SNR) regime. The problem is proved to be convex
and solved efficiently. We next establish an interesting connection between
-tier HetNets and single-tier networks. Unlike the single-tier network where
the optimal performance only depends on the cache size, the optimal performance
of -tier HetNets depends also on the BS densities. The performance upper
bound is, however, determined by an equivalent single-tier network. We further
show that with uniform caching probabilities regardless of content
popularities, to achieve a target SDP, the BS density of a tier can be reduced
by increasing the cache size of the tier when the cache size is larger than a
threshold; otherwise the BS density and BS cache size can be increased
simultaneously. It is also found analytically that the BS density of a tier is
inverse to the BS cache size of the same tier and is linear to BS cache sizes
of other tiers.

03 Nov 2015
In this paper, we devise the optimal caching placement to maximize the
offloading probability for a two-tier wireless caching system, where the
helpers and a part of users have caching ability. The offloading comes from the
local caching, D2D sharing and the helper transmission. In particular, to
maximize the offloading probability we reformulate the caching placement
problem for users and helpers into a difference of convex (DC) problem which
can be effectively solved by DC programming. Moreover, we analyze the two
extreme cases where there is only help-tier caching network and only user-tier.
Specifically, the placement problem for the helper-tier caching network is
reduced to a convex problem, and can be effectively solved by the classical
water-filling method. We notice that users and helpers prefer to cache popular
contents under low node density and prefer to cache different contents evenly
under high node density. Simulation results indicate a great performance gain
of the proposed caching placement over existing approaches.

24 Sep 2021
Human pose transfer has typically been modeled as a 2D image-to-image
translation problem. This formulation ignores the human body shape prior in 3D
space and inevitably causes implausible artifacts, especially when facing
occlusion. To address this issue, we propose a lifting-and-projection framework
to perform pose transfer in the 3D mesh space. The core of our framework is a
foreground generation module, that consists of two novel networks: a
lifting-and-projection network (LPNet) and an appearance detail compensating
network (ADCNet). To leverage the human body shape prior, LPNet exploits the
topological information of the body mesh to learn an expressive visual
representation for the target person in the 3D mesh space. To preserve texture
details, ADCNet is further introduced to enhance the feature produced by LPNet
with the source foreground image. Such design of the foreground generation
module enables the model to better handle difficult cases such as those with
occlusions. Experiments on the iPER and Fashion datasets empirically
demonstrate that the proposed lifting-and-projection framework is effective and
outperforms the existing image-to-image-based and mesh-based methods on human
pose transfer task in both self-transfer and cross-transfer settings.
There are no more papers matching your filters at the moment.
