
15 Apr 2025




AFLOW introduces an automated framework for generating and optimizing agentic workflows for Large Language Models, reformulating workflow optimization as a search problem over code-represented workflows. The system leverages Monte Carlo Tree Search with LLM-based optimization to iteratively refine workflows, yielding a 19.5% average performance improvement over existing automated methods while enabling smaller, more cost-effective LLMs to achieve performance parity with larger models.

01 Nov 2024

MetaGPT introduces a meta-programming framework that simulates a software company with specialized LLM agents following Standardized Operating Procedures (SOPs) and an assembly line paradigm. The system significantly improves the coherence, accuracy, and executability of generated code for complex software development tasks, achieving state-of-the-art results on benchmarks like HumanEval and MBPP, and outperforming other multi-agent systems on a comprehensive software development dataset.

24 Nov 2025



VR-Bench, a new benchmark, is introduced to evaluate the spatial reasoning capabilities of video generation models through diverse maze-solving tasks. The paper demonstrates that fine-tuned video models can perform robust spatial reasoning, often outperforming Vision-Language Models, and exhibit strong generalization and a notable test-time scaling effect.

21 Aug 2025


A collaborative team from DeepWisdom and The Hong Kong University of Science and Technology (Guangzhou) developed Self-Supervised Prompt Optimization (SPO), a framework for automatically refining prompts for Large Language Models without requiring ground truth or human feedback. SPO achieves comparable or superior performance to state-of-the-art methods on both closed and open-ended tasks, doing so at an average optimization cost of $0.15 per dataset.

03 Dec 2025

Humans naturally adapt to diverse environments by learning underlying rules across worlds with different dynamics, observations, and reward structures. In contrast, existing agents typically demonstrate improvements via self-evolving within a single domain, implicitly assuming a fixed environment distribution. Cross-environment learning has remained largely unmeasured: there is no standard collection of controllable, heterogeneous environments, nor a unified way to represent how agents learn. We address these gaps in two steps. First, we propose AutoEnv, an automated framework that treats environments as factorizable distributions over transitions, observations, and rewards, enabling low-cost (4.12 USD on average) generation of heterogeneous worlds. Using AutoEnv, we construct AutoEnv-36, a dataset of 36 environments with 358 validated levels, on which seven language models achieve 12-49% normalized reward, demonstrating the challenge of AutoEnv-36. Second, we formalize agent learning as a component-centric process driven by three stages of Selection, Optimization, and Evaluation applied to an improvable agent component. Using this formulation, we design eight learning methods and evaluate them on AutoEnv-36. Empirically, the gain of any single learning method quickly decrease as the number of environments increases, revealing that fixed learning methods do not scale across heterogeneous environments. Environment-adaptive selection of learning methods substantially improves performance but exhibits diminishing returns as the method space expands. These results highlight both the necessity and the current limitations of agent learning for scalable cross-environment generalization, and position AutoEnv and AutoEnv-36 as a testbed for studying cross-environment agent learning. The code is avaiable at this https URL.

15 Oct 2024
 Chinese Academy of Sciences
Chinese Academy of Sciences University of Notre Dame
University of Notre Dame Fudan University
Fudan University Renmin University of ChinaThe Chinese University of Hong Kong, Shenzhen
Renmin University of ChinaThe Chinese University of Hong Kong, Shenzhen Yale UniversityXiamen University
Yale UniversityXiamen University The University of Hong KongBeijing University of TechnologyKing Abdullah University of Science and TechnologyEast China Normal UniversityHohai UniversityDeepWisdom
The University of Hong KongBeijing University of TechnologyKing Abdullah University of Science and TechnologyEast China Normal UniversityHohai UniversityDeepWisdomData Interpreter is an LLM agent framework developed by DeepWisdom and Mila, designed to automate end-to-end data science workflows through hierarchical planning and dynamic tool integration. It achieved 94.93% accuracy on InfiAgent-DABench with `gpt-4o`, representing a 19.01% absolute improvement over direct `gpt-4o` inference, and scored 0.95 on ML-Benchmark, outperforming AutoGen and OpenDevin while being more cost-efficient.
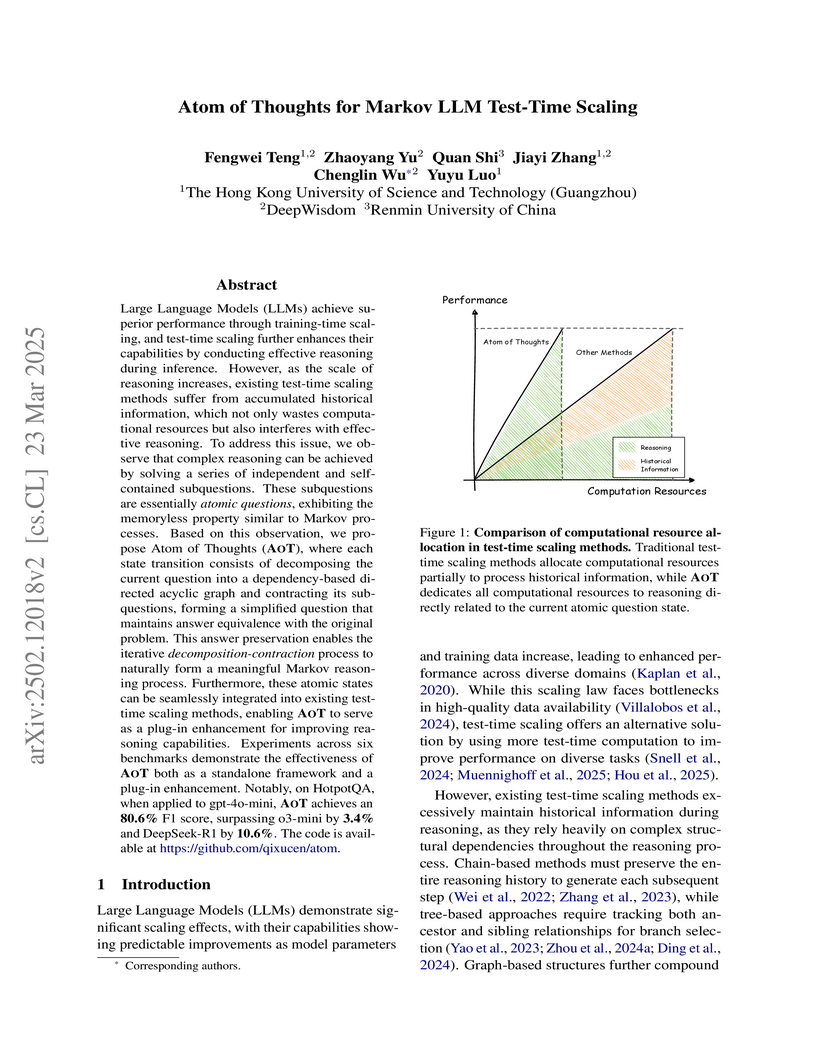
28 Nov 2025
Large Language Models (LLMs) achieve superior performance through training-time scaling, and test-time scaling further enhances their capabilities by conducting effective reasoning during inference. However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with effective reasoning. To address this issue, we observe that complex reasoning can be achieved by solving a series of independent and self-contained subquestions. These subquestions are essentially \textit{atomic questions}, exhibiting the memoryless property similar to Markov processes. Based on this observation, we propose Atom of Thoughts (\our), where each state transition consists of decomposing the current question into a dependency-based directed acyclic graph and contracting its subquestions, forming a simplified question that maintains answer equivalence with the original problem. This answer preservation enables the iterative \textit{decomposition-contraction} process to naturally form a meaningful Markov reasoning process. Furthermore, these atomic states can be seamlessly integrated into existing test-time scaling methods, enabling \our to serve as a plug-in enhancement for improving reasoning capabilities. Experiments across six benchmarks demonstrate the effectiveness of \our both as a standalone framework and a plug-in enhancement. Notably, on HotpotQA, when applied to gpt-4o-mini, \our achieves an \textbf{80.6\%} F1 score, surpassing o3-mini by \textbf{3.4\%} and DeepSeek-R1 by \textbf{10.6\%}. The code is available at \href{this https URL}{this https URL}.

22 Oct 2024




This paper introduces SELA, a tree-search enhanced LLM agent framework that improves automated machine learning by combining LLM capabilities with Monte Carlo Tree Search

26 May 2025

HKUST (Guangzhou) researchers develop LiteCoT, a 100K-sample dataset and corresponding Liter model family that uses Difficulty-Aware Prompting to generate concise, adaptive reasoning traces by first having DeepSeek-R1 assess problem difficulty (easy/medium/hard) then rewrite verbose reasoning chains into shorter versions tailored to each complexity level, with resulting Liter models achieving competitive performance on mathematical reasoning benchmarks while using significantly fewer inference tokens—for instance, Liter-QwQ-32B matches QwQ-32B-Preview accuracy on AIME24 while reducing token usage by over 50%.

17 Aug 2025


The RealDevWorld framework introduces an automated evaluation system for production-ready software generated by large language models, employing interactive GUI testing to assess functional correctness and user experience. It provides a new benchmark, RealDevBench, and an agent-as-a-judge system, AppEvalPilot, which achieved a 0.85 correlation with human assessments, significantly outperforming static evaluation methods.

28 Oct 2024

Large Language Models (LLMs) are proficient at retrieving single facts from extended contexts, yet they struggle with tasks requiring the simultaneous retrieval of multiple facts, especially during generation. This paper identifies a novel "lost-in-the-middle" phenomenon, where LLMs progressively lose track of critical information throughout the generation process, resulting in incomplete or inaccurate retrieval. To address this challenge, we introduce Find All Crucial Texts (FACT), an iterative retrieval method that refines context through successive rounds of rewriting. This approach enables models to capture essential facts incrementally, which are often overlooked in single-pass retrieval. Experiments demonstrate that FACT substantially enhances multi-fact retrieval performance across various tasks, though improvements are less notable in general-purpose QA scenarios. Our findings shed light on the limitations of LLMs in multi-fact retrieval and underscore the need for more resilient long-context retrieval strategies.

15 Apr 2025
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code is available at this https URL.
There are no more papers matching your filters at the moment.
