
28 May 2025

Accurately retargeting facial expressions to a face mesh while enabling manipulation is a key challenge in facial animation retargeting. Recent deep-learning methods address this by encoding facial expressions into a global latent code, but they often fail to capture fine-grained details in local regions. While some methods improve local accuracy by transferring deformations locally, this often complicates overall control of the facial expression. To address this, we propose a method that combines the strengths of both global and local deformation models. Our approach enables intuitive control and detailed expression cloning across diverse face meshes, regardless of their underlying structures. The core idea is to localize the influence of the global latent code on the target mesh. Our model learns to predict skinning weights for each vertex of the target face mesh through indirect supervision from predefined segmentation labels. These predicted weights localize the global latent code, enabling precise and region-specific deformations even for meshes with unseen shapes. We supervise the latent code using Facial Action Coding System (FACS)-based blendshapes to ensure interpretability and allow straightforward editing of the generated animation. Through extensive experiments, we demonstrate improved performance over state-of-the-art methods in terms of expression fidelity, deformation transfer accuracy, and adaptability across diverse mesh structures.
18 Sep 2024

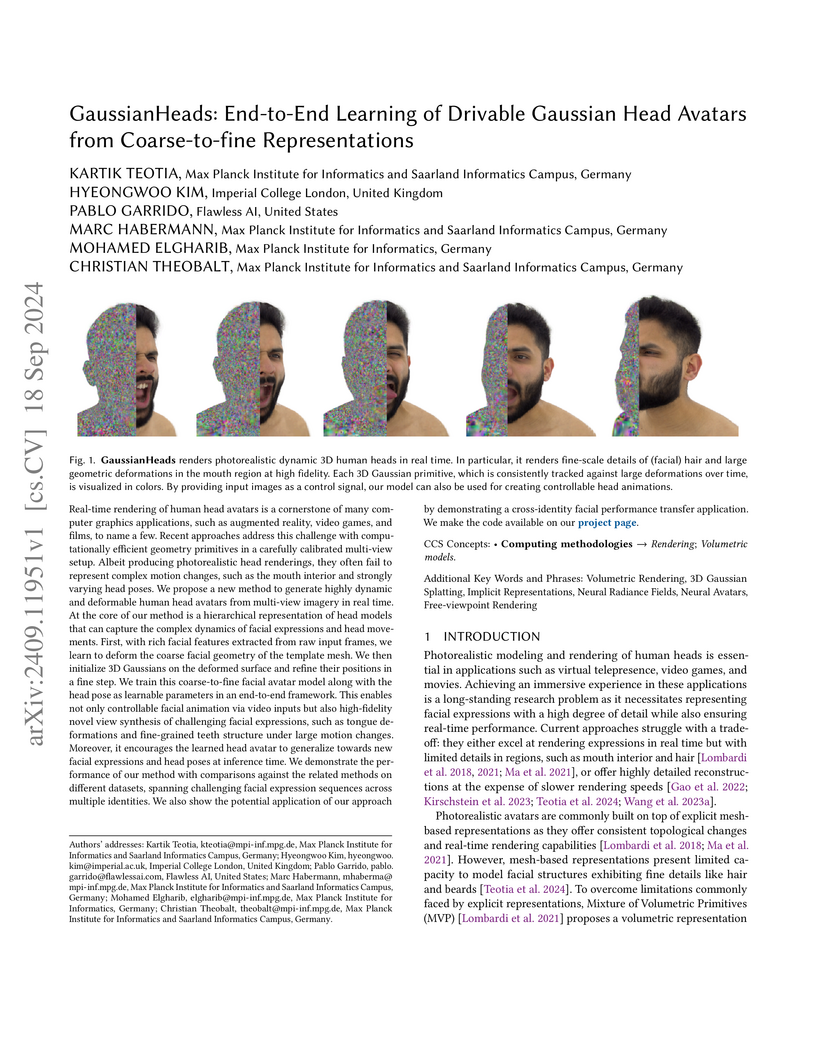
Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.

12 Aug 2025

Prosody conveys rich emotional and semantic information of the speech signal as well as individual idiosyncrasies. We propose a stand-alone model that maps text-to-prosodic features such as F0 and energy and can be used in downstream tasks such as TTS. The ProMode encoder takes as input acoustic features and time-aligned textual content, both are partially masked, and obtains a fixed-length latent prosodic embedding. The decoder predicts acoustics in the masked region using both the encoded prosody input and unmasked textual content. Trained on the GigaSpeech dataset, we compare our method with state-of-the-art style encoders. For F0 and energy predictions, we show consistent improvements for our model at different levels of granularity. We also integrate these predicted prosodic features into a TTS system and conduct perceptual tests, which show higher prosody preference compared to the baselines, demonstrating the model's potential in tasks where prosody modeling is important.

30 May 2024
3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: this https URL

08 Apr 2025
We present an implicit video representation for occlusions, appearance, and
motion disentanglement from monocular videos, which we call Video
SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and
coordinates to deformation and canonical colors, our VideoSPatS maps input
coordinates into Spatial and Color Spline deformation fields and ,
which disentangle motion and appearance in videos. With spline-based
parametrization, our method naturally generates temporally consistent flow and
guarantees long-term temporal consistency, which is crucial for convincing
video editing. Using multiple prediction branches, our VideoSPatS model also
performs layer separation between the latent video and the selected occluder.
By disentangling occlusions, appearance, and motion, our method enables better
spatiotemporal modeling and editing of diverse videos, including in-the-wild
talking head videos with challenging occlusions, shadows, and specularities
while maintaining an appropriate canonical space for editing. We also present
general video modeling results on the DAVIS and CoDeF datasets, as well as our
own talking head video dataset collected from open-source web videos. Extensive
ablations show the combination of and under neural splines can
overcome motion and appearance ambiguities, paving the way for more advanced
video editing models.

25 Mar 2023
Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A common approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms all existing approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research. Our Project page is available at: this https URL

22 Jul 2024
We propose PAV, Personalized Head Avatar for the synthesis of human faces
under arbitrary viewpoints and facial expressions. PAV introduces a method that
learns a dynamic deformable neural radiance field (NeRF), in particular from a
collection of monocular talking face videos of the same character under various
appearance and shape changes. Unlike existing head NeRF methods that are
limited to modeling such input videos on a per-appearance basis, our method
allows for learning multi-appearance NeRFs, introducing appearance embedding
for each input video via learnable latent neural features attached to the
underlying geometry. Furthermore, the proposed appearance-conditioned density
formulation facilitates the shape variation of the character, such as facial
hair and soft tissues, in the radiance field prediction. To the best of our
knowledge, our approach is the first dynamic deformable NeRF framework to model
appearance and shape variations in a single unified network for
multi-appearances of the same subject. We demonstrate experimentally that PAV
outperforms the baseline method in terms of visual rendering quality in our
quantitative and qualitative studies on various subjects.

21 Apr 2023

High-quality reconstruction of controllable 3D head avatars from 2D videos is highly desirable for virtual human applications in movies, games, and telepresence. Neural implicit fields provide a powerful representation to model 3D head avatars with personalized shape, expressions, and facial parts, e.g., hair and mouth interior, that go beyond the linear 3D morphable model (3DMM). However, existing methods do not model faces with fine-scale facial features, or local control of facial parts that extrapolate asymmetric expressions from monocular videos. Further, most condition only on 3DMM parameters with poor(er) locality, and resolve local features with a global neural field. We build on part-based implicit shape models that decompose a global deformation field into local ones. Our novel formulation models multiple implicit deformation fields with local semantic rig-like control via 3DMM-based parameters, and representative facial landmarks. Further, we propose a local control loss and attention mask mechanism that promote sparsity of each learned deformation field. Our formulation renders sharper locally controllable nonlinear deformations than previous implicit monocular approaches, especially mouth interior, asymmetric expressions, and facial details.

25 Sep 2024

We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.

16 Jun 2025

We consider the problem of disentangling 3D from large vision-language
models, which we show on generative 3D portraits. This allows free-form text
control of appearance attributes like age, hair style, and glasses, and 3D
geometry control of face expression and camera pose. In this setting, we assume
we use a pre-trained large vision-language model (LVLM; CLIP) to generate from
a smaller 2D dataset with no additional paired labels and with a pre-defined 3D
morphable model (FLAME). First, we disentangle using canonicalization to a 2D
reference frame from a deformable neural 3D triplane representation. But
another form of entanglement arises from the significant noise in the LVLM's
embedding space that describes irrelevant features. This damages output quality
and diversity, but we overcome this with a Jacobian regularization that can be
computed efficiently with a stochastic approximator. Compared to existing
methods, our approach produces portraits with added text and 3D control, where
portraits remain consistent when either control is changed. Broadly, this
approach lets creators control 3D generators on their own 2D face data without
needing resources to label large data or train large models.

18 Sep 2024
With the rise of digital media content production, the need for analyzing
movies and TV series episodes to locate the main cast of characters precisely
is gaining importance.Specifically, Video Face Clustering aims to group
together detected video face tracks with common facial identities. This problem
is very challenging due to the large range of pose, expression, appearance, and
lighting variations of a given face across video frames. Generic pre-trained
Face Identification (ID) models fail to adapt well to the video production
domain, given its high dynamic range content and also unique cinematic style.
Furthermore, traditional clustering algorithms depend on hyperparameters
requiring individual tuning across datasets. In this paper, we present a novel
video face clustering approach that learns to adapt a generic face ID model to
new video face tracks in a fully self-supervised fashion. We also propose a
parameter-free clustering algorithm that is capable of automatically adapting
to the finetuned model's embedding space for any input video. Due to the lack
of comprehensive movie face clustering benchmarks, we also present a
first-of-kind movie dataset: MovieFaceCluster. Our dataset is handpicked by
film industry professionals and contains extremely challenging face ID
scenarios. Experiments show our method's effectiveness in handling difficult
mainstream movie scenes on our benchmark dataset and state-of-the-art
performance on traditional TV series datasets.

14 Aug 2024
Audio-driven 3D facial animation has several virtual humans applications for content creation and editing. While several existing methods provide solutions for speech-driven animation, precise control over content (what) and style (how) of the final performance is still challenging. We propose a novel approach that takes as input an audio, and the corresponding text to extract temporally-aligned content and disentangled style representations, in order to provide controls over 3D facial animation. Our method is trained in two stages, that evolves from audio prominent styles (how it sounds) to visual prominent styles (how it looks). We leverage a high-resource audio dataset in stage I to learn styles that control speech generation in a self-supervised learning framework, and then fine-tune this model with low-resource audio/3D mesh pairs in stage II to control 3D vertex generation. We employ a non-autoregressive seq2seq formulation to model sentence-level dependencies, and better mouth articulations. Our method provides flexibility that the style of a reference audio and the content of a source audio can be combined to enable audio style transfer. Similarly, the content can be modified, e.g. muting or swapping words, that enables style-preserving content editing.
There are no more papers matching your filters at the moment.
