Ask or search anything...



 Stanford University
Stanford University OpenAI
OpenAIResearchers from the University of Maryland, OpenAI, Stanford University, and other institutions present a systematic survey of prompt engineering, developing a comprehensive taxonomy of 58 LLM prompting techniques and a standardized vocabulary. Their work includes empirical benchmarking on MMLU, which generally shows performance improvements with more complex prompting, and a case study demonstrating that automated prompt optimization can outperform human-designed prompts.
View blog

∞-VIDEO presents a training-free approach that enables existing video-language models to understand arbitrarily long videos by augmenting them with a continuous-time long-term memory consolidation mechanism. This method improves performance on long-video Q&A tasks by dynamically retaining relevant information and avoids the need for additional training or sparse frame subsampling.
View blog

 KAIST
KAIST




 Carnegie Mellon University
Carnegie Mellon University


Unbabel's TOWER+ models demonstrate a successful approach to training multilingual Large Language Models that balance state-of-the-art machine translation performance with robust general-purpose capabilities. These models achieve high scores on both translation benchmarks and general instruction-following tasks like IFEval, often matching or surpassing leading proprietary and open-weight LLMs across various scales.
View blog
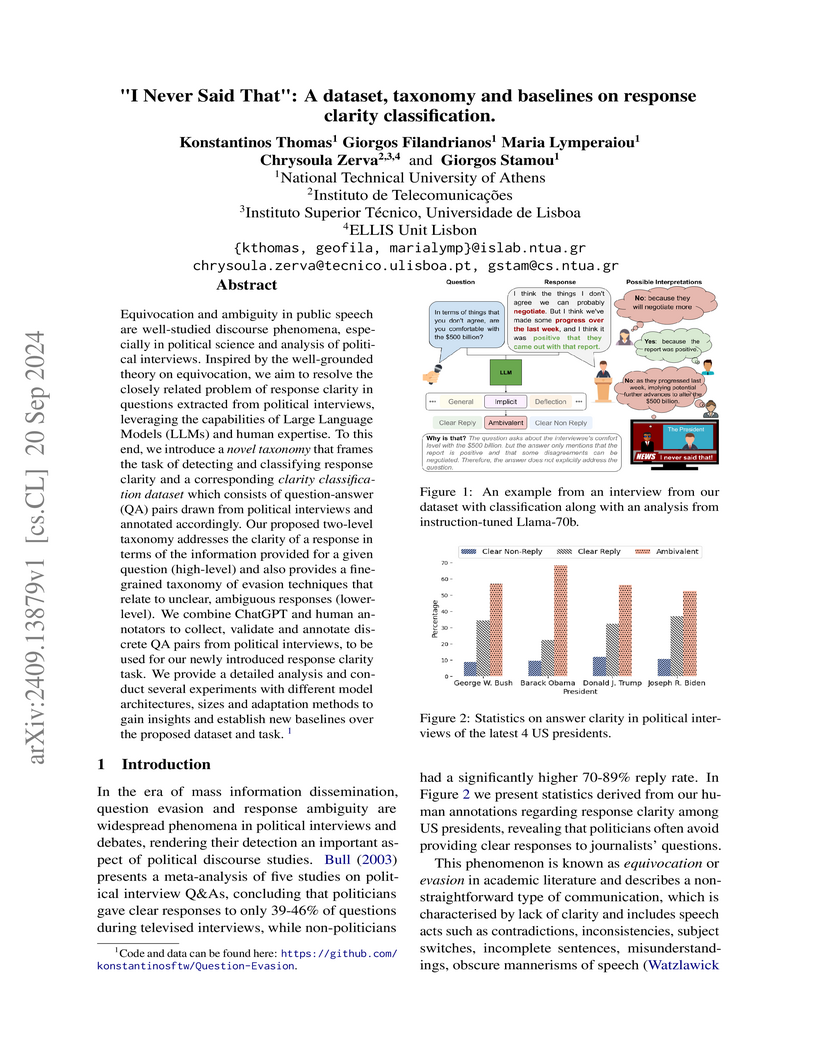
 Google DeepMind
Google DeepMind

This paper presents a controlled study comparing Masked Language Modeling (MLM) and Causal Language Modeling (CLM) as pretraining objectives for text encoders across various model sizes and a fixed data budget. The research finds that while MLM generally yields stronger representations for downstream tasks, a two-stage CLM then MLM approach or continuing pretraining with MLM from a CLM checkpoint delivers optimal performance and improved fine-tuning stability.
View blog


TOWER is an open multilingual large language model family developed by Unbabel and Instituto de Telecomunicações, designed to excel across various translation-related tasks. It was created using a multi-stage training recipe, achieving high translation quality that surpasses other open models and often rivals closed systems like GPT-3.5 and GPT-4 on benchmarks.
View blog
 The University of Texas at Austin
The University of Texas at Austin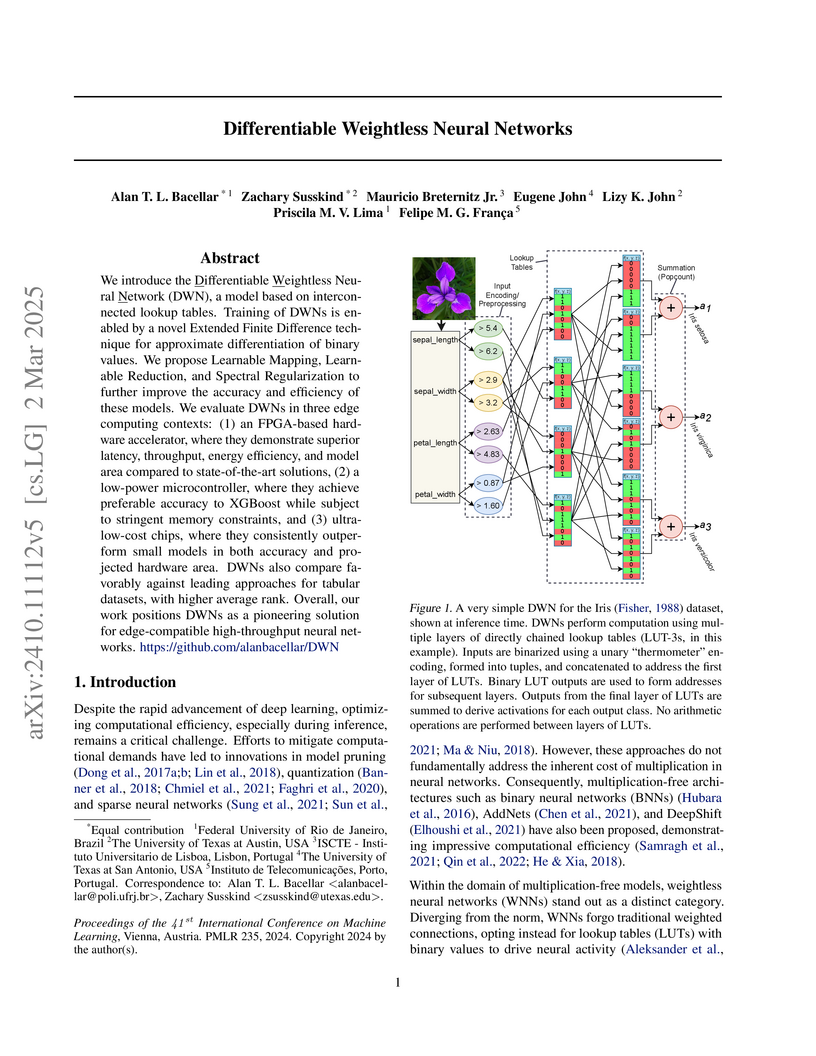


 University of Amsterdam
University of Amsterdam
This survey details the growing application of Conformal Prediction (CP) for uncertainty quantification in Natural Language Processing (NLP), demonstrating how it provides reliable uncertainty estimates with statistical guarantees. It shows CP successfully applied across diverse NLP tasks, including text classification and natural language generation, enhancing model reliability and supporting human-AI collaboration.
View blog