
26 Sep 2021

The Point Transformer adapts Transformer networks for 3D point clouds, achieving new state-of-the-art performance by introducing vector self-attention and a trainable relative position encoding. This architecture notably reached 70.4% mIoU on S3DIS semantic segmentation and 93.7% accuracy on ModelNet40 classification.

28 Oct 2019
Deep Equilibrium Models propose a new paradigm for neural networks where the output is an equilibrium point of a repeated transformation, enabling networks of 'infinite depth.' This approach reduces training memory consumption to a constant, making it feasible to train very deep models that previously exceeded hardware limits.

25 Sep 2025

Researchers from Huazhong University of Science and Technology, in collaboration with Meta and Autel Robotics, developed MonSter++, a unified geometric foundation model for multi-view depth estimation that enhances accuracy by adaptively recovering per-pixel scale and shift for monocular depth priors. The model achieves top ranks on 8 leaderboards, including a 15.91% improvement in EPE on Scene Flow, and a real-time variant runs at over 20 FPS while maintaining state-of-the-art accuracy.

19 Apr 2018
A generic Temporal Convolutional Network (TCN) architecture is empirically shown to consistently outperform canonical recurrent neural networks (RNNs) across a broad spectrum of sequence modeling tasks, demonstrating superior practical memory retention and faster convergence.

12 Mar 2025

Researchers from New York University and Intel Labs developed the PISA benchmark and applied Physics Supervised Fine-Tuning (PSFT) and Object Reward Optimization (ORO) to improve the physical accuracy of video diffusion models when simulating falling objects. Their post-training approach, using a relatively small simulated dataset, significantly reduced trajectory errors and produced more physically plausible motion compared to state-of-the-art baselines like Open-Sora.

26 Mar 2025


MC-LLaVA introduces the first multi-concept personalization paradigm for Vision-Language Models, enabling them to understand and generate responses involving multiple user-defined concepts simultaneously. The model achieves superior recognition accuracy (0.845 for multi-concept) and competitive VQA performance (BLEU 0.658) on a newly contributed dataset, outperforming prior single-concept approaches.

24 Jun 2024
LVLM-Interpret is an interactive tool for Large Vision-Language Models (LVLMs) that integrates attention visualization, relevancy mapping, and causal interpretation methods. It helps diagnose model issues like hallucination by illustrating how specific image patches and text tokens contribute to generated responses. A case study with LLaVA-v1.5-7b demonstrated the model's inconsistent grounding, revealing instances of both text-over-image reliance and robust visual understanding.

03 Apr 2022



Researchers from Cornell, University of Copenhagen, Apple, and Intel Labs developed LSeg, a model that allows semantic segmentation based on natural language descriptions, offering flexible, zero-shot recognition of categories. LSeg outperforms prior zero-shot methods on benchmarks such as PASCAL-5i and COCO-20i, and rivals few-shot techniques while maintaining competitive accuracy on traditional fixed-label tasks.

25 Aug 2020

Researchers from Intel Labs and ETH Zurich developed a robust training framework for monocular depth estimation that effectively combines diverse and incompatible depth datasets. Their methodology, featuring scale- and shift-invariant losses and multi-objective dataset mixing, achieved state-of-the-art performance in zero-shot cross-dataset transfer, enabling superior generalization across varied real-world environments.

02 Sep 2025

Large language models (LLMs), despite their impressive performance across a wide range of tasks, often struggle to balance two competing objectives in open-ended text generation: fostering diversity and creativity while preserving logical coherence. Existing truncated sampling techniques, including temperature scaling, top-\p\ (nucleus) sampling, and min-\p\ sampling, aim to manage this trade-off. However, they exhibit limitations, particularly in the effective incorporation of the confidence of the model into the corresponding sampling strategy. For example, min-\p\ sampling relies on a single top token as a heuristic for confidence, eventually underutilizing the information of the probability distribution. Toward effective incorporation of the confidence of the model, in this paper, we present **top-H** decoding. We first establish the theoretical foundation of the interplay between creativity and coherence in truncated sampling by formulating an **entropy-constrained minimum divergence** problem. We then prove this minimization problem to be equivalent to an **entropy-constrained mass maximization** (ECMM) problem, which is NP-hard. Finally, we present top-H decoding, a computationally efficient greedy algorithm to solve the ECMM problem. Extensive empirical evaluations demonstrate that top-H outperforms the state-of-the-art (SoTA) alternative of min-\p\ sampling by up to **25.63%** on creative writing benchmarks, while maintaining robustness on question-answering datasets such as GPQA, GSM8K, and MT-Bench. Additionally, an *LLM-as-judge* evaluation confirms that top-H indeed produces coherent outputs even at higher temperatures, where creativity is especially critical. In summary, top-H advances SoTA in open-ended text generation and can be *easily integrated* into creative writing applications. The code is available at this https URL.

10 Nov 2017
CARLA, an open-source urban driving simulator developed by Intel Labs, TRI, and CVC, provides a high-fidelity platform for autonomous driving research, demonstrating its utility by benchmarking different driving paradigms and revealing generalization challenges to novel environments.

12 Jul 2024

This survey provides a comprehensive systematization of research on bias and fairness in Large Language Models, formalizing definitions and categorizing existing metrics, datasets, and mitigation techniques. It critically evaluates current methods, identifies their limitations, and outlines key open problems in the field.

02 Mar 2025

Auto-Regressive (AR) models have recently gained prominence in image
generation, often matching or even surpassing the performance of diffusion
models. However, one major limitation of AR models is their sequential nature,
which processes tokens one at a time, slowing down generation compared to
models like GANs or diffusion-based methods that operate more efficiently.
While speculative decoding has proven effective for accelerating LLMs by
generating multiple tokens in a single forward, its application in visual AR
models remains largely unexplored. In this work, we identify a challenge in
this setting, which we term \textit{token selection ambiguity}, wherein visual
AR models frequently assign uniformly low probabilities to tokens, hampering
the performance of speculative decoding. To overcome this challenge, we propose
a relaxed acceptance condition referred to as LANTERN that leverages the
interchangeability of tokens in latent space. This relaxation restores the
effectiveness of speculative decoding in visual AR models by enabling more
flexible use of candidate tokens that would otherwise be prematurely rejected.
Furthermore, by incorporating a total variation distance bound, we ensure that
these speed gains are achieved without significantly compromising image quality
or semantic coherence. Experimental results demonstrate the efficacy of our
method in providing a substantial speed-up over speculative decoding. In
specific, compared to a na\"ive application of the state-of-the-art speculative
decoding, LANTERN increases speed-ups by and
, as compared to greedy decoding and random sampling,
respectively, when applied to LlamaGen, a contemporary visual AR model. The
code is publicly available at this https URL

17 Jun 2025


Large language models (LLMs) excel at capturing global token dependencies via self-attention but face prohibitive compute and memory costs on lengthy inputs. While sub-quadratic methods (e.g., linear attention) can reduce these costs, they often degrade accuracy due to overemphasizing recent tokens. In this work, we first propose dual-state linear attention (DSLA), a novel design that maintains two specialized hidden states-one for preserving historical context and one for tracking recency-thereby mitigating the short-range bias typical of linear-attention architectures. To further balance efficiency and accuracy under dynamic workload conditions, we introduce DSLA-Serve, an online adaptive distillation framework that progressively replaces Transformer layers with DSLA layers at inference time, guided by a sensitivity-based layer ordering. DSLA-Serve uses a chained fine-tuning strategy to ensure that each newly converted DSLA layer remains consistent with previously replaced layers, preserving the overall quality. Extensive evaluations on commonsense reasoning, long-context QA, and text summarization demonstrate that DSLA-Serve yields 2.3x faster inference than Llama2-7B and 3.0x faster than the hybrid Zamba-7B, while retaining comparable performance across downstream tasks. Our ablation studies show that DSLA's dual states capture both global and local dependencies, addressing the historical-token underrepresentation seen in prior linear attentions. Codes are available at this https URL.
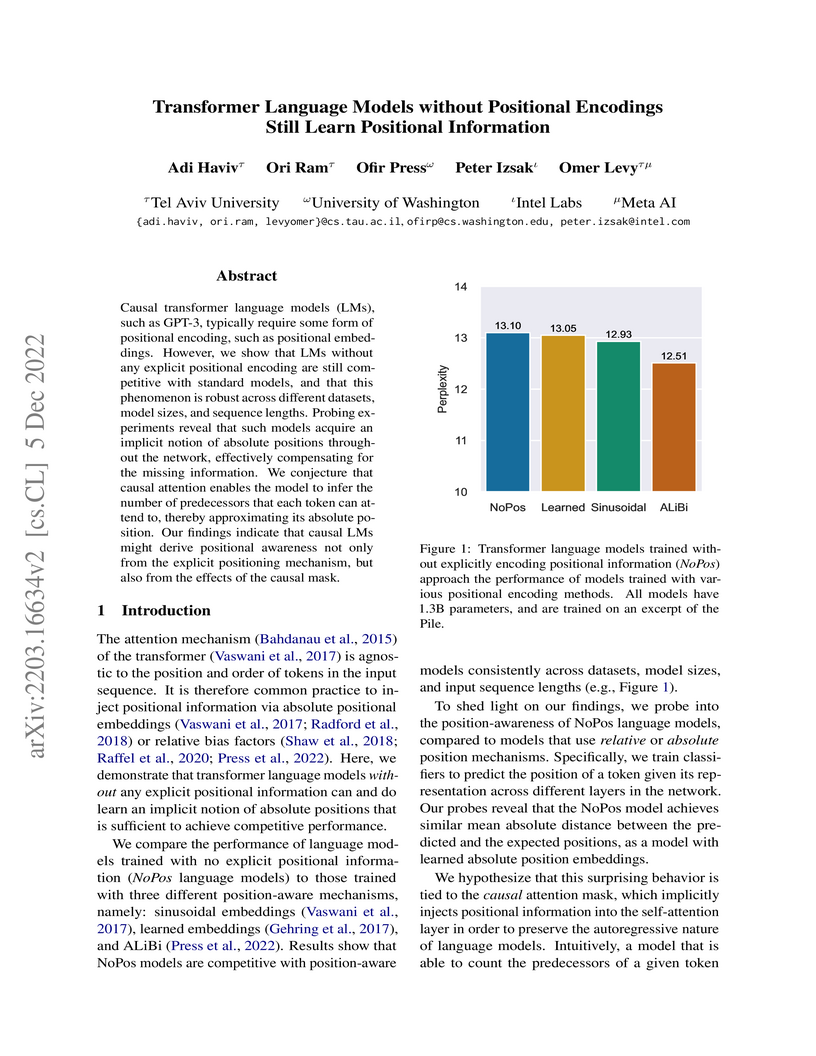
05 Dec 2022


Causal Transformer language models, including those up to 1.3 billion parameters developed by researchers at Tel Aviv University and Meta AI, achieve competitive performance without explicit positional encodings. This work demonstrates that these models implicitly learn and utilize positional information, in contrast to Masked Language Models, which fundamentally still require explicit encodings for effective convergence.

20 Jul 2023



Metric3D presents a method for zero-shot metric 3D prediction from a single image, enabling the inference of real-world scale and distances regardless of the camera model. This is achieved by explicitly accounting for camera focal length through a Canonical Camera Transformation Module and training on a massive dataset of over 8 million images, demonstrating improved performance over existing state-of-the-art affine-invariant methods and significantly reducing scale drift in monocular SLAM systems.

13 Jun 2024



In the quest for next-generation sequence modeling architectures, State Space Models (SSMs) have emerged as a potent alternative to transformers, particularly for their computational efficiency and suitability for dynamical systems. This paper investigates the effect of quantization on the S5 model to understand its impact on model performance and to facilitate its deployment to edge and resource-constrained platforms. Using quantization-aware training (QAT) and post-training quantization (PTQ), we systematically evaluate the quantization sensitivity of SSMs across different tasks like dynamical systems modeling, Sequential MNIST (sMNIST) and most of the Long Range Arena (LRA). We present fully quantized S5 models whose test accuracy drops less than 1% on sMNIST and most of the LRA. We find that performance on most tasks degrades significantly for recurrent weights below 8-bit precision, but that other components can be compressed further without significant loss of performance. Our results further show that PTQ only performs well on language-based LRA tasks whereas all others require QAT. Our investigation provides necessary insights for the continued development of efficient and hardware-optimized SSMs.

11 Jan 2019
This paper redefines multi-task learning as a multi-objective optimization problem, introducing an efficient algorithm that leverages an upper bound approximation. The method achieves improved performance and scalability across various deep learning tasks, including multi-digit classification, multi-label attribute prediction, and complex scene understanding.

13 May 2024
 California Institute of Technology
California Institute of Technology Carnegie Mellon University
Carnegie Mellon University Google
Google New York University
New York University University of Chicago
University of Chicago National University of Singapore
National University of Singapore University of Oxford
University of Oxford Stanford University
Stanford University Meta
Meta CohereIllinois Institute of TechnologyGoogle Research
CohereIllinois Institute of TechnologyGoogle Research NVIDIASony AI
NVIDIASony AI MicrosoftUCSBIntel LabsDFKIUMass Amherst
MicrosoftUCSBIntel LabsDFKIUMass Amherst Virginia Tech
Virginia Tech MIT
MIT The Ohio State UniversityIowa State UniversityUniversity of TrentoUniversity of BathTU EindhovenBocconi UniversityUniversity of YorkIntel CorporationIIT Delhi
The Ohio State UniversityIowa State UniversityUniversity of TrentoUniversity of BathTU EindhovenBocconi UniversityUniversity of YorkIntel CorporationIIT Delhi AdobePolytechnique MontrealQualcomm Technologies, Inc.Hessian.AINIKENebius AIAI Risk and Vulnerability AllianceSaferAIHaize LabsJuniper NetworksCerebras SystemsMeedanRANDFAIRNutanixEthrivaDotphotonPatronus AINational University, PhilippinesMLCommonsGraphcoreCenter for Security and Emerging TechnologyCredo AIReins AIBestech SystemsContext FundActiveFenceDigital Safety Research InstituteLF AI & DataPublic Authority for Applied Education and Training of KuwaitCoactive.AI
AdobePolytechnique MontrealQualcomm Technologies, Inc.Hessian.AINIKENebius AIAI Risk and Vulnerability AllianceSaferAIHaize LabsJuniper NetworksCerebras SystemsMeedanRANDFAIRNutanixEthrivaDotphotonPatronus AINational University, PhilippinesMLCommonsGraphcoreCenter for Security and Emerging TechnologyCredo AIReins AIBestech SystemsContext FundActiveFenceDigital Safety Research InstituteLF AI & DataPublic Authority for Applied Education and Training of KuwaitCoactive.AIThis paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.

04 May 2018

This work introduces a pioneering approach to reconstruct high-quality images from extremely noisy raw sensor data captured in very low light. The study presents the See-in-the-Dark (SID) dataset, a resource of real-world low-light raw images with ground truth, and an end-to-end deep learning pipeline that directly processes this raw data, yielding images with superior noise suppression and color accuracy compared to traditional methods.
There are no more papers matching your filters at the moment.
