
20 Jul 2018


Recent data-driven approaches to scene interpretation predominantly pose
inference as an end-to-end black-box mapping, commonly performed by a
Convolutional Neural Network (CNN). However, decades of work on perceptual
organization in both human and machine vision suggests that there are often
intermediate representations that are intrinsic to an inference task, and which
provide essential structure to improve generalization. In this work, we explore
an approach for injecting prior domain structure into neural network training
by supervising hidden layers of a CNN with intermediate concepts that normally
are not observed in practice. We formulate a probabilistic framework which
formalizes these notions and predicts improved generalization via this deep
supervision method. One advantage of this approach is that we are able to train
only from synthetic CAD renderings of cluttered scenes, where concept values
can be extracted, but apply the results to real images. Our implementation
achieves the state-of-the-art performance of 2D/3D keypoint localization and
image classification on real image benchmarks, including KITTI, PASCAL VOC,
PASCAL3D+, IKEA, and CIFAR100. We provide additional evidence that our approach
outperforms alternative forms of supervision, such as multi-task networks.

29 Mar 2025

A powerful architecture for universal segmentation relies on transformers
that encode multi-scale image features and decode object queries into mask
predictions. With efficiency being a high priority for scaling such models, we
observed that the state-of-the-art method Mask2Former uses 50% of its compute
only on the transformer encoder. This is due to the retention of a full-length
token-level representation of all backbone feature scales at each encoder
layer. With this observation, we propose a strategy termed PROgressive Token
Length SCALing for Efficient transformer encoders (PRO-SCALE) that can be
plugged-in to the Mask2Former segmentation architecture to significantly reduce
the computational cost. The underlying principle of PRO-SCALE is: progressively
scale the length of the tokens with the layers of the encoder. This allows
PRO-SCALE to reduce computations by a large margin with minimal sacrifice in
performance (~52% encoder and ~27% overall GFLOPs reduction with no drop in
performance on COCO dataset). Experiments conducted on public benchmarks
demonstrates PRO-SCALE's flexibility in architectural configurations, and
exhibits potential for extension beyond the settings of segmentation tasks to
encompass object detection. Code here:
this https URL

16 Nov 2016

Context awareness is an important enabler for next generation of Mobile Core
Networks (MCN). However there exist a number of challenges in this regard. For
example how to develop a framework which 1) is able to generate context richer
than what is available today; 2) allows reusability of context across the
network; 3) provides a mechanism for exposing context to third parties; and 4)
can bring together "big data" for mobile core network optimization. In this
work, we introduce a context awareness framework addressing the aforementioned
challenges but also taking into account the 3GPP standardization activities
related to context awareness in MCN. Within this framework we propose Context
Generation and Handling Function (CGHF) which generates rich context by
processing information from various sources and then handles its distribution
through an efficient publish subscribe mechanism. In addition we provide
examples where context can be used to optimize control plane decision making.
While the focus of this work is on the use of context for MCN, we still believe
such context can be also used by applications (at the edge as well as in data
centers) and third party services to improve their operations and providing new
unforeseen services.
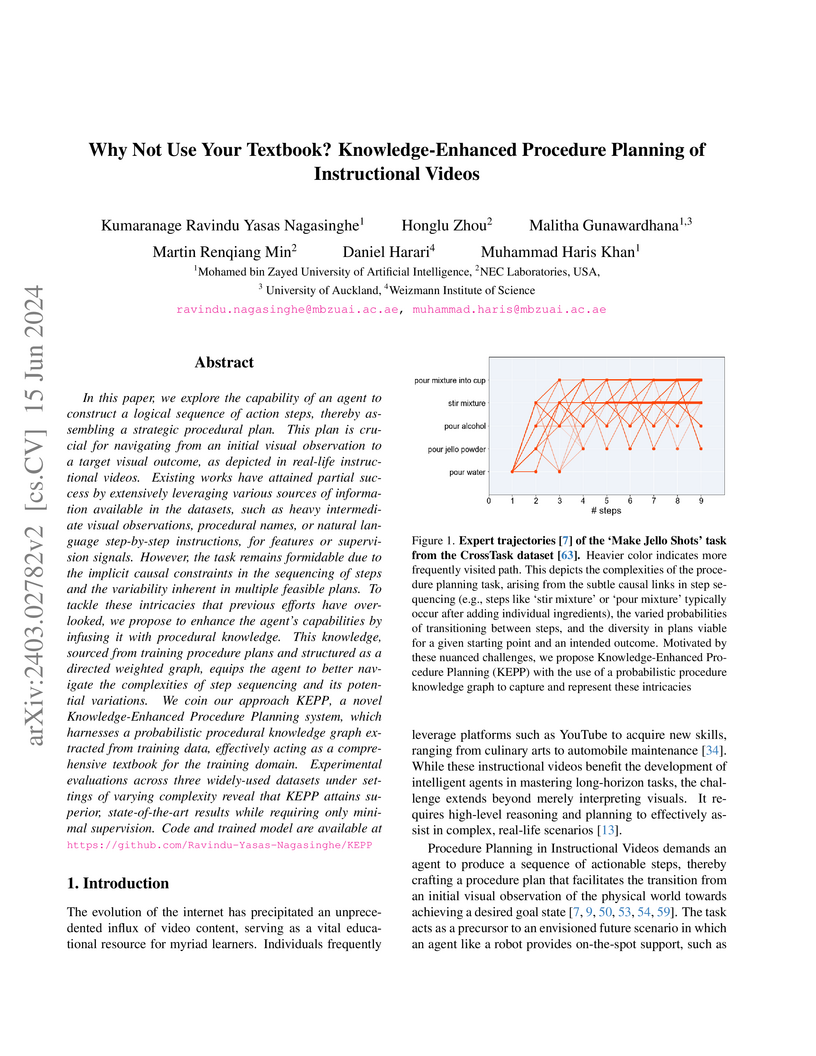
15 Jun 2024
A system named KEPP was developed to create logical procedural plans for instructional videos, leveraging a Probabilistic Procedural Knowledge Graph and problem decomposition. It achieved a 33.34% Success Rate on CrossTask (T=3) in a conventional setting, surpassing SkipPlan's 28.85%, and also outperformed state-of-the-art methods on long-horizon tasks with minimal supervision.

12 Jul 2024



Achieving carbon neutrality within industrial operations has become increasingly imperative for sustainable development. It is both a significant challenge and a key opportunity for operational optimization in industry 4.0. In recent years, Deep Reinforcement Learning (DRL) based methods offer promising enhancements for sequential optimization processes and can be used for reducing carbon emissions. However, existing DRL methods need a pre-defined reward function to assess the impact of each action on the final sustainable development goals (SDG). In many real applications, such a reward function cannot be given in advance. To address the problem, this study proposes a Performance based Adversarial Imitation Learning (PAIL) engine. It is a novel method to acquire optimal operational policies for carbon neutrality without any pre-defined action rewards. Specifically, PAIL employs a Transformer-based policy generator to encode historical information and predict following actions within a multi-dimensional space. The entire action sequence will be iteratively updated by an environmental simulator. Then PAIL uses a discriminator to minimize the discrepancy between generated sequences and real-world samples of high SDG. In parallel, a Q-learning framework based performance estimator is designed to estimate the impact of each action on SDG. Based on these estimations, PAIL refines generated policies with the rewards from both discriminator and performance estimator. PAIL is evaluated on multiple real-world application cases and datasets. The experiment results demonstrate the effectiveness of PAIL comparing to other state-of-the-art baselines. In addition, PAIL offers meaningful interpretability for the optimization in carbon neutrality.
There are no more papers matching your filters at the moment.
