
06 Mar 2025
Northwestern Polytechnical University Northeastern University
Northeastern University Sun Yat-Sen UniversityGhent UniversityKorea University
Sun Yat-Sen UniversityGhent UniversityKorea University Nanjing University
Nanjing University Zhejiang University
Zhejiang University University of MichiganXidian UniversityUniversity of Electronic Science and Technology of ChinaCentral South UniversityUniversity of Hong KongTechnology Innovation Institute
University of MichiganXidian UniversityUniversity of Electronic Science and Technology of ChinaCentral South UniversityUniversity of Hong KongTechnology Innovation Institute Yale UniversityUniversitat Pompeu Fabra
Yale UniversityUniversitat Pompeu Fabra NVIDIA
NVIDIA Huawei
Huawei Nanyang Technological UniversityUniversity of GranadaChina TelecomUlsan National Institute of Science and Technology
Nanyang Technological UniversityUniversity of GranadaChina TelecomUlsan National Institute of Science and Technology King’s College LondonSingapore University of Technology and Design
King’s College LondonSingapore University of Technology and Design Aalto University
Aalto University Virginia TechUniversity of HoustonEast China Normal University
Virginia TechUniversity of HoustonEast China Normal University KTH Royal Institute of TechnologyUniversity of OuluKhalifa UniversityLightOnCentraleSupélecUniversity of LeedsIMECNokia Bell LabsCEA-LetiUniversity of YorkOrangeEricssonBrunel University LondonQualcommChina UnicomBubbleRANITUEMIRATES INTEGRATED TELECOMMUNICATIONS COMPANYFENTECHGSMARIMEDO LABSKATIMCHINA MOBILE COMMUNICATIONS CORPORATIONBeijing Institute of TechnologyEurécom
KTH Royal Institute of TechnologyUniversity of OuluKhalifa UniversityLightOnCentraleSupélecUniversity of LeedsIMECNokia Bell LabsCEA-LetiUniversity of YorkOrangeEricssonBrunel University LondonQualcommChina UnicomBubbleRANITUEMIRATES INTEGRATED TELECOMMUNICATIONS COMPANYFENTECHGSMARIMEDO LABSKATIMCHINA MOBILE COMMUNICATIONS CORPORATIONBeijing Institute of TechnologyEurécom
Northeastern UniversitySun Yat-Sen UniversityGhent UniversityKorea UniversityNanjing UniversityZhejiang UniversityUniversity of MichiganXidian UniversityUniversity of Electronic Science and Technology of ChinaCentral South UniversityUniversity of Hong KongTechnology Innovation InstituteYale UniversityUniversitat Pompeu FabraNVIDIAHuaweiNanyang Technological UniversityUniversity of GranadaChina TelecomUlsan National Institute of Science and TechnologyKing’s College LondonSingapore University of Technology and DesignAalto UniversityVirginia TechUniversity of HoustonEast China Normal UniversityKTH Royal Institute of TechnologyUniversity of OuluKhalifa UniversityLightOnCentraleSupélecUniversity of LeedsIMECNokia Bell LabsCEA-LetiUniversity of YorkOrangeEricssonBrunel University LondonQualcommChina UnicomBubbleRANITUEMIRATES INTEGRATED TELECOMMUNICATIONS COMPANYFENTECHGSMARIMEDO LABSKATIMCHINA MOBILE COMMUNICATIONS CORPORATIONBeijing Institute of TechnologyEurécom
A comprehensive white paper from the GenAINet Initiative introduces Large Telecom Models (LTMs) as a novel framework for integrating AI into telecommunications infrastructure, providing a detailed roadmap for innovation while addressing critical challenges in scalability, hardware requirements, and regulatory compliance through insights from a diverse coalition of academic, industry and regulatory experts.

10 Mar 2025


The field of visually-rich document understanding, which involves interacting
with visually-rich documents (whether scanned or born-digital), is rapidly
evolving and still lacks consensus on several key aspects of the processing
pipeline. In this work, we provide a comprehensive overview of state-of-the-art
approaches, emphasizing their strengths and limitations, pointing out the main
challenges in the field, and proposing promising research directions.

17 Mar 2025
Large language models (LLMs) gained immense popularity due to their
impressive capabilities in unstructured conversations. Empowering LLMs with
advanced prompting strategies such as reasoning and acting (ReAct) (Yao et al.,
2022) has shown promise in solving complex tasks traditionally requiring
reinforcement learning. In this work, we apply the ReAct strategy to guide LLMs
performing task-oriented dialogue (TOD). We evaluate ReAct-based LLMs
(ReAct-LLMs) both in simulation and with real users. While ReAct-LLMs severely
underperform state-of-the-art approaches on success rate in simulation, this
difference becomes less pronounced in human evaluation. Moreover, compared to
the baseline, humans report higher subjective satisfaction with ReAct-LLM
despite its lower success rate, most likely thanks to its natural and
confidently phrased responses.

20 Oct 2025

Multimodal object detection improves robustness in chal- lenging conditions by leveraging complementary cues from multiple sensor modalities. We introduce Filtered Multi- Modal Cross Attention Fusion (FMCAF), a preprocess- ing architecture designed to enhance the fusion of RGB and infrared (IR) inputs. FMCAF combines a frequency- domain filtering block (Freq-Filter) to suppress redun- dant spectral features with a cross-attention-based fusion module (MCAF) to improve intermodal feature sharing. Unlike approaches tailored to specific datasets, FMCAF aims for generalizability, improving performance across different multimodal challenges without requiring dataset- specific tuning. On LLVIP (low-light pedestrian detec- tion) and VEDAI (aerial vehicle detection), FMCAF outper- forms traditional fusion (concatenation), achieving +13.9% mAP@50 on VEDAI and +1.1% on LLVIP. These results support the potential of FMCAF as a flexible foundation for robust multimodal fusion in future detection pipelines.

15 Oct 2020

In this paper, we analyze and extend an online learning framework known as Context-Attentive Bandit, motivated by various practical applications, from medical diagnosis to dialog systems, where due to observation costs only a small subset of a potentially large number of context variables can be observed at each iteration;however, the agent has a freedom to choose which variables to observe. We derive a novel algorithm, called Context-Attentive Thompson Sampling (CATS), which builds upon the Linear Thompson Sampling approach, adapting it to Context-Attentive Bandit setting. We provide a theoretical regret analysis and an extensive empirical evaluation demonstrating advantages of the proposed approach over several baseline methods on a variety of real-life datasets

19 Jul 2024
This survey paper systematically reviews state-of-the-art approaches for managing uncertainty throughout the Knowledge Graph (KG) construction process, identifying inherent challenges and proposing an ideal data integration pipeline. It found that while progress has been made in representing uncertainty and uncertain KG embeddings, knowledge alignment often overlooks uncertainty, and knowledge fusion struggles with granularity and extracting-originating uncertainty.

04 Apr 2022
Anomaly detection in time series is a complex task that has been widely studied. In recent years, the ability of unsupervised anomaly detection algorithms has received much attention. This trend has led researchers to compare only learning-based methods in their articles, abandoning some more conventional approaches. As a result, the community in this field has been encouraged to propose increasingly complex learning-based models mainly based on deep neural networks. To our knowledge, there are no comparative studies between conventional, machine learning-based and, deep neural network methods for the detection of anomalies in multivariate time series. In this work, we study the anomaly detection performance of sixteen conventional, machine learning-based and, deep neural network approaches on five real-world open datasets. By analyzing and comparing the performance of each of the sixteen methods, we show that no family of methods outperforms the others. Therefore, we encourage the community to reincorporate the three categories of methods in the anomaly detection in multivariate time series benchmarks.
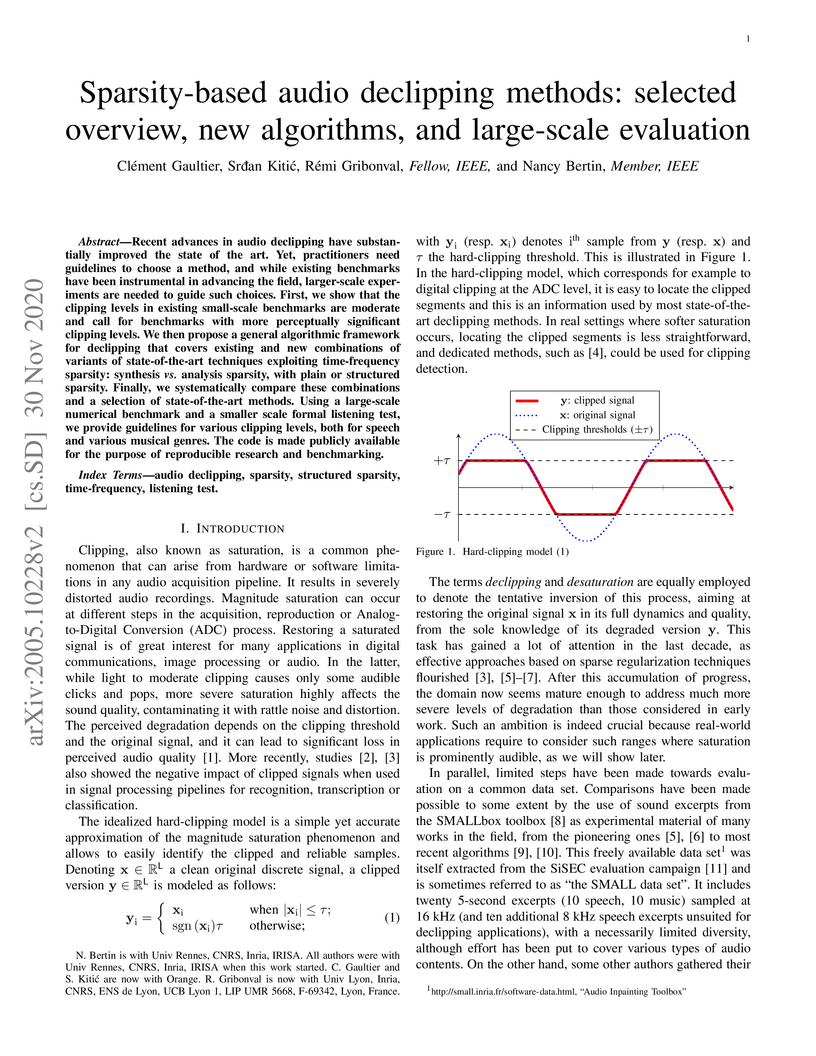
30 Nov 2020
Recent advances in audio declipping have substantially improved the state of
the art.% in certain saturation regimes. Yet, practitioners need guidelines to
choose a method, and while existing benchmarks have been instrumental in
advancing the field, larger-scale experiments are needed to guide such choices.
First, we show that the clipping levels in existing small-scale benchmarks are
moderate and call for benchmarks with more perceptually significant clipping
levels. We then propose a general algorithmic framework for declipping that
covers existing and new combinations of variants of state-of-the-art techniques
exploiting time-frequency sparsity: synthesis vs. analysis sparsity, with plain
or structured sparsity. Finally, we systematically compare these combinations
and a selection of state-of-the-art methods. Using a large-scale numerical
benchmark and a smaller scale formal listening test, we provide guidelines for
various clipping levels, both for speech and various musical genres. The code
is made publicly available for the purpose of reproducible research and
benchmarking.

28 Nov 2023

Exemplar-free class-incremental learning is very challenging due to the negative effect of catastrophic forgetting. A balance between stability and plasticity of the incremental process is needed in order to obtain good accuracy for past as well as new classes. Existing exemplar-free class-incremental methods focus either on successive fine tuning of the model, thus favoring plasticity, or on using a feature extractor fixed after the initial incremental state, thus favoring stability. We introduce a method which combines a fixed feature extractor and a pseudo-features generator to improve the stability-plasticity balance. The generator uses a simple yet effective geometric translation of new class features to create representations of past classes, made of pseudo-features. The translation of features only requires the storage of the centroid representations of past classes to produce their pseudo-features. Actual features of new classes and pseudo-features of past classes are fed into a linear classifier which is trained incrementally to discriminate between all classes. The incremental process is much faster with the proposed method compared to mainstream ones which update the entire deep model. Experiments are performed with three challenging datasets, and different incremental settings. A comparison with ten existing methods shows that our method outperforms the others in most cases.

10 Sep 2024
Linux-based cloud environments have become lucrative targets for ransomware attacks, employing various encryption schemes at unprecedented speeds. Addressing the urgency for real-time ransomware protection, we propose leveraging the extended Berkeley Packet Filter (eBPF) to collect system call information regarding active processes and infer about the data directly at the kernel level. In this study, we implement two Machine Learning (ML) models in eBPF - a decision tree and a multilayer perceptron. Benchmarking latency and accuracy against their user space counterparts, our findings underscore the efficacy of this approach.

23 Jun 2025
This paper explores the robustness of language models (LMs) to variations in the temporal context within factual knowledge. It examines whether LMs can correctly associate a temporal context with a past fact valid over a defined period, by asking them to differentiate correct from incorrect contexts. The LMs' ability to distinguish is analyzed along two dimensions: the distance of the incorrect context from the validity period and the granularity of the context. To this end, a dataset called TimeStress is introduced, enabling the evaluation of 18 diverse LMs. Results reveal that the best LM achieves a perfect distinction for only 11% of the studied facts, with errors, certainly rare, but critical that humans would not make. This work highlights the limitations of current LMs in temporal representation.

13 Mar 2025



Tasks are central in machine learning, as they are the most natural objects to assess the capabilities of current models. The trend is to build general models able to address any task. Even though transfer learning and multitask learning try to leverage the underlying task space, no well-founded tools are available to study its structure. This study proposes a theoretically grounded setup to define the notion of task and to compute the {\bf inclusion} between two tasks from a statistical deficiency point of view. We propose a tractable proxy as information sufficiency to estimate the degree of inclusion between tasks, show its soundness on synthetic data, and use it to reconstruct empirically the classic NLP pipeline.

30 Mar 2025
Multi-Agent Reinforcement Learning can lead to the development of
collaborative agent behaviors that show similarities with organizational
concepts. Pushing forward this perspective, we introduce a novel framework that
explicitly incorporates organizational roles and goals from the
model into the MARL process, guiding agents to satisfy
corresponding organizational constraints. By structuring training with roles
and goals, we aim to enhance both the explainability and control of agent
behaviors at the organizational level, whereas much of the literature primarily
focuses on individual agents. Additionally, our framework includes a
post-training analysis method to infer implicit roles and goals, offering
insights into emergent agent behaviors. This framework has been applied across
various MARL environments and algorithms, demonstrating coherence between
predefined organizational specifications and those inferred from trained
agents.

13 May 2020
We survey the literature on the privacy of trajectory micro-data, i.e., spatiotemporal information about the mobility of individuals, whose collection is becoming increasingly simple and frequent thanks to emerging information and communication technologies. The focus of our review is on privacy-preserving data publishing (PPDP), i.e., the publication of databases of trajectory micro-data that preserve the privacy of the monitored individuals. We classify and present the literature of attacks against trajectory micro-data, as well as solutions proposed to date for protecting databases from such attacks. This paper serves as an introductory reading on a critical subject in an era of growing awareness about privacy risks connected to digital services, and provides insights into open problems and future directions for research.

04 Jan 2023
Detecting Personal Protective Equipment in images and video streams is a relevant problem in ensuring the safety of construction workers. In this contribution, an architecture enabling live image recognition of such equipment is proposed. The solution is deployable in two settings -- edge-cloud and edge-only. The system was tested on an active construction site, as a part of a larger scenario, within the scope of the ASSIST-IoT H2020 project. To determine the feasibility of the edge-only variant, a model for counting people wearing safety helmets was developed using the YOLOX method. It was found that an edge-only deployment is possible for this use case, given the hardware infrastructure available on site. In the preliminary evaluation, several important observations were made, that are crucial to the further development and deployment of the system. Future work will include an in-depth investigation of performance aspects of the two architecture variants.

08 Oct 2021
This paper explores various attack scenarios on a voice anonymization system using embeddings alignment techniques. We use Wasserstein-Procrustes (an algorithm initially designed for unsupervised translation) or Procrustes analysis to match two sets of x-vectors, before and after voice anonymization, to mimic this transformation as a rotation function. We compute the optimal rotation and compare the results of this approximation to the official Voice Privacy Challenge results. We show that a complex system like the baseline of the Voice Privacy Challenge can be approximated by a rotation, estimated using a limited set of x-vectors. This paper studies the space of solutions for voice anonymization within the specific scope of rotations. Rotations being reversible, the proposed method can recover up to 62% of the speaker identities from anonymized embeddings.

21 Oct 2022
The Automated Speech Recognition (ASR) community experiences a major turning
point with the rise of the fully-neural (End-to-End, E2E) approaches. At the
same time, the conventional hybrid model remains the standard choice for the
practical usage of ASR. According to previous studies, the adoption of E2E ASR
in real-world applications was hindered by two main limitations: their ability
to generalize on unseen domains and their high operational cost. In this paper,
we investigate both above-mentioned drawbacks by performing a comprehensive
multi-domain benchmark of several contemporary E2E models and a hybrid
baseline. Our experiments demonstrate that E2E models are viable alternatives
for the hybrid approach, and even outperform the baseline both in accuracy and
in operational efficiency. As a result, our study shows that the generalization
and complexity issues are no longer the major obstacle for industrial
integration, and draws the community's attention to other potential limitations
of the E2E approaches in some specific use-cases.

23 Aug 2024
\texttt{ml\_edm} is a Python 3 library, designed for early decision making of
any learning tasks involving temporal/sequential data. The package is also
modular, providing researchers an easy way to implement their own triggering
strategy for classification, regression or any machine learning task. As of
now, many Early Classification of Time Series (ECTS) state-of-the-art
algorithms, are efficiently implemented in the library leveraging parallel
computation. The syntax follows the one introduce in \texttt{scikit-learn},
making estimators and pipelines compatible with \texttt{ml\_edm}. This software
is distributed over the BSD-3-Clause license, source code can be found at
\url{this https URL}.

26 Aug 2024
Knowledge graphs (KGs) have become ubiquitous publicly available knowledge sources, and are nowadays covering an ever increasing array of domains. However, not all knowledge represented is useful or pertaining when considering a new application or specific task. Also, due to their increasing size, handling large KGs in their entirety entails scalability issues. These two aspects asks for efficient methods to extract subgraphs of interest from existing KGs. To this aim, we introduce KGPrune, a Web Application that, given seed entities of interest and properties to traverse, extracts their neighboring subgraphs from Wikidata. To avoid topical drift, KGPrune relies on a frugal pruning algorithm based on analogical reasoning to only keep relevant neighbors while pruning irrelevant ones. The interest of KGPrune is illustrated by two concrete applications, namely, bootstrapping an enterprise KG and extracting knowledge related to looted artworks.

01 Oct 2024
This paper proposes an approach of Ladder Bottom-up Convolutional Bidirectional Variational Autoencoder (LCBVAE) architecture for the encoder and decoder, which is trained on the image translation of the dotted Arabic expiration dates by reconstructing the Arabic dotted expiration dates into filled-in expiration dates. We employed a customized and adapted version of Convolutional Recurrent Neural Network CRNN model to meet our specific requirements and enhance its performance in our context, and then trained the custom CRNN model with the filled-in images from the year of 2019 to 2027 to extract the expiration dates and assess the model performance of LCBVAE on the expiration date recognition. The pipeline of (LCBVAE+CRNN) can be then integrated into an automated sorting systems for extracting the expiry dates and sorting the products accordingly during the manufacture stage. Additionally, it can overcome the manual entry of expiration dates that can be time-consuming and inefficient at the merchants. Due to the lack of the availability of the dotted Arabic expiration date images, we created an Arabic dot-matrix True Type Font (TTF) for the generation of the synthetic images. We trained the model with unrealistic synthetic dates of 60,000 images and performed the testing on a realistic synthetic date of 3000 images from the year of 2019 to 2027, represented as yyyy/mm/dd. In our study, we demonstrated the significance of latent bottleneck layer with improving the generalization when the size is increased up to 1024 in downstream transfer learning tasks as for image translation. The proposed approach achieved an accuracy of 97% on the image translation with using the LCBVAE architecture that can be generalized for any downstream learning tasks as for image translation and reconstruction.
There are no more papers matching your filters at the moment.
