
13 Feb 2025


ImageRAG introduces a training-free Retrieval-Augmented Generation (RAG) method that dynamically retrieves relevant visual references to guide pre-trained Text-to-Image (T2I) models. The system enhances the generation of rare, fine-grained, or user-specific concepts, consistently improving image similarity metrics and user preferences over baseline models like OmniGen and SDXL.

15 Mar 2025
Stable Flow introduces a training-free image editing method for Diffusion Transformer (DiT) models like FLUX and SD3, achieving consistent and diverse edits. It leverages an automated vital layer detection and selective attention injection mechanism, combined with a latent nudging technique for robust real-image inversion, outperforming existing baselines in user studies and quantitative metrics.

14 May 2025

LightLab introduces a method for fine-grained, parametric control over visible light sources in single indoor images using a conditional diffusion model. The Google-led team achieved this by combining a small dataset of real-world light changes with a large volume of synthetically rendered images, demonstrating photorealistic and physically plausible relighting.

30 Apr 2023
Blended Latent Diffusion adapts an existing blending technique to latent diffusion models, enabling local text-driven image editing that is 10-20 times faster and more precise than prior pixel-based approaches. This method produces seamless, high-fidelity edits by addressing challenges like imperfect VAE reconstruction and thin masks in latent space.

22 Sep 2024
Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.

28 Mar 2022
This work introduces "Blended Diffusion," a method for performing region-based, text-driven editing of generic natural images, achieving perfect background preservation and seamless integration. It demonstrates superior realism and coherence in edited images compared to prior methods, as confirmed by user studies.

08 Feb 2025
SaSPA is a generative data augmentation method designed for fine-grained visual classification, which generates diverse yet class-fidelity-preserving synthetic images by combining Canny edge maps, BLIP-diffusion subject representations, and LLM-generated prompts. This approach consistently outperforms existing methods across various FGVC benchmarks and few-shot learning scenarios, while also effectively mitigating contextual bias.

25 Mar 2025
In recent years, notable advancements have been made in the domain of visual
document understanding, with the prevailing architecture comprising a cascade
of vision and language models. The text component can either be extracted
explicitly with the use of external OCR models in OCR-based approaches, or
alternatively, the vision model can be endowed with reading capabilities in
OCR-free approaches. Typically, the queries to the model are input exclusively
to the language component, necessitating the visual features to encompass the
entire document. In this paper, we present VisFocus, an OCR-free method
designed to better exploit the vision encoder's capacity by coupling it
directly with the language prompt. To do so, we replace the down-sampling
layers with layers that receive the input prompt and allow highlighting
relevant parts of the document, while disregarding others. We pair the
architecture enhancements with a novel pre-training task, using language
masking on a snippet of the document text fed to the visual encoder in place of
the prompt, to empower the model with focusing capabilities. Consequently,
VisFocus learns to allocate its attention to text patches pertinent to the
provided prompt. Our experiments demonstrate that this prompt-guided visual
encoding approach significantly improves performance, achieving
state-of-the-art results on various benchmarks.

16 Mar 2025
Researchers at Reichman University developed 'Tiled Diffusion,' a novel method that integrates tiling constraints directly into the latent space of diffusion models. The approach generates high-quality, seamlessly tileable images across diverse scenarios, including complex 'many-to-many' connections, achieving a Tiling Score of 0.03-0.04 and outperforming existing methods in flexibility and coherence.

10 Oct 2025

Editing 4D scenes reconstructed from monocular videos based on text prompts is a valuable yet challenging task with broad applications in content creation and virtual environments. The key difficulty lies in achieving semantically precise edits in localized regions of complex, dynamic scenes, while preserving the integrity of unedited content. To address this, we introduce Mono4DEditor, a novel framework for flexible and accurate text-driven 4D scene editing. Our method augments 3D Gaussians with quantized CLIP features to form a language-embedded dynamic representation, enabling efficient semantic querying of arbitrary spatial regions. We further propose a two-stage point-level localization strategy that first selects candidate Gaussians via CLIP similarity and then refines their spatial extent to improve accuracy. Finally, targeted edits are performed on localized regions using a diffusion-based video editing model, with flow and scribble guidance ensuring spatial fidelity and temporal coherence. Extensive experiments demonstrate that Mono4DEditor enables high-quality, text-driven edits across diverse scenes and object types, while preserving the appearance and geometry of unedited areas and surpassing prior approaches in both flexibility and visual fidelity.

16 May 2022


Abstraction is at the heart of sketching due to the simple and minimal nature
of line drawings. Abstraction entails identifying the essential visual
properties of an object or scene, which requires semantic understanding and
prior knowledge of high-level concepts. Abstract depictions are therefore
challenging for artists, and even more so for machines. We present CLIPasso, an
object sketching method that can achieve different levels of abstraction,
guided by geometric and semantic simplifications. While sketch generation
methods often rely on explicit sketch datasets for training, we utilize the
remarkable ability of CLIP (Contrastive-Language-Image-Pretraining) to distill
semantic concepts from sketches and images alike. We define a sketch as a set
of B\'ezier curves and use a differentiable rasterizer to optimize the
parameters of the curves directly with respect to a CLIP-based perceptual loss.
The abstraction degree is controlled by varying the number of strokes. The
generated sketches demonstrate multiple levels of abstraction while maintaining
recognizability, underlying structure, and essential visual components of the
subject drawn.

01 Dec 2024
Research from Tel Aviv University and Reichman University reveals that concept ablation in text-to-image diffusion models does not fully erase information; supposedly forgotten concepts remain reconstructible with high quality from the latent space. Their analysis demonstrates that a single erased image can be generated from multiple distinct latent seeds, indicating persistent and distributed memory within the model.

02 May 2025

We introduce Masked Anchored SpHerical Distances (MASH), a novel multi-view
and parametrized representation of 3D shapes. Inspired by multi-view geometry
and motivated by the importance of perceptual shape understanding for learning
3D shapes, MASH represents a 3D shape as a collection of observable local
surface patches, each defined by a spherical distance function emanating from
an anchor point. We further leverage the compactness of spherical harmonics to
encode the MASH functions, combined with a generalized view cone with a
parameterized base that masks the spatial extent of the spherical function to
attain locality. We develop a differentiable optimization algorithm capable of
converting any point cloud into a MASH representation accurately approximating
ground-truth surfaces with arbitrary geometry and topology. Extensive
experiments demonstrate that MASH is versatile for multiple applications
including surface reconstruction, shape generation, completion, and blending,
achieving superior performance thanks to its unique representation encompassing
both implicit and explicit features.

04 Oct 2023
Break-A-Scene introduces a method for textual scene decomposition, extracting disentangled text tokens for multiple visual concepts from a single input image. It achieves a superior balance between faithful concept reconstruction and prompt-driven editability, outperforming existing personalization techniques in both quantitative and qualitative evaluations.

21 Aug 2024

Perpetual futures are the most popular cryptocurrency derivatives. Perpetuals offer leveraged exposure to their underlying without rollover or direct ownership. Unlike fixed-maturity futures, perpetuals are not guaranteed to converge to the spot price. To minimize the gap between perpetual and spot prices, long investors periodically pay shorts a funding rate proportional to this difference. We derive no-arbitrage prices for perpetual futures in frictionless markets and bounds in markets with trading costs. Empirically, deviations from these prices in crypto are larger than in traditional currency markets, comove across currencies, and diminish over time. An implied arbitrage strategy yields high Sharpe ratios.

05 Jun 2024
A method called "The Chosen One" introduces an automated, text-only approach to generate visually consistent characters across different contexts using text-to-image diffusion models. It enables the creation of novel characters that maintain a stable identity through an iterative self-refinement process, demonstrating superior consistency and prompt adherence compared to previous methods.

12 Feb 2025

Recent advancements in large vision-language models have enabled highly
expressive and diverse vector sketch generation. However, state-of-the-art
methods rely on a time-consuming optimization process involving repeated
feedback from a pretrained model to determine stroke placement. Consequently,
despite producing impressive sketches, these methods are limited in practical
applications. In this work, we introduce SwiftSketch, a diffusion model for
image-conditioned vector sketch generation that can produce high-quality
sketches in less than a second. SwiftSketch operates by progressively denoising
stroke control points sampled from a Gaussian distribution. Its
transformer-decoder architecture is designed to effectively handle the discrete
nature of vector representation and capture the inherent global dependencies
between strokes. To train SwiftSketch, we construct a synthetic dataset of
image-sketch pairs, addressing the limitations of existing sketch datasets,
which are often created by non-artists and lack professional quality. For
generating these synthetic sketches, we introduce ControlSketch, a method that
enhances SDS-based techniques by incorporating precise spatial control through
a depth-aware ControlNet. We demonstrate that SwiftSketch generalizes across
diverse concepts, efficiently producing sketches that combine high fidelity
with a natural and visually appealing style.

09 Jun 2025

Text-to-image models are powerful tools for image creation. However, the
generation process is akin to a dice roll and makes it difficult to achieve a
single image that captures everything a user wants. In this paper, we propose a
framework for creating the desired image by compositing it from various parts
of generated images, in essence forming a Generative Photomontage. Given a
stack of images generated by ControlNet using the same input condition and
different seeds, we let users select desired parts from the generated results
using a brush stroke interface. We introduce a novel technique that takes in
the user's brush strokes, segments the generated images using a graph-based
optimization in diffusion feature space, and then composites the segmented
regions via a new feature-space blending method. Our method faithfully
preserves the user-selected regions while compositing them harmoniously. We
demonstrate that our flexible framework can be used for many applications,
including generating new appearance combinations, fixing incorrect shapes and
artifacts, and improving prompt alignment. We show compelling results for each
application and demonstrate that our method outperforms existing image blending
methods and various baselines.
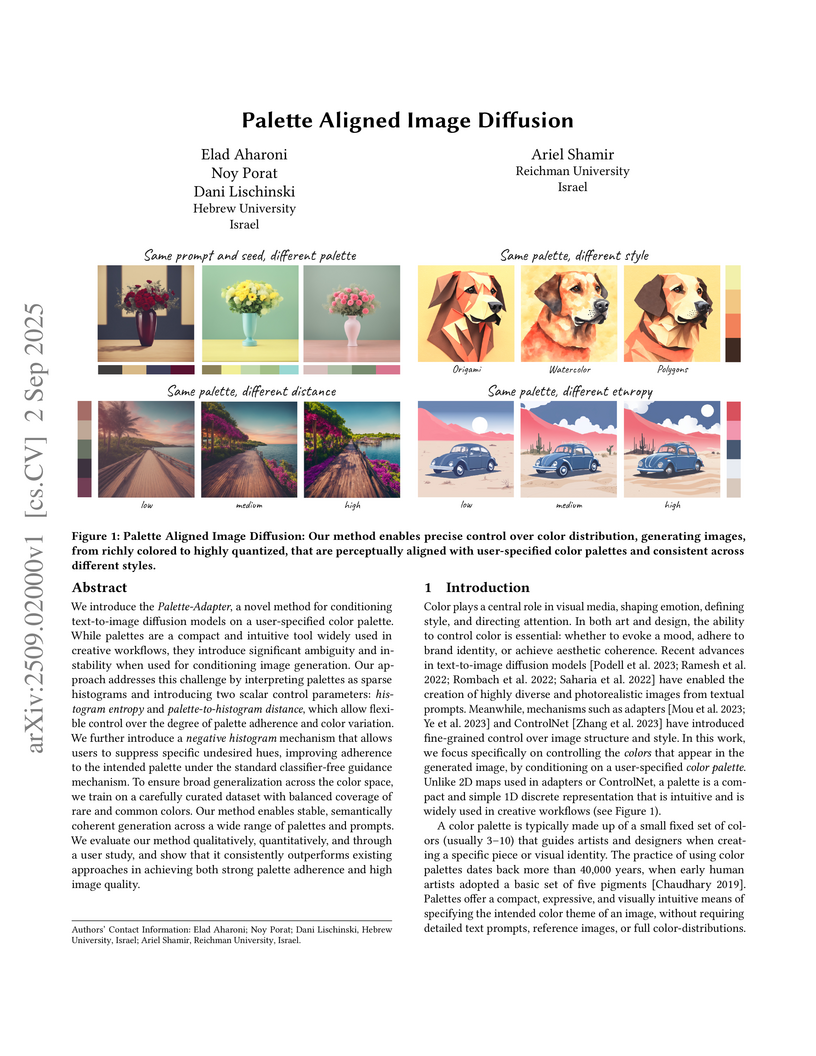
02 Sep 2025
We introduce the Palette-Adapter, a novel method for conditioning text-to-image diffusion models on a user-specified color palette. While palettes are a compact and intuitive tool widely used in creative workflows, they introduce significant ambiguity and instability when used for conditioning image generation. Our approach addresses this challenge by interpreting palettes as sparse histograms and introducing two scalar control parameters: histogram entropy and palette-to-histogram distance, which allow flexible control over the degree of palette adherence and color variation. We further introduce a negative histogram mechanism that allows users to suppress specific undesired hues, improving adherence to the intended palette under the standard classifier-free guidance mechanism. To ensure broad generalization across the color space, we train on a carefully curated dataset with balanced coverage of rare and common colors. Our method enables stable, semantically coherent generation across a wide range of palettes and prompts. We evaluate our method qualitatively, quantitatively, and through a user study, and show that it consistently outperforms existing approaches in achieving both strong palette adherence and high image quality.

02 Dec 2024
Sign Language Processing (SLP) is an interdisciplinary field comprised of Natural Language Processing (NLP) and Computer Vision. It is focused on the computational understanding, translation, and production of signed languages. Traditional approaches have often been constrained by the use of gloss-based systems that are both language-specific and inadequate for capturing the multidimensional nature of sign language. These limitations have hindered the development of technology capable of processing signed languages effectively.
This thesis aims to revolutionize the field of SLP by proposing a simple paradigm that can bridge this existing technological gap. We propose the use of SignWiring, a universal sign language transcription notation system, to serve as an intermediary link between the visual-gestural modality of signed languages and text-based linguistic representations.
We contribute foundational libraries and resources to the SLP community, thereby setting the stage for a more in-depth exploration of the tasks of sign language translation and production. These tasks encompass the translation of sign language from video to spoken language text and vice versa. Through empirical evaluations, we establish the efficacy of our transcription method as a pivot for enabling faster, more targeted research, that can lead to more natural and accurate translations across a range of languages.
The universal nature of our transcription-based paradigm also paves the way for real-time, multilingual applications in SLP, thereby offering a more inclusive and accessible approach to language technology. This is a significant step toward universal accessibility, enabling a wider reach of AI-driven language technologies to include the deaf and hard-of-hearing community.
There are no more papers matching your filters at the moment.
