
24 Jul 2025
Researchers at the University of Toronto present OpenNav, a framework that enables robots to perform open-world navigation by interpreting complex, free-form language instructions and synthesizing dense trajectory points. It achieves zero-shot open-world navigation with improved success rates and lower navigation errors compared to text-only approaches, while maintaining geometry-compliant and collision-free trajectories.

23 Sep 2025
Scaling Reinforcement Learning to in-the-wild social robot navigation is both data-intensive and unsafe, since policies must learn through direct interaction and inevitably encounter collisions. Offline Imitation learning (IL) avoids these risks by collecting expert demonstrations safely, training entirely offline, and deploying policies zero-shot. However, we find that naively applying Behaviour Cloning (BC) to social navigation is insufficient; achieving strong performance requires careful architectural and training choices. We present Ratatouille, a pipeline and model architecture that, without changing the data, reduces collisions per meter by 6 times and improves success rate by 3 times compared to naive BC. We validate our approach in both simulation and the real world, where we collected over 11 hours of data on a dense university campus. We further demonstrate qualitative results in a public food court. Our findings highlight that thoughtful IL design, rather than additional data, can substantially improve safety and reliability in real-world social navigation. Video: this https URL. Code will be released after acceptance.
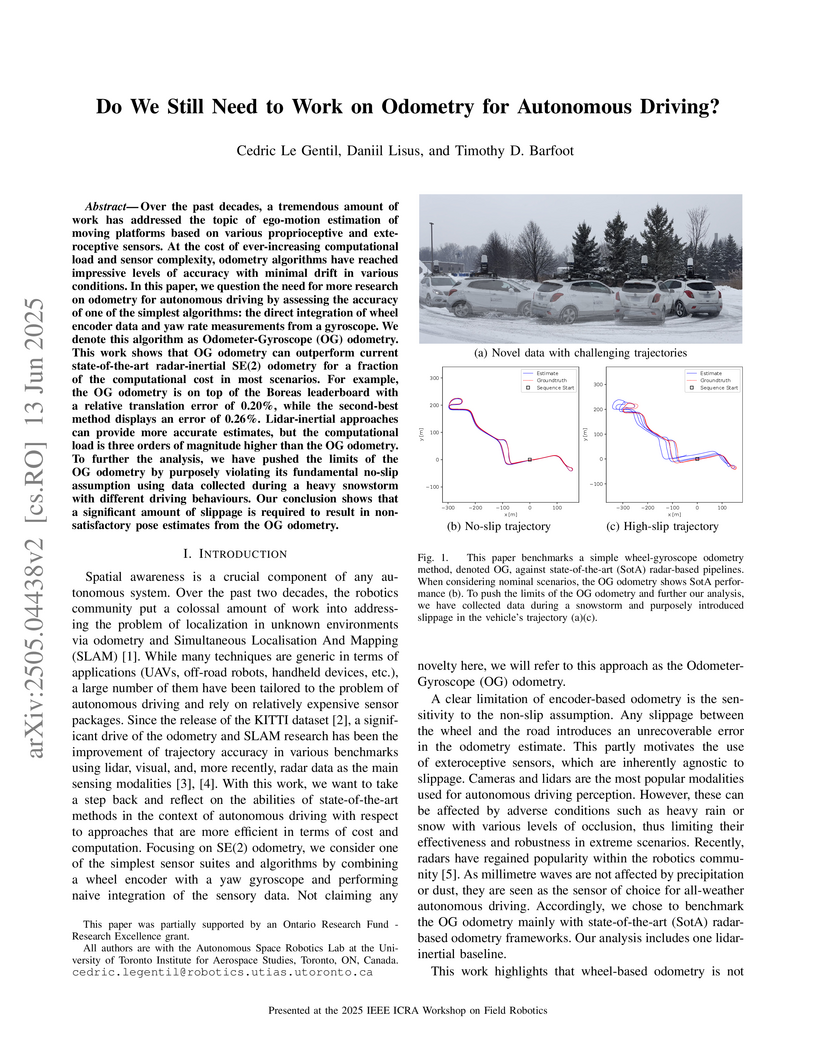
13 Jun 2025
Researchers from the Autonomous Space Robotics Lab at the University of Toronto evaluate a simple Odometer-Gyroscope (OG) odometry, demonstrating its state-of-the-art accuracy and superior computational efficiency in nominal autonomous driving conditions. While it performs comparably to or better than complex lidar and radar methods, its accuracy degrades under extreme wheel slippage, suggesting a redirection of research focus towards slip compensation and global localization rather than continued general odometry improvements.

11 Jul 2022


Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.

14 Feb 2025

How can a robot safely navigate around people with complex motion patterns?
Deep Reinforcement Learning (DRL) in simulation holds some promise, but much
prior work relies on simulators that fail to capture the nuances of real human
motion. Thus, we propose Deep Residual Model Predictive Control (DR-MPC) to
enable robots to quickly and safely perform DRL from real-world crowd
navigation data. By blending MPC with model-free DRL, DR-MPC overcomes the DRL
challenges of large data requirements and unsafe initial behavior. DR-MPC is
initialized with MPC-based path tracking, and gradually learns to interact more
effectively with humans. To further accelerate learning, a safety component
estimates out-of-distribution states to guide the robot away from likely
collisions. In simulation, we show that DR-MPC substantially outperforms prior
work, including traditional DRL and residual DRL models. Hardware experiments
show our approach successfully enables a robot to navigate a variety of crowded
situations with few errors using less than 4 hours of training data.

27 May 2025
This paper presents a novel deep-learning-based approach to improve localizing radar measurements against lidar maps. This radar-lidar localization leverages the benefits of both sensors; radar is resilient against adverse weather, while lidar produces high-quality maps in clear conditions. However, owing in part to the unique artefacts present in radar measurements, radar-lidar localization has struggled to achieve comparable performance to lidar-lidar systems, preventing it from being viable for autonomous driving. This work builds on ICP-based radar-lidar localization by including a learned preprocessing step that weights radar points based on high-level scan information. To train the weight-generating network, we present a novel, stand-alone, open-source differentiable ICP library. The learned weights facilitate ICP by filtering out harmful radar points related to artefacts, noise, and even vehicles on the road. Combining an analytical approach with a learned weight reduces overall localization errors and improves convergence in radar-lidar ICP results run on real-world autonomous driving data. Our code base is publicly available to facilitate reproducibility and extensions.

25 Sep 2025
Stably placing an object in a multi-object scene is a fundamental challenge in robotic manipulation, as placements must be penetration-free, establish precise surface contact, and result in a force equilibrium. To assess stability, existing methods rely on running a simulation engine or resort to heuristic, appearance-based assessments. In contrast, our approach integrates stability directly into the sampling process of a diffusion model. To this end, we query an offline sampling-based planner to gather multi-modal placement labels and train a diffusion model to generate stable placements. The diffusion model is conditioned on scene and object point clouds, and serves as a geometry-aware prior. We leverage the compositional nature of score-based generative models to combine this learned prior with a stability-aware loss, thereby increasing the likelihood of sampling from regions of high stability. Importantly, this strategy requires no additional re-training or fine-tuning, and can be directly applied to off-the-shelf models. We evaluate our method on four benchmark scenes where stability can be accurately computed. Our physics-guided models achieve placements that are 56% more robust to forceful perturbations while reducing runtime by 47% compared to a state-of-the-art geometric method.

05 Jul 2022
We present a novel method to fuse the power of deep networks with the
computational efficiency of geometric and probabilistic localization
algorithms. In contrast to other methods that completely replace a classical
visual estimator with a deep network, we propose an approach that uses a
convolutional neural network to learn difficult-to-model corrections to the
estimator from ground-truth training data. To this end, we derive a novel loss
function for learning SE(3) corrections based on a matrix Lie groups approach,
with a natural formulation for balancing translation and rotation errors. We
use this loss to train a Deep Pose Correction network (DPC-Net) that predicts
corrections for a particular estimator, sensor and environment. Using the KITTI
odometry dataset, we demonstrate significant improvements to the accuracy of a
computationally-efficient sparse stereo visual odometry pipeline, that render
it as accurate as a modern computationally-intensive dense estimator. Further,
we show how DPC-Net can be used to mitigate the effect of poorly calibrated
lens distortion parameters.

30 Jul 2025

Automatic extrinsic sensor calibration is a fundamental problem for multi-sensor platforms. Reliable and general-purpose solutions should be computationally efficient, require few assumptions about the structure of the sensing environment, and demand little effort from human operators. Since the engineering effort required to obtain accurate calibration parameters increases with the number of sensors deployed, robotics researchers have pursued methods requiring few assumptions about the sensing environment and minimal effort from human operators. In this work, we introduce a fast and certifiably globally optimal algorithm for solving a generalized formulation of the (RWHEC) problem. The formulation of RWHEC presented is "generalized" in that it supports the simultaneous estimation of multiple sensor and target poses, and permits the use of monocular cameras that, alone, are unable to measure the scale of their environments. In addition to demonstrating our method's superior performance over existing solutions, we derive novel identifiability criteria and establish guarantees of global optimality for problem instances with bounded measurement errors. We also introduce a complementary Lie-algebraic local solver for RWHEC and compare its performance with our global method and prior art. Finally, we provide a free and open-source implementation of our algorithms and experiments.

01 Dec 2020
Most mobile robots follow a modular sense-planact system architecture that
can lead to poor performance or even catastrophic failure for visual inertial
navigation systems due to trajectories devoid of feature matches. Planning in
belief space provides a unified approach to tightly couple the perception,
planning and control modules, leading to trajectories that are robust to noisy
measurements and disturbances. However, existing methods handle uncertainties
as costs that require manual tuning for varying environments and hardware. We
therefore propose a novel trajectory optimization formulation that incorporates
inequality constraints on uncertainty and a novel Augmented Lagrangian based
stochastic differential dynamic programming method in belief space.
Furthermore, we develop a probabilistic visibility model that accounts for
discontinuities due to feature visibility limits. Our simulation tests
demonstrate that our method can handle inequality constraints in different
environments, for holonomic and nonholonomic motion models with no manual
tuning of uncertainty costs involved. We also show the improved optimization
performance in belief space due to our visibility model.

06 Jul 2023
To operate safely and efficiently alongside human workers, collaborative robots (cobots) require the ability to quickly understand the dynamics of manipulated objects. However, traditional methods for estimating the full set of inertial parameters rely on motions that are necessarily fast and unsafe (to achieve a sufficient signal-to-noise ratio). In this work, we take an alternative approach: by combining visual and force-torque measurements, we develop an inertial parameter identification algorithm that requires slow or 'stop-and-go' motions only, and hence is ideally tailored for use around humans. Our technique, called Homogeneous Part Segmentation (HPS), leverages the observation that man-made objects are often composed of distinct, homogeneous parts. We combine a surface-based point clustering method with a volumetric shape segmentation algorithm to quickly produce a part-level segmentation of a manipulated object; the segmented representation is then used by HPS to accurately estimate the object's inertial parameters. To benchmark our algorithm, we create and utilize a novel dataset consisting of realistic meshes, segmented point clouds, and inertial parameters for 20 common workshop tools. Finally, we demonstrate the real-world performance and accuracy of HPS by performing an intricate 'hammer balancing act' autonomously and online with a low-cost collaborative robotic arm. Our code and dataset are open source and freely available.

20 Jan 2023
Sequential modelling of high-dimensional data is an important problem that
appears in many domains including model-based reinforcement learning and
dynamics identification for control. Latent variable models applied to
sequential data (i.e., latent dynamics models) have been shown to be a
particularly effective probabilistic approach to solve this problem, especially
when dealing with images. However, in many application areas (e.g., robotics),
information from multiple sensing modalities is available -- existing latent
dynamics methods have not yet been extended to effectively make use of such
multimodal sequential data. Multimodal sensor streams can be correlated in a
useful manner and often contain complementary information across modalities. In
this work, we present a self-supervised generative modelling framework to
jointly learn a probabilistic latent state representation of multimodal data
and the respective dynamics. Using synthetic and real-world datasets from a
multimodal robotic planar pushing task, we demonstrate that our approach leads
to significant improvements in prediction and representation quality.
Furthermore, we compare to the common learning baseline of concatenating each
modality in the latent space and show that our principled probabilistic
formulation performs better. Finally, despite being fully self-supervised, we
demonstrate that our method is nearly as effective as an existing supervised
approach that relies on ground truth labels.

08 Mar 2023

This paper presents a scalable online algorithm to generate safe and
kinematically feasible trajectories for quadrotor swarms. Existing approaches
rely on linearizing Euclidean distance-based collision constraints and on
axis-wise decoupling of kinematic constraints to reduce the trajectory
optimization problem for each quadrotor to a quadratic program (QP). This
conservative approximation often fails to find a solution in cluttered
environments. We present a novel alternative that handles collision constraints
without linearization and kinematic constraints in their quadratic form while
still retaining the QP form. We achieve this by reformulating the constraints
in a polar form and applying an Alternating Minimization algorithm to the
resulting problem. Through extensive simulation results, we demonstrate that,
as compared to Sequential Convex Programming (SCP) baselines, our approach
achieves on average a 72% improvement in success rate, a 36% reduction in
mission time, and a 42 times faster per-agent computation time. We also show
that collision constraints derived from discrete-time barrier functions (BF)
can be incorporated, leading to different safety behaviours without significant
computational overhead. Moreover, our optimizer outperforms the
state-of-the-art optimal control solver ACADO in handling BF constraints with a
31 times faster per-agent computation time and a 44% reduction in mission time
on average. We experimentally validated our approach on a Crazyflie quadrotor
swarm of up to 12 quadrotors. The code with supplementary material and video
are released for reference.

17 Feb 2022
In this paper, we learn visual features that we use to first build a map and then localize a robot driving autonomously across a full day of lighting change, including in the dark. We train a neural network to predict sparse keypoints with associated descriptors and scores that can be used together with a classical pose estimator for localization. Our training pipeline includes a differentiable pose estimator such that training can be supervised with ground truth poses from data collected earlier, in our case from 2016 and 2017 gathered with multi-experience Visual Teach and Repeat (VT&R). We insert the learned features into the existing VT&R pipeline to perform closed-loop path following in unstructured outdoor environments. We show successful path following across all lighting conditions despite the robot's map being constructed using daylight conditions. Moreover, we explore generalizability of the features by driving the robot across all lighting conditions in new areas not present in the feature training dataset. In all, we validated our approach with 35.5 km of autonomous path following experiments in challenging conditions.

13 Aug 2019
We present a method to improve the accuracy of a zero-velocity-aided inertial
navigation system (INS) by replacing the standard zero-velocity detector with a
long short-term memory (LSTM) neural network. While existing threshold-based
zero-velocity detectors are not robust to varying motion types, our learned
model accurately detects stationary periods of the inertial measurement unit
(IMU) despite changes in the motion of the user. Upon detection, zero-velocity
pseudo-measurements are fused with a dead reckoning motion model in an extended
Kalman filter (EKF). We demonstrate that our LSTM-based zero-velocity detector,
used within a zero-velocity-aided INS, improves zero-velocity detection during
human localization tasks. Consequently, localization accuracy is also improved.
Our system is evaluated on more than 7.5 km of indoor pedestrian locomotion
data, acquired from five different subjects. We show that 3D positioning error
is reduced by over 34% compared to existing fixed-threshold zero-velocity
detectors for walking, running, and stair climbing motions. Additionally, we
demonstrate how our learned zero-velocity detector operates effectively during
crawling and ladder climbing. Our system is calibration-free (no careful
threshold-tuning is required) and operates consistently with differing users,
IMU placements, and shoe types, while being compatible with any generic
zero-velocity-aided INS.

03 Mar 2025
Researchers at the University of Toronto Institute for Aerospace Studies and Trimble developed a framework to optimize lidar-based localization efficiency for autonomous vehicles by varying map-matching frequency and integrating a correspondence-free Doppler odometry. Their method quantifies the trade-offs, demonstrating that localizing once per second (`n=10`) significantly reduces computational load while maintaining accuracy, with the Doppler pipeline achieving faster real-time performance.

20 Nov 2024
Treating IMU measurements as inputs to a motion model and then preintegrating these measurements has almost become a de-facto standard in many robotics applications. However, this approach has a few shortcomings. First, it conflates the IMU measurement noise with the underlying process noise. Second, it is unclear how the state will be propagated in the case of IMU measurement dropout. Third, it does not lend itself well to dealing with multiple high-rate sensors such as a lidar and an IMU or multiple asynchronous IMUs. In this paper, we compare treating an IMU as an input to a motion model against treating it as a measurement of the state in a continuous-time state estimation framework. We methodically compare the performance of these two approaches on a 1D simulation and show that they perform identically, assuming that each method's hyperparameters have been tuned on a training set. We also provide results for our continuous-time lidar-inertial odometry in simulation and on the Newer College Dataset. In simulation, our approach exceeds the performance of an imu-as-input baseline during highly aggressive motion. On the Newer College Dataset, we demonstrate state of the art results. These results show that continuous-time techniques and the treatment of the IMU as a measurement of the state are promising areas of further research. Code for our lidar-inertial odometry can be found at: this https URL

13 Jan 2021
In order to tackle the challenge of unfavorable weather conditions such as rain and snow, radar is being revisited as a parallel sensing modality to vision and lidar. Recent works have made tremendous progress in applying spinning radar to odometry and place recognition. However, these works have so far ignored the impact of motion distortion and Doppler effects on spinning-radar-based navigation, which may be significant in the self-driving car domain where speeds can be high. In this work, we demonstrate the effect of these distortions on radar odometry using the Oxford Radar RobotCar Dataset and metric localization using our own data-taking platform. We revisit a lightweight estimator that can recover the motion between a pair of radar scans while accounting for both effects. Our conclusion is that both motion distortion and the Doppler effect are significant in different aspects of spinning radar navigation, with the former more prominent than the latter. Code for this project can be found at: this https URL

17 Jun 2024
We present a controller for quasistatic robotic planar pushing with single-point contact using only force feedback to sense the pushed object. We consider an omnidirectional mobile robot pushing an object (the "slider") along a given path, where the robot is equipped with a force-torque sensor to measure the force at the contact point with the slider. The geometric, inertial, and frictional parameters of the slider are not known to the controller, nor are measurements of the slider's pose. We assume that the robot can be localized so that the global position of the contact point is always known and that the approximate initial position of the slider is provided. Simulations and real-world experiments show that our controller yields pushes that are robust to a wide range of slider parameters and state perturbations along both straight and curved paths. Furthermore, we use an admittance controller to adjust the pushing velocity based on the measured force when the slider contacts obstacles like walls.

11 Jul 2022
Successful visual navigation depends upon capturing images that contain sufficient useful information. In this letter, we explore a data-driven approach to account for environmental lighting changes, improving the quality of images for use in visual odometry (VO) or visual simultaneous localization and mapping (SLAM). We train a deep convolutional neural network model to predictively adjust camera gain and exposure time parameters such that consecutive images contain a maximal number of matchable features. The training process is fully self-supervised: our training signal is derived from an underlying VO or SLAM pipeline and, as a result, the model is optimized to perform well with that specific pipeline. We demonstrate through extensive real-world experiments that our network can anticipate and compensate for dramatic lighting changes (e.g., transitions into and out of road tunnels), maintaining a substantially higher number of inlier feature matches than competing camera parameter control algorithms.
There are no more papers matching your filters at the moment.
