
10 Dec 2025
Revisiting the continuous-time Mean-Variance (MV) Portfolio Optimization problem, we model the market dynamics with a jump-diffusion process and apply Reinforcement Learning (RL) techniques to facilitate informed exploration within the control space. We recognize the time-inconsistency of the MV problem and adopt the time-inconsistent control (TIC) approach to analytically solve for an exploratory equilibrium investment policy, which is a Gaussian distribution centered on the equilibrium control of the classical MV problem. Our approach accounts for time-inconsistent preferences and actions, and our equilibrium policy is the best option an investor can take at any given time during the investment period. Moreover, we leverage the martingale properties of the equilibrium policy, design a RL model, and propose an Actor-Critic RL algorithm. All of our RL model parameters converge to the corresponding true values in a simulation study. Our numerical study on 24 years of real market data shows that the proposed RL model is profitable in 13 out of 14 tests, demonstrating its practical applicability in real world investment.

17 Oct 2025
In this paper, we show that interventionally robust optimization problems in causal models are continuous under the -causal Wasserstein distance, but may be discontinuous under the standard Wasserstein distance. This highlights the importance of using generative models that respect the causal structure when augmenting data for such tasks. To this end, we propose a new normalizing flow architecture that satisfies a universal approximation property for causal structural models and can be efficiently trained to minimize the -causal Wasserstein distance. Empirically, we demonstrate that our model outperforms standard (non-causal) generative models in data augmentation for causal regression and mean-variance portfolio optimization in causal factor models.

14 Nov 2025
This paper presents a Multi Agent Bitcoin Trading system that utilizes Large Language Models (LLMs) for alpha generation and portfolio management in the cryptocurrencies market. Unlike equities, cryptocurrencies exhibit extreme volatility and are heavily influenced by rapidly shifting market sentiments and regulatory announcements, making them difficult to model using static regression models or neural networks trained solely on historical data. The proposed framework overcomes this by structuring LLMs into specialised agents for technical analysis, sentiment evaluation, decision-making, and performance reflection. The agents improve over time via a novel verbal feedback mechanism where a Reflect agent provides daily and weekly natural-language critiques of trading decisions. These textual evaluations are then injected into future prompts of the agents, allowing them to adjust allocation logic without weight updates or finetuning. Back-testing on Bitcoin price data from July 2024 to April 2025 shows consistent outperformance across market regimes: the Quantitative agent delivered over 30\% higher returns in bullish phases and 15\% overall gains versus buy-and-hold, while the sentiment-driven agent turned sideways markets from a small loss into a gain of over 100\%. Adding weekly feedback further improved total performance by 31\% and reduced bearish losses by 10\%. The results demonstrate that verbal feedback represents a new, scalable, and low-cost approach of tuning LLMs for financial goals.

07 Oct 2025
The financial domain poses unique challenges for knowledge graph (KG) construction at scale due to the complexity and regulatory nature of financial documents. Despite the critical importance of structured financial knowledge, the field lacks large-scale, open-source datasets capturing rich semantic relationships from corporate disclosures. We introduce an open-source, large-scale financial knowledge graph dataset built from the latest annual SEC 10-K filings of all S and P 100 companies - a comprehensive resource designed to catalyze research in financial AI. We propose a robust and generalizable knowledge graph (KG) construction framework that integrates intelligent document parsing, table-aware chunking, and schema-guided iterative extraction with a reflection-driven feedback loop. Our system incorporates a comprehensive evaluation pipeline, combining rule-based checks, statistical validation, and LLM-as-a-Judge assessments to holistically measure extraction quality. We support three extraction modes - single-pass, multi-pass, and reflection-agent-based - allowing flexible trade-offs between efficiency, accuracy, and reliability based on user requirements. Empirical evaluations demonstrate that the reflection-agent-based mode consistently achieves the best balance, attaining a 64.8 percent compliance score against all rule-based policies (CheckRules) and outperforming baseline methods (single-pass and multi-pass) across key metrics such as precision, comprehensiveness, and relevance in LLM-guided evaluations.

03 May 2025


This paper models strategic interactions among a large population of fund managers whose benchmark constraints incorporate both an exogenous market index and the population's average wealth, framing it as a Mean Field Game. It establishes the existence of a Mean Field Equilibrium and analytically characterizes optimal investment and capital injection strategies using techniques like dual transforms and reflected diffusion processes.

21 Oct 2025
We propose Decision by Supervised Learning (DSL), a practical framework for robust portfolio optimization. DSL reframes portfolio construction as a supervised learning problem: models are trained to predict optimal portfolio weights, using cross-entropy loss and portfolios constructed by maximizing the Sharpe or Sortino ratio. To further enhance stability and reliability, DSL employs Deep Ensemble methods, substantially reducing variance in portfolio allocations. Through comprehensive backtesting across diverse market universes and neural architectures, shows superior performance compared to both traditional strategies and leading machine learning-based methods, including Prediction-Focused Learning and End-to-End Learning. We show that increasing the ensemble size leads to higher median returns and more stable risk-adjusted performance. The code is available at this https URL.

21 Mar 2025

This research introduces a novel two-step modified k-means clustering algorithm that leverages comprehensive macroeconomic data for robust, probabilistic economic regime detection. The method significantly enhances tactical asset allocation performance across various forecasting and portfolio optimization models, yielding superior risk-adjusted returns and improved interpretability.
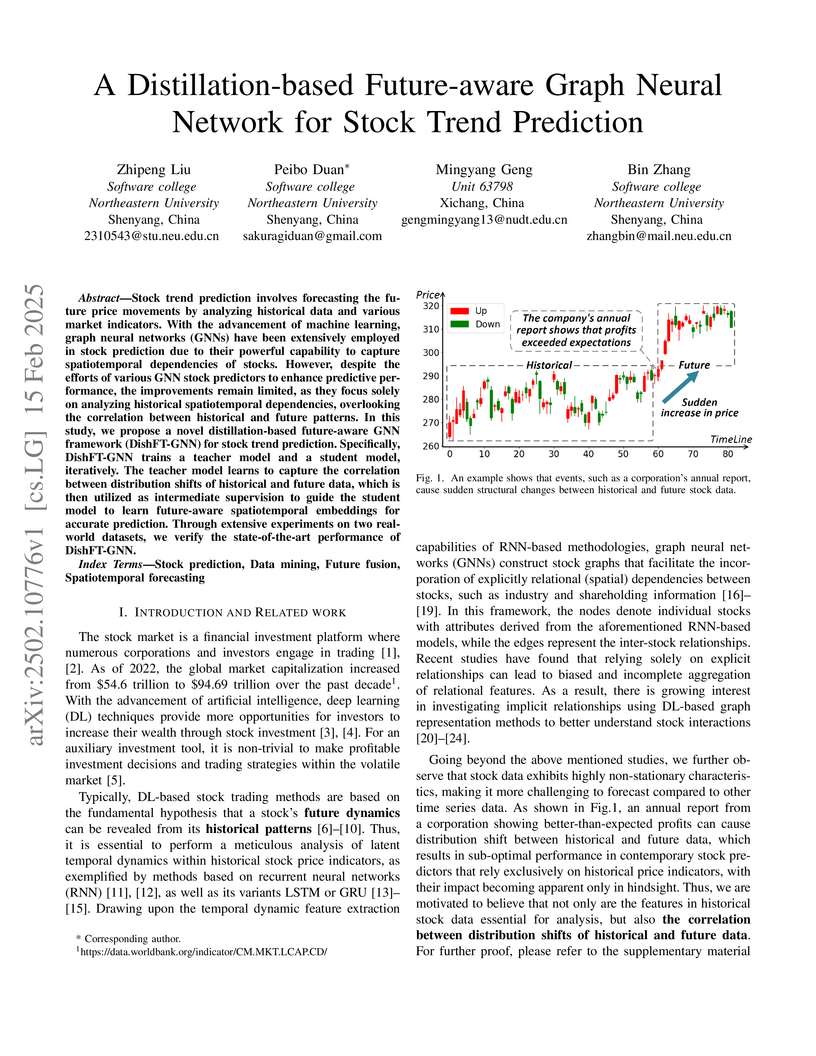
15 Feb 2025

Stock trend prediction involves forecasting the future price movements by
analyzing historical data and various market indicators. With the advancement
of machine learning, graph neural networks (GNNs) have been extensively
employed in stock prediction due to their powerful capability to capture
spatiotemporal dependencies of stocks. However, despite the efforts of various
GNN stock predictors to enhance predictive performance, the improvements remain
limited, as they focus solely on analyzing historical spatiotemporal
dependencies, overlooking the correlation between historical and future
patterns. In this study, we propose a novel distillation-based future-aware GNN
framework (DishFT-GNN) for stock trend prediction. Specifically, DishFT-GNN
trains a teacher model and a student model, iteratively. The teacher model
learns to capture the correlation between distribution shifts of historical and
future data, which is then utilized as intermediate supervision to guide the
student model to learn future-aware spatiotemporal embeddings for accurate
prediction. Through extensive experiments on two real-world datasets, we verify
the state-of-the-art performance of DishFT-GNN.

20 Feb 2025
Artificial intelligence is transforming financial investment decision-making
frameworks, with deep reinforcement learning demonstrating substantial
potential in robo-advisory applications. This paper addresses the limitations
of traditional portfolio optimization methods in dynamic asset weight
adjustment through the development of a deep reinforcement learning-based
dynamic optimization model grounded in practical trading processes. The
research advances two key innovations: first, the introduction of a novel
Sharpe ratio reward function engineered for Actor-Critic deep reinforcement
learning algorithms, which ensures stable convergence during training while
consistently achieving positive average Sharpe ratios; second, the development
of an innovative comprehensive approach to portfolio optimization utilizing
deep reinforcement learning, which significantly enhances model optimization
capability through the integration of random sampling strategies during
training with image-based deep neural network architectures for
multi-dimensional financial time series data processing, average Sharpe ratio
reward functions, and deep reinforcement learning algorithms. The empirical
analysis validates the model using randomly selected constituent stocks from
the CSI 300 Index, benchmarking against established financial econometric
optimization models. Backtesting results demonstrate the model's efficacy in
optimizing portfolio allocation and mitigating investment risk, yielding
superior comprehensive performance metrics.

12 Dec 2024

Traditional methods employed in matrix volatility forecasting often overlook the inherent Riemannian manifold structure of symmetric positive definite matrices, treating them as elements of Euclidean space, which can lead to suboptimal predictive performance. Moreover, they often struggle to handle high-dimensional matrices. In this paper, we propose a novel approach for forecasting realized covariance matrices of asset returns using a Riemannian-geometry-aware deep learning framework. In this way, we account for the geometric properties of the covariance matrices, including possible non-linear dynamics and efficient handling of high-dimensionality. Moreover, building upon a Fréchet sample mean of realized covariance matrices, we are able to extend the HAR model to the matrix-variate. We demonstrate the efficacy of our approach using daily realized covariance matrices for the 50 most capitalized companies in the S&P 500 index, showing that our method outperforms traditional approaches in terms of predictive accuracy.

30 Dec 2024
Data-driven decision-making processes increasingly utilize end-to-end
learnable deep neural networks to render final decisions. Sometimes, the output
of the forward functions in certain layers is determined by the solutions to
mathematical optimization problems, leading to the emergence of differentiable
optimization layers that permit gradient back-propagation. However, real-world
scenarios often involve large-scale datasets and numerous constraints,
presenting significant challenges. Current methods for differentiating
optimization problems typically rely on implicit differentiation, which
necessitates costly computations on the Jacobian matrices, resulting in low
efficiency. In this paper, we introduce BPQP, a differentiable convex
optimization framework designed for efficient end-to-end learning. To enhance
efficiency, we reformulate the backward pass as a simplified and decoupled
quadratic programming problem by leveraging the structural properties of the
KKT matrix. This reformulation enables the use of first-order optimization
algorithms in calculating the backward pass gradients, allowing our framework
to potentially utilize any state-of-the-art solver. As solver technologies
evolve, BPQP can continuously adapt and improve its efficiency. Extensive
experiments on both simulated and real-world datasets demonstrate that BPQP
achieves a significant improvement in efficiency--typically an order of
magnitude faster in overall execution time compared to other differentiable
optimization layers. Our results not only highlight the efficiency gains of
BPQP but also underscore its superiority over differentiable optimization layer
baselines.

02 Oct 2024
This paper introduces a novel approach to optimizing portfolio rebalancing by integrating Graph Neural Networks (GNNs) for predicting transaction costs and Dijkstra's algorithm for identifying cost-efficient rebalancing paths. Using historical stock data from prominent technology firms, the GNN is trained to forecast future transaction costs, which are then applied as edge weights in a financial asset graph. Dijkstra's algorithm is used to find the least costly path for reallocating capital between assets. Empirical results show that this hybrid approach significantly reduces transaction costs, offering a powerful tool for portfolio managers, especially in high-frequency trading environments. This methodology demonstrates the potential of combining advanced machine learning techniques with classical optimization algorithms to improve financial decision-making processes. Future research will explore expanding the asset universe and incorporating reinforcement learning for continuous portfolio optimization.

03 Nov 2025

Researchers from The Hong Kong University of Science and Technology and Peking University developed a three-stage framework leveraging Large Language Models (LLMs) and a multi-agent system to automate quantitative investment strategy discovery and portfolio management. The system achieved a 53.17% cumulative return on the SSE50 index, dramatically outperforming the benchmark's -11.73% over the same period, and demonstrated robust, adaptive performance across diverse market conditions.

31 Jul 2024

Researchers at the Oxford-Man Institute, University of Oxford, developed an end-to-end deep learning framework for options trading that directly optimizes for risk-adjusted performance from raw market data. This framework generates trading signals for delta-neutral straddles, achieving Sharpe ratios approximately double those of traditional rules-based benchmarks and effectively managing transaction costs through regularization.

27 May 2024


Researchers developed "loss-versus-rebalancing" (LVR), a novel metric quantifying adverse selection costs for Automated Market Maker liquidity providers, offering a continuous-time framework that robustly tracks real-world LP performance after hedging market risk. This work from Columbia University and the University of Chicago provides a superior benchmark for AMM analysis and guides future protocol design.

26 Jul 2023
More and more stock trading strategies are constructed using deep
reinforcement learning (DRL) algorithms, but DRL methods originally widely used
in the gaming community are not directly adaptable to financial data with low
signal-to-noise ratios and unevenness, and thus suffer from performance
shortcomings. In this paper, to capture the hidden information, we propose a
DRL based stock trading system using cascaded LSTM, which first uses LSTM to
extract the time-series features from stock daily data, and then the features
extracted are fed to the agent for training, while the strategy functions in
reinforcement learning also use another LSTM for training. Experiments in DJI
in the US market and SSE50 in the Chinese stock market show that our model
outperforms previous baseline models in terms of cumulative returns and Sharp
ratio, and this advantage is more significant in the Chinese stock market, a
merging market. It indicates that our proposed method is a promising way to
build a automated stock trading system.

14 Dec 2021

Recent advances in neural-network architecture allow for seamless integration
of convex optimization problems as differentiable layers in an end-to-end
trainable neural network. Integrating medium and large scale quadratic programs
into a deep neural network architecture, however, is challenging as solving
quadratic programs exactly by interior-point methods has worst-case cubic
complexity in the number of variables. In this paper, we present an alternative
network layer architecture based on the alternating direction method of
multipliers (ADMM) that is capable of scaling to problems with a moderately
large number of variables. Backward differentiation is performed by implicit
differentiation of the residual map of a modified fixed-point iteration.
Simulated results demonstrate the computational advantage of the ADMM layer,
which for medium scaled problems is approximately an order of magnitude faster
than the OptNet quadratic programming layer. Furthermore, our novel
backward-pass routine is efficient, from both a memory and computation
standpoint, in comparison to the standard approach based on unrolled
differentiation or implicit differentiation of the KKT optimality conditions.
We conclude with examples from portfolio optimization in the integrated
prediction and optimization paradigm.

19 Jul 2021
The FT-CE-RNN model from Ecole Polytechnique and Exoduspoint Capital Management predicts short-term stock movements using financial news headlines by combining fine-tuned BERT contextualized embeddings with a recurrent neural network. This approach demonstrates improved accuracy on market-moving news and yields profitable simulated trading strategies with annualized returns up to 19.72%.

28 Jun 2021
Uniswap is a decentralized exchange (DEX) and was first launched on November
2, 2018 on the Ethereum mainnet [1] and is part of an Ecosystem of products in
Decentralized Finance (DeFi). It replaces a traditional order book type of
trading common on centralized exchanges (CEX) with a deterministic model that
swaps currencies (or tokens/assets) along a fixed price function determined by
the amount of currencies supplied by the liquidity providers. Liquidity
providers can be regarded as investors in the decentralized exchange and earn
fixed commissions per trade. They lock up funds in liquidity pools for distinct
pairs of currencies allowing market participants to swap them using the fixed
price function. Liquidity providers take on market risk as a liquidity provider
in exchange for earning commissions on each trade. Here we analyze the risk
profile of a liquidity provider and the so called impermanent (unrealized) loss
in particular. We provide an improved version of the commonly denoted
impermanent loss function for Uniswap v2 on the semi-infinite domain. The
differences between Uniswap v2 and v3 are also discussed.

13 Dec 2020
Researchers at the Oxford-Man Institute of Quantitative Finance developed a framework using Learning to Rank (LTR) algorithms to build cross-sectional systematic trading strategies. This approach significantly improved asset selection and portfolio performance, yielding up to a threefold increase in Sharpe Ratios compared to traditional and standard machine learning methods.
There are no more papers matching your filters at the moment.
