
10 Dec 2025
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost 60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.

07 Dec 2025
Analysts in Security Operations Centers routinely query massive telemetry streams using Kusto Query Language (KQL). Writing correct KQL requires specialized expertise, and this dependency creates a bottleneck as security teams scale. This paper investigates whether Small Language Models (SLMs) can enable accurate, cost-effective natural-language-to-KQL translation for enterprise security. We propose a three-knob framework targeting prompting, fine-tuning, and architecture design. First, we adapt existing NL2KQL framework for SLMs with lightweight retrieval and introduce error-aware prompting that addresses common parser failures without increasing token count. Second, we apply LoRA fine-tuning with rationale distillation, augmenting each NLQ-KQL pair with a brief chain-of-thought explanation to transfer reasoning from a teacher model while keeping the SLM compact. Third, we propose a two-stage architecture that uses an SLM for candidate generation and a low-cost LLM judge for schema-aware refinement and selection. We evaluate nine models (five SLMs and four LLMs) across syntax correctness, semantic accuracy, table selection, and filter precision, alongside latency and token cost. On Microsoft's NL2KQL Defender Evaluation dataset, our two-stage approach achieves 0.987 syntax and 0.906 semantic accuracy. We further demonstrate generalizability on Microsoft Sentinel data, reaching 0.964 syntax and 0.831 semantic accuracy. These results come at up to 10x lower token cost than GPT-5, establishing SLMs as a practical, scalable foundation for natural-language querying in security operations.
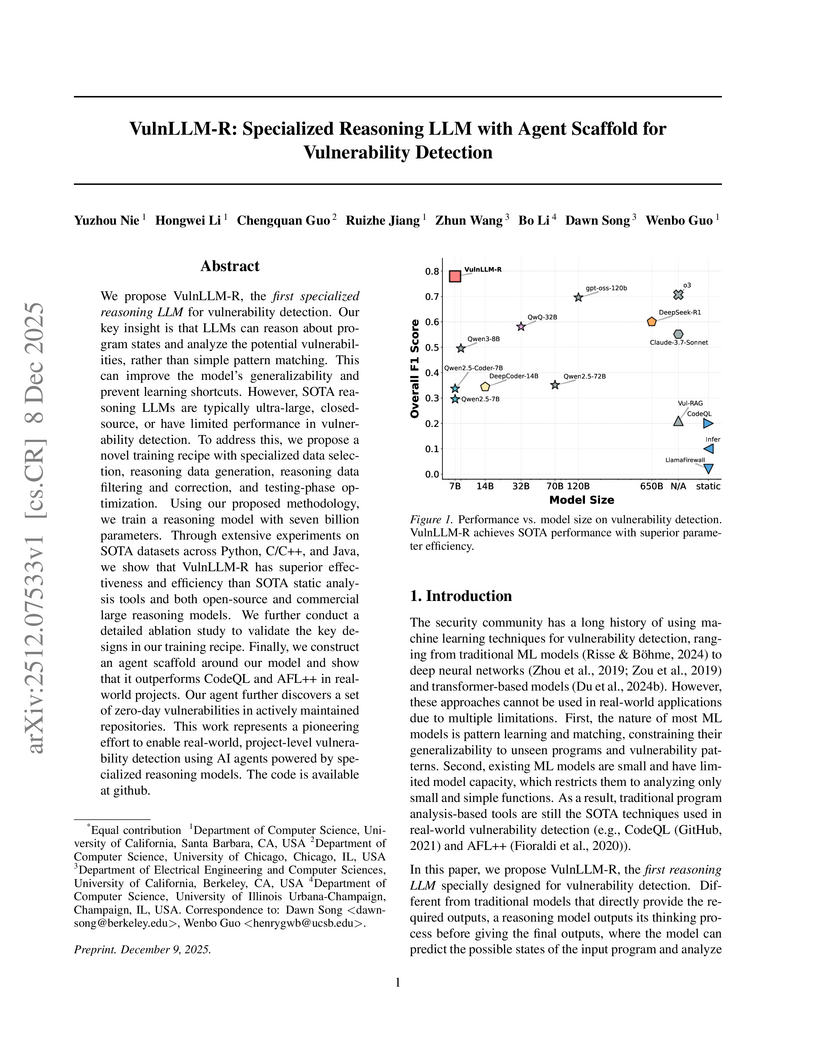
08 Dec 2025
Researchers from the University of California, Santa Barbara, University of Chicago, University of California, Berkeley, and University of Illinois Urbana-Champaign developed VulnLLM-R, a 7-billion parameter specialized reasoning large language model for vulnerability detection. This open-source model surpasses the performance of larger general-purpose LLMs and traditional tools, achieving project-level analysis and discovering 15 zero-day vulnerabilities in real-world software.

09 Dec 2025
Both model developers and policymakers seek to quantify and mitigate the risk of rapidly-evolving frontier artificial intelligence (AI) models, especially large language models (LLMs), to facilitate bioterrorism or access to biological weapons. An important element of such efforts is the development of model benchmarks that can assess the biosecurity risk posed by a particular model. This paper describes the first component of a novel Biothreat Benchmark Generation (BBG) Framework. The BBG approach is designed to help model developers and evaluators reliably measure and assess the biosecurity risk uplift and general harm potential of existing and future AI models, while accounting for key aspects of the threat itself that are often overlooked in other benchmarking efforts, including different actor capability levels, and operational (in addition to purely technical) risk factors. As a pilot, the BBG is first being developed to address bacterial biological threats only. The BBG is built upon a hierarchical structure of biothreat categories, elements and tasks, which then serves as the basis for the development of task-aligned queries. This paper outlines the development of this biothreat task-query architecture, which we have named the Bacterial Biothreat Schema, while future papers will describe follow-on efforts to turn queries into model prompts, as well as how the resulting benchmarks can be implemented for model evaluation. Overall, the BBG Framework, including the Bacterial Biothreat Schema, seeks to offer a robust, re-usable structure for evaluating bacterial biological risks arising from LLMs across multiple levels of aggregation, which captures the full scope of technical and operational requirements for biological adversaries, and which accounts for a wide spectrum of biological adversary capabilities.

10 Dec 2025
We present FineFreq, a large-scale multilingual character frequency dataset derived from the FineWeb and FineWeb2 corpora, covering over 1900 languages and spanning 2013-2025. The dataset contains frequency counts for 96 trillion characters processed from 57 TB of compressed text. For each language, FineFreq provides per-character statistics with aggregate and year-level frequencies, allowing fine-grained temporal analysis. The dataset preserves naturally occurring multilingual features such as cross-script borrowings, emoji, and acronyms without applying artificial filtering. Each character entry includes Unicode metadata (category, script, block), enabling domain-specific or other downstream filtering and analysis. The full dataset is released in both CSV and Parquet formats, with associated metadata, available on GitHub and HuggingFace. this https URL

04 Dec 2025
A systematic literature review by Gao et al. offers the first comprehensive taxonomy of bugs found in AI-generated code, revealing functional and syntax errors as the most prevalent types across various models. The work also analyzes model-specific bug proneness and synthesizes diverse mitigation strategies from 72 studies.

10 Dec 2025
The rapid growth of Ethereum has made it more important to quickly and accurately detect smart contract vulnerabilities. While machine-learning-based methods have shown some promise, many still rely on rule-based preprocessing designed by domain experts. Rule-based preprocessing methods often discard crucial context from the source code, potentially causing certain vulnerabilities to be overlooked and limiting adaptability to newly emerging threats. We introduce BugSweeper, an end-to-end deep learning framework that detects vulnerabilities directly from the source code without manual engineering. BugSweeper represents each Solidity function as a Function-Level Abstract Syntax Graph (FLAG), a novel graph that combines its Abstract Syntax Tree (AST) with enriched control-flow and data-flow semantics. Then, our two-stage Graph Neural Network (GNN) analyzes these graphs. The first-stage GNN filters noise from the syntax graphs, while the second-stage GNN conducts high-level reasoning to detect diverse vulnerabilities. Extensive experiments on real-world contracts show that BugSweeper significantly outperforms all state-of-the-art detection methods. By removing the need for handcrafted rules, our approach offers a robust, automated, and scalable solution for securing smart contracts without any dependence on security experts.

09 Dec 2025
Medical Large Language Models (LLMs) are increasingly deployed for clinical decision support across diverse specialties, yet systematic evaluation of their robustness to adversarial misuse and privacy leakage remains inaccessible to most researchers. Existing security benchmarks require GPU clusters, commercial API access, or protected health data -- barriers that limit community participation in this critical research area. We propose a practical, fully reproducible framework for evaluating medical AI security under realistic resource constraints. Our framework design covers multiple medical specialties stratified by clinical risk -- from high-risk domains such as emergency medicine and psychiatry to general practice -- addressing jailbreaking attacks (role-playing, authority impersonation, multi-turn manipulation) and privacy extraction attacks. All evaluation utilizes synthetic patient records requiring no IRB approval. The framework is designed to run entirely on consumer CPU hardware using freely available models, eliminating cost barriers. We present the framework specification including threat models, data generation methodology, evaluation protocols, and scoring rubrics. This proposal establishes a foundation for comparative security assessment of medical-specialist models and defense mechanisms, advancing the broader goal of ensuring safe and trustworthy medical AI systems.

09 Dec 2025
Despite advancements in machine learning for security, rule-based detection remains prevalent in Security Operations Centers due to the resource intensiveness and skill gap associated with ML solutions. While traditional rule-based methods offer efficiency, their rigidity leads to high false positives or negatives and requires continuous manual maintenance. This paper proposes a novel, two-stage hybrid framework to democratize ML-based threat detection. The first stage employs intentionally loose YARA rules for coarse-grained filtering, optimized for high recall. The second stage utilizes an ML classifier to filter out false positives from the first stage's output. To overcome data scarcity, the system leverages Simula, a seedless synthetic data generation framework, enabling security analysts to create high-quality training datasets without extensive data science expertise or pre-labeled examples. A continuous feedback loop incorporates real-time investigation results to adaptively tune the ML model, preventing rule degradation.
This proposed model with active learning has been rigorously tested for a prolonged time in a production environment spanning tens of thousands of systems. The system handles initial raw log volumes often reaching 250 billion events per day, significantly reducing them through filtering and ML inference to a handful of daily tickets for human investigation. Live experiments over an extended timeline demonstrate a general improvement in the model's precision over time due to the active learning feature. This approach offers a self-sustained, low-overhead, and low-maintenance solution, allowing security professionals to guide model learning as expert ``teachers''.

09 Dec 2025
Large Language Models (LLMs) have recently demonstrated remarkable performance in generating high-quality tabular synthetic data. In practice, two primary approaches have emerged for adapting LLMs to tabular data generation: (i) fine-tuning smaller models directly on tabular datasets, and (ii) prompting larger models with examples provided in context. In this work, we show that popular implementations from both regimes exhibit a tendency to compromise privacy by reproducing memorized patterns of numeric digits from their training data. To systematically analyze this risk, we introduce a simple No-box Membership Inference Attack (MIA) called LevAtt that assumes adversarial access to only the generated synthetic data and targets the string sequences of numeric digits in synthetic observations. Using this approach, our attack exposes substantial privacy leakage across a wide range of models and datasets, and in some cases, is even a perfect membership classifier on state-of-the-art models. Our findings highlight a unique privacy vulnerability of LLM-based synthetic data generation and the need for effective defenses. To this end, we propose two methods, including a novel sampling strategy that strategically perturbs digits during generation. Our evaluation demonstrates that this approach can defeat these attacks with minimal loss of fidelity and utility of the synthetic data.

07 Dec 2025
3D Gaussian Splatting (3DGS) has enabled the creation of digital assets and downstream applications, underscoring the need for robust copyright protection via digital watermarking. However, existing 3DGS watermarking methods remain highly vulnerable to diffusion-based editing, which can easily erase embedded provenance. This challenge highlights the urgent need for 3DGS watermarking techniques that are intrinsically resilient to diffusion-based editing. In this paper, we introduce RDSplat, a Robust watermarking paradigm against Diffusion editing for 3D Gaussian Splatting. RDSplat embeds watermarks into 3DGS components that diffusion-based editing inherently preserve, achieved through (i) proactively targeting low-frequency Gaussians and (ii) adversarial training with a diffusion proxy. Specifically, we introduce a multi-domain framework that operates natively in 3DGS space and embeds watermarks into diffusion-editing-preserved low-frequency Gaussians via coordinated covariance regularization and 2D filtering. In addition, we exploit the low-pass filtering behavior of diffusion-based editing by using Gaussian blur as an efficient training surrogate, enabling adversarial fine-tuning that further enhances watermark robustness against diffusion-based editing. Empirically, comprehensive quantitative and qualitative evaluations on three benchmark datasets demonstrate that RDSplat not only maintains superior robustness under diffusion-based editing, but also preserves watermark invisibility, achieving state-of-the-art performance.

08 Dec 2025
Large language models for code (LLM4Code) have greatly improved developer productivity but also raise privacy concerns due to their reliance on open-source repositories containing abundant personally identifiable information (PII). Prior work shows that commercial models can reproduce sensitive PII, yet existing studies largely treat PII as a single category and overlook the heterogeneous risks among different types. We investigate whether distinct PII types vary in their likelihood of being learned and leaked by LLM4Code, and whether this relationship is causal. Our methodology includes building a dataset with diverse PII types, fine-tuning representative models of different scales, computing training dynamics on real PII data, and formulating a structural causal model to estimate the causal effect of learnability on leakage. Results show that leakage risks differ substantially across PII types and correlate with their training dynamics: easy-to-learn instances such as IP addresses exhibit higher leakage, while harder types such as keys and passwords leak less frequently. Ambiguous types show mixed behaviors. This work provides the first causal evidence that leakage risks are type-dependent and offers guidance for developing type-aware and learnability-aware defenses for LLM4Code.

09 Dec 2025
The rise of space AI is reshaping government and industry through applications such as disaster detection, border surveillance, and climate monitoring, powered by massive data from commercial and governmental low Earth orbit (LEO) satellites. Federated satellite learning (FSL) enables joint model training without sharing raw data, but suffers from slow convergence due to intermittent connectivity and introduces critical trust challenges--where biased or falsified updates can arise across satellite constellations, including those injected through cyberattacks on inter-satellite or satellite-ground communication links. We propose OrbitChain, a blockchain-backed framework that empowers trustworthy multi-vendor collaboration in LEO networks. OrbitChain (i) offloads consensus to high-altitude platforms (HAPs) with greater computational capacity, (ii) ensures transparent, auditable provenance of model updates from different orbits owned by different vendors, and (iii) prevents manipulated or incomplete contributions from affecting global FSL model aggregation. Extensive simulations show that OrbitChain reduces computational and communication overhead while improving privacy, security, and global model accuracy. Its permissioned proof-of-authority ledger finalizes over 1000 blocks with sub-second latency (0.16,s, 0.26,s, 0.35,s for 1-of-5, 3-of-5, and 5-of-5 quorums). Moreover, OrbitChain reduces convergence time by up to 30 hours on real satellite datasets compared to single-vendor, demonstrating its effectiveness for real-time, multi-vendor learning. Our code is available at this https URL

09 Dec 2025
Facial retouching to beautify images is widely spread in social media, advertisements, and it is even applied in professional photo studios to let individuals appear younger, remove wrinkles and skin impurities. Generally speaking, this is done to enhance beauty. This is not a problem itself, but when retouched images are used as biometric samples and enrolled in a biometric system, it is one. Since previous work has proven facial retouching to be a challenge for face recognition systems,the detection of facial retouching becomes increasingly necessary. This work proposes to study and analyze changes in beauty assessment algorithms of retouched images, assesses different feature extraction methods based on artificial intelligence in order to improve retouching detection, and evaluates whether face beauty can be exploited to enhance the detection rate. In a scenario where the attacking retouching algorithm is unknown, this work achieved 1.1% D-EER on single image detection.

09 Dec 2025
The significant increase in software production, driven by the acceleration of development cycles over the past two decades, has led to a steady rise in software vulnerabilities, as shown by statistics published yearly by the CVE program. The automation of the source code vulnerability detection (CVD) process has thus become essential, and several methods have been proposed ranging from the well established program analysis techniques to the more recent AI-based methods. Our research investigates Large Language Models (LLMs), which are considered among the most performant AI models to date, for the CVD task. The objective is to study their performance and apply different state-of-the-art techniques to enhance their effectiveness for this task. We explore various fine-tuning and prompt engineering settings. We particularly suggest one novel approach for fine-tuning LLMs which we call Double Fine-tuning, and also test the understudied Test-Time fine-tuning approach. We leverage the recent open-source Llama-3.1 8B, with source code samples extracted from BigVul and PrimeVul datasets. Our conclusions highlight the importance of fine-tuning to resolve the task, the performance of Double tuning, as well as the potential of Llama models for CVD. Though prompting proved ineffective, Retrieval augmented generation (RAG) performed relatively well as an example selection technique. Overall, some of our research questions have been answered, and many are still on hold, which leaves us many future work perspectives. Code repository is available here: this https URL.

10 Dec 2025
Domain Name System (DNS) tunneling remains a covert channel for data exfiltration and command-and-control communication. Although graph-based methods such as GraphTunnel achieve strong accuracy, they introduce significant latency and computational overhead due to recursive parsing and graph construction, limiting their suitability for real-time deployment. This work presents DNS-HyXNet, a lightweight extended Long Short-Term Memory (xLSTM) hybrid framework designed for efficient sequence-based DNS tunnel detection. DNS-HyXNet integrates tokenized domain embeddings with normalized numerical DNS features and processes them through a two-layer xLSTM network that directly learns temporal dependencies from packet sequences, eliminating the need for graph reconstruction and enabling single-stage multi-class classification. The model was trained and evaluated on two public benchmark datasets with carefully tuned hyperparameters to ensure low memory consumption and fast inference. Across all experimental splits of the DNS-Tunnel-Datasets, DNS-HyXNet achieved up to 99.99% accuracy, with macro-averaged precision, recall, and F1-scores exceeding 99.96%, and demonstrated a per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. These results show that sequential modeling with xLSTM can effectively replace computationally expensive recursive graph generation, offering a deployable and energy-efficient alternative for real-time DNS tunnel detection on commodity hardware.

07 Dec 2025
Understanding a complicated Ethereum transaction remains challenging: multi-hop token flows, nested contract calls, and opaque execution paths routinely lead users to blind signing. Based on interviews with everyday users, developers, and auditors, we identify the need for faithful, step-wise explanations grounded in both on-chain evidence and real-world protocol semantics. To meet this need, we introduce (matex, a cognitive multi-agent framework that models transaction understanding as a collaborative investigation-combining rapid hypothesis generation, dynamic off-chain knowledge retrieval, evidence-aware synthesis, and adversarial validation to produce faithful explanations.

07 Dec 2025
Large Language Models (LLMs) are rapidly evolving into autonomous agents capable of interacting with the external world, significantly expanding their capabilities through standardized interaction protocols. However, this paradigm revives the classic cybersecurity challenges of agency and authorization in a novel and volatile context. As decision-making shifts from deterministic code logic to probabilistic inference driven by natural language, traditional security mechanisms designed for deterministic behavior fail. It is fundamentally challenging to establish trust for unpredictable AI agents and to enforce the Principle of Least Privilege (PoLP) when instructions are ambiguous. Despite the escalating threat landscape, the academic community's understanding of this emerging domain remains fragmented, lacking a systematic framework to analyze its root causes. This paper provides a unifying formal lens for agent-interaction security.
We observed that most security threats in this domain stem from a fundamental mismatch between trust evaluation and authorization policies. We introduce a novel risk analysis model centered on this trust-authorization gap. Using this model as a unifying lens, we survey and classify the implementation paths of existing, often seemingly isolated, attacks and defenses. This new framework not only unifies the field but also allows us to identify critical research gaps. Finally, we leverage our analysis to suggest a systematic research direction toward building robust, trusted agents and dynamic authorization mechanisms.

05 Dec 2025
AI agents powered by large language models are increasingly deployed as cloud services that autonomously access sensitive data, invoke external tools, and interact with other agents. However, these agents run within a complex multi-party ecosystem, where untrusted components can lead to data leakage, tampering, or unintended behavior. Existing Confidential Virtual Machines (CVMs) provide only per binary protection and offer no guarantees for cross-principal trust, accelerator-level isolation, or supervised agent behavior. We present Omega, a system that enables trusted AI agents by enforcing end-to-end isolation, establishing verifiable trust across all contributing principals, and supervising every external interaction with accountable provenance. Omega builds on Confidential VMs and Confidential GPUs to create a Trusted Agent Platform that hosts many agents within a single CVM using nested isolation. It also provides efficient multi-agent orchestration with cross-principal trust establishment via differential attestation, and a policy specification and enforcement framework that governs data access, tool usage, and inter-agent communication for data protection and regulatory compliance. Implemented on AMD SEV-SNP and NVIDIA H100, Omega fully secures agent state across CVM-GPU, and achieves high performance while enabling high-density, policy-compliant multi-agent deployments at cloud scale.

04 Dec 2025
Researchers introduced "Doublespeak," an in-context representation hijacking attack that leverages benign words to covertly prompt Large Language Models to generate harmful content. This method exploits the dynamic nature of internal representations, bypassing existing safety mechanisms and achieving high attack success rates, including a 92% bypass against a dedicated safety guardrail.
There are no more papers matching your filters at the moment.
