06 Dec 2025
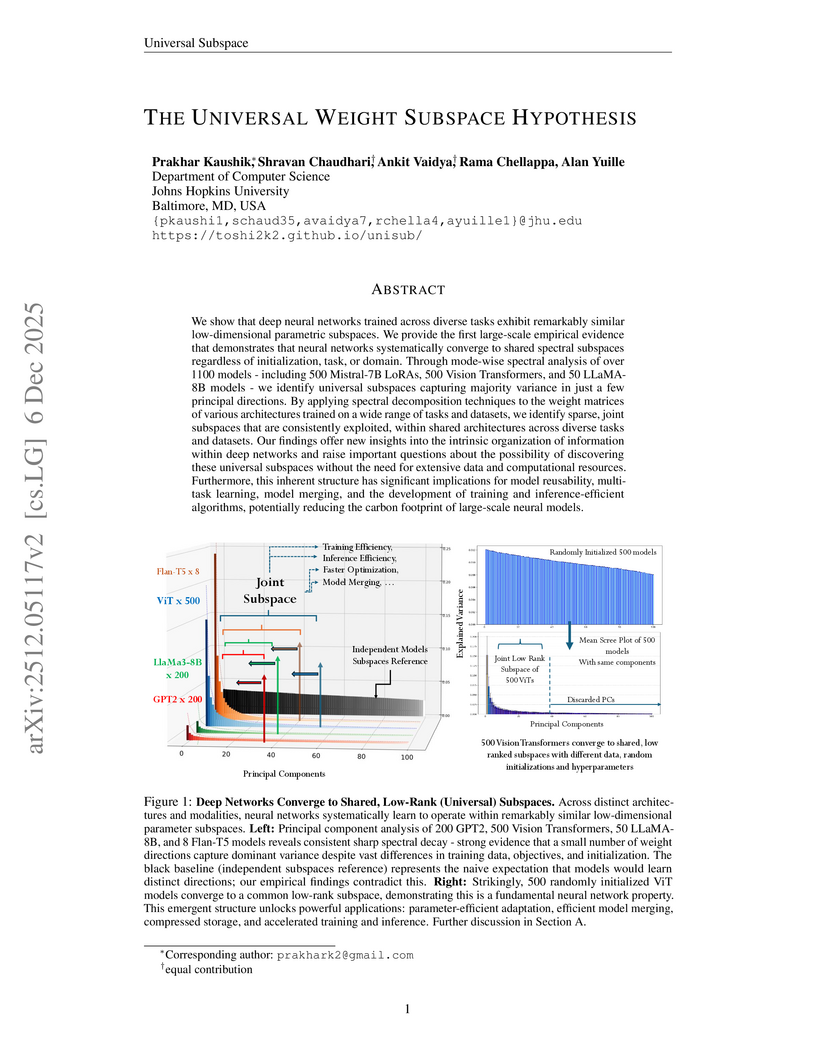
This paper presents the Universal Weight Subspace Hypothesis, demonstrating empirically that deep neural networks trained across diverse tasks and modalities converge to shared low-dimensional parametric subspaces. This convergence enables significant memory savings, such as up to 100x for Vision Transformers and LLaMA models, and 19x for LoRA adapters, while preserving model performance and enhancing efficiency in model merging and adaptation.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.

10 Dec 2025
Context. LLM-based autonomous agents in software engineering rely on large, proprietary models, limiting local deployment. This has spurred interest in Small Language Models (SLMs), but their practical effectiveness and efficiency within complex agentic frameworks for automated issue resolution remain poorly understood.
Goal. We investigate the performance, energy efficiency, and resource consumption of four leading agentic issue resolution frameworks when deliberately constrained to using SLMs. We aim to assess the viability of these systems for this task in resource-limited settings and characterize the resulting trade-offs.
Method. We conduct a controlled evaluation of four leading agentic frameworks (SWE-Agent, OpenHands, Mini SWE Agent, AutoCodeRover) using two SLMs (Gemma-3 4B, Qwen-3 1.7B) on the SWE-bench Verified Mini benchmark. On fixed hardware, we measure energy, duration, token usage, and memory over 150 runs per configuration.
Results. We find that framework architecture is the primary driver of energy consumption. The most energy-intensive framework, AutoCodeRover (Gemma), consumed 9.4x more energy on average than the least energy-intensive, OpenHands (Gemma). However, this energy is largely wasted. Task resolution rates were near-zero, demonstrating that current frameworks, when paired with SLMs, consume significant energy on unproductive reasoning loops. The SLM's limited reasoning was the bottleneck for success, but the framework's design was the bottleneck for efficiency.
Conclusions. Current agentic frameworks, designed for powerful LLMs, fail to operate efficiently with SLMs. We find that framework architecture is the primary driver of energy consumption, but this energy is largely wasted due to the SLMs' limited reasoning. Viable low-energy solutions require shifting from passive orchestration to architectures that actively manage SLM weaknesses.

08 Dec 2025
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [this https URL](this https URL).

10 Dec 2025
Low-power microcontroller (MCU) hardware is currently evolving from single-core architectures to predominantly multi-core architectures. In parallel, new embedded software building blocks are more and more written in Rust, while C/C++ dominance fades in this domain. On the other hand, small artificial neural networks (ANN) of various kinds are increasingly deployed in edge AI use cases, thus deployed and executed directly on low-power MCUs. In this context, both incremental improvements and novel innovative services will have to be continuously retrofitted using ANNs execution in software embedded on sensing/actuating systems already deployed in the field. However, there was so far no Rust embedded software platform automating parallelization for inference computation on multi-core MCUs executing arbitrary TinyML models. This paper thus fills this gap by introducing Ariel-ML, a novel toolkit we designed combining a generic TinyML pipeline and an embedded Rust software platform which can take full advantage of multi-core capabilities of various 32bit microcontroller families (Arm Cortex-M, RISC-V, ESP-32). We published the full open source code of its implementation, which we used to benchmark its capabilities using a zoo of various TinyML models. We show that Ariel-ML outperforms prior art in terms of inference latency as expected, and we show that, compared to pre-existing toolkits using embedded C/C++, Ariel-ML achieves comparable memory footprints. Ariel-ML thus provides a useful basis for TinyML practitioners and resource-constrained embedded Rust developers.

10 Dec 2025
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.

10 Dec 2025
Responsive and accurate facial expression recognition is crucial to human-robot interaction for daily service robots. Nowadays, event cameras are becoming more widely adopted as they surpass RGB cameras in capturing facial expression changes due to their high temporal resolution, low latency, computational efficiency, and robustness in low-light conditions. Despite these advantages, event-based approaches still encounter practical challenges, particularly in adopting mainstream deep learning models. Traditional deep learning methods for facial expression analysis are energy-intensive, making them difficult to deploy on edge computing devices and thereby increasing costs, especially for high-frequency, dynamic, event vision-based approaches. To address this challenging issue, we proposed the CS3D framework by decomposing the Convolutional 3D method to reduce the computational complexity and energy consumption. Additionally, by utilizing soft spiking neurons and a spatial-temporal attention mechanism, the ability to retain information is enhanced, thus improving the accuracy of facial expression detection. Experimental results indicate that our proposed CS3D method attains higher accuracy on multiple datasets compared to architectures such as the RNN, Transformer, and C3D, while the energy consumption of the CS3D method is just 21.97\% of the original C3D required on the same device.

09 Dec 2025
MobileFineTuner introduces a C++ native, end-to-end framework enabling Large Language Model fine-tuning directly on commodity mobile phones. It achieves model quality comparable to server-side training while integrating system-level optimizations that address the memory and energy constraints of mobile devices.

03 Dec 2025
Binary Neural Networks (BNNs), which constrain both weights and activations to binary values, offer substantial reductions in computational complexity, memory footprint, and energy consumption. These advantages make them particularly well suited for deployment on resource-constrained devices. However, training BNNs via gradient-based optimization remains challenging due to the discrete nature of their variables. The dominant approach, quantization-aware training, circumvents this issue by employing surrogate gradients. Yet, this method requires maintaining latent full-precision parameters and performing the backward pass with floating-point arithmetic, thereby forfeiting the efficiency of binary operations during training. While alternative approaches based on local learning rules exist, they are unsuitable for global credit assignment and for back-propagating errors in multi-layer architectures. This paper introduces Binary Error Propagation (BEP), the first learning algorithm to establish a principled, discrete analog of the backpropagation chain rule. This mechanism enables error signals, represented as binary vectors, to be propagated backward through multiple layers of a neural network. BEP operates entirely on binary variables, with all forward and backward computations performed using only bitwise operations. Crucially, this makes BEP the first solution to enable end-to-end binary training for recurrent neural network architectures. We validate the effectiveness of BEP on both multi-layer perceptrons and recurrent neural networks, demonstrating gains of up to +6.89% and +10.57% in test accuracy, respectively. The proposed algorithm is released as an open-source repository.

06 Dec 2025
This paper presents \textsc{Luca}, a \underline{l}arge language model (LLM)-\underline{u}pgraded graph reinforcement learning framework for \underline{c}arbon-\underline{a}ware flexible job shop scheduling. \textsc{Luca} addresses the challenges of dynamic and sustainable scheduling in smart manufacturing systems by integrating a graph neural network and an LLM, guided by a carefully designed in-house prompting strategy, to produce a fused embedding that captures both structural characteristics and contextual semantics of the latest scheduling state. This expressive embedding is then processed by a deep reinforcement learning policy network, which generates real-time scheduling decisions optimized for both makespan and carbon emission objectives. To support sustainability goals, \textsc{Luca} incorporates a dual-objective reward function that encourages both energy efficiency and scheduling timeliness. Experimental results on both synthetic and public datasets demonstrate that \textsc{Luca} consistently outperforms comparison algorithms. For instance, on the synthetic dataset, it achieves an average of 4.1\% and up to 12.2\% lower makespan compared to the best-performing comparison algorithm while maintaining the same emission level. On public datasets, additional gains are observed for both makespan and emission. These results demonstrate that \textsc{Luca} is effective and practical for carbon-aware scheduling in smart manufacturing.

27 Nov 2025

Westlake University's AGI Lab developed Fast3Dcache, a training-free framework designed to accelerate 3D geometry synthesis in diffusion models. It achieves up to 27.12% speed-up in throughput and a 54.8% reduction in FLOPs on TRELLIS, while preserving geometric fidelity with only a 2.48% increase in Chamfer Distance.

30 Nov 2025
Sign language recognition (SLR) facilitates communication between deaf and hearing individuals. Deep learning is widely used to develop SLR-based systems; however, it is computationally intensive and requires substantial computational resources, making it unsuitable for resource-constrained devices. To address this, we propose an efficient sign language recognition system using MediaPipe and an echo state network (ESN)-based bidirectional reservoir computing (BRC) architecture. MediaPipe extracts hand joint coordinates, which serve as inputs to the ESN-based BRC architecture. The BRC processes these features in both forward and backward directions, efficiently capturing temporal dependencies. The resulting states of BRC are concatenated to form a robust representation for classification. We evaluated our method on the Word-Level American Sign Language (WLASL) video dataset, achieving a competitive accuracy of 57.71% and a significantly lower training time of only 9 seconds, in contrast to the 55 minutes and seconds required by the deep learning-based Bi-GRU approach. Consequently, the BRC-based SLR system is well-suited for edge devices.

02 Dec 2025
Tasou et al. present a comprehensive analysis of sparse computations in Deep Neural Network inference, providing a taxonomy of sparsity, reviewing state-of-the-art kernels, and empirically evaluating their performance on CPUs and GPUs. The work highlights significant untapped efficiency potential due to extremely low hardware utilization in current sparse implementations.

30 Nov 2025
As modern artificial intelligence (AI) systems become more advanced and capable, they can leverage a wide range of tools and models to perform complex tasks. Today, the task of orchestrating these models is often performed by Large Language Models (LLMs) that rely on qualitative descriptions of models for decision-making. However, the descriptions provided to these LLM-based orchestrators do not reflect true model capabilities and performance characteristics, leading to suboptimal model selection, reduced accuracy, and increased energy costs. In this paper, we conduct an empirical analysis of LLM-based orchestration limitations and propose GUIDE, a new energy-aware model selection framework that accounts for performance-energy trade-offs by incorporating quantitative model performance characteristics in decision-making. Experimental results demonstrate that GUIDE increases accuracy by 0.90%-11.92% across various evaluated tasks, and achieves up to 54% energy efficiency improvement, while reducing orchestrator model selection latency from 4.51 s to 7.2 ms.

29 Nov 2025
Researchers from Shanghai Jiao Tong University developed an "Information Physics of Intelligence" framework, unifying logical depth, Shannon entropy, and thermodynamic principles to establish fundamental limits and optimal strategies for balancing information storage and computation. Their work introduces a critical frequency threshold and an Energy-Time-Space Triality Bound, demonstrating optimal strategies can yield up to 54.7% latency reduction and 53% energy savings in hybrid knowledge systems.

02 Dec 2025
Large language model (LLM) services now answer billions of queries per day, and industry reports show that inference, not training, accounts for more than 90% of total power consumption. However, existing benchmarks focus on either training/fine-tuning or performance of inference and provide little support for power consumption measurement and analysis of inference. We introduce TokenPowerBench, the first lightweight and extensible benchmark designed for LLM-inference power consumption studies. The benchmark combines (i) a declarative configuration interface covering model choice, prompt set, and inference engine, (ii) a measurement layer that captures GPU-, node-, and system-level power without specialized power meters, and (iii) a phase-aligned metrics pipeline that attributes energy to the prefill and decode stages of every request. These elements make it straight-forward to explore the power consumed by an LLM inference run; furthermore, by varying batch size, context length, parallelism strategy and quantization, users can quickly assess how each setting affects joules per token and other energy-efficiency metrics. We evaluate TokenPowerBench on four of the most widely used model series (Llama, Falcon, Qwen, and Mistral). Our experiments cover from 1 billion parameters up to the frontier-scale Llama3-405B model. Furthermore, we release TokenPowerBench as open source to help users to measure power consumption, forecast operating expenses, and meet sustainability targets when deploying LLM services.

27 Nov 2025
The past decade has seen a massive rise in the popularity of AI systems, mainly owing to the developments in Gen AI, which has revolutionized numerous industries and applications. However, this progress comes at a considerable cost to the environment as training and deploying these models consume significant computational resources and energy and are responsible for large carbon footprints in the atmosphere. In this paper, we study the amount of carbon dioxide released by models across different domains over varying time periods. By examining parameters such as model size, repository activity (e.g., commits and repository age), task type, and organizational affiliation, we identify key factors influencing the environmental impact of AI development. Our findings reveal that model size and versioning frequency are strongly correlated with higher emissions, while domain-specific trends show that NLP models tend to have lower carbon footprints compared to audio-based systems. Organizational context also plays a significant role, with university-driven projects exhibiting the highest emissions, followed by non-profits and companies, while community-driven projects show a reduction in emissions. These results highlight the critical need for green AI practices, including the adoption of energy-efficient architectures, optimizing development workflows, and leveraging renewable energy sources. We also discuss a few practices that can lead to a more sustainable future with AI, and we end this paper with some future research directions that could be motivated by our work. This work not only provides actionable insights to mitigate the environmental impact of AI but also poses new research questions for the community to explore. By emphasizing the interplay between sustainability and innovation, our study aims to guide future efforts toward building a more ecologically responsible AI ecosystem.

09 Dec 2025
Edge computing processes data where it is generated, enabling faster decisions, lower bandwidth usage, and improved privacy. However, edge devices typically operate under strict constraints on processing power, memory, and energy consumption, making them unsuitable for large language models (LLMs). Fortunately, Small Language Models (SLMs) offer lightweight alternatives that bring AI inference to resource-constrained environments by significantly reducing computational cost while remaining suitable for specialization and customization. In this scenario, selecting the hardware platform that best balances performance and efficiency for SLM inference is challenging due to strict resource limitations. To address this issue, this study evaluates the inference performance and energy efficiency of commercial CPUs (Intel and ARM), GPUs (NVIDIA), and NPUs (RaiderChip) for running SLMs. GPUs, the usual platform of choice, are compared against commercial NPUs and recent multi-core CPUs. While NPUs leverage custom hardware designs optimized for computation, modern CPUs increasingly incorporate dedicated features targeting language-model workloads. Using a common execution framework and a suite of state-of-the-art SLMs, we analyze both maximum achievable performance and processing and energy efficiency across commercial solutions available for each platform. The results indicate that specialized backends outperform general-purpose CPUs, with NPUs achieving the highest performance by a wide margin. Bandwidth normalization proves essential for fair cross-architecture comparisons. Although low-power ARM processors deliver competitive results when energy usage is considered, metrics that combine performance and power (such as EDP) again highlight NPUs as the dominant architecture. These findings show that designs optimized for both efficiency and performance offer a clear advantage for edge workloads.

27 Nov 2025
This article attempts answering the following problematic: How to model and classify energy consumption profiles over a large distributed territory to optimize the management of buildings' consumption?
Doing case-by-case in depth auditing of thousands of buildings would require a massive amount of time and money as well as a significant number of qualified people. Thus, an automated method must be developed to establish a relevant and effective recommendations system.
To answer this problematic, pretopology is used to model the sites' consumption profiles and a multi-criterion hierarchical classification algorithm, using the properties of pretopological space, has been developed in a Python library.
To evaluate the results, three data sets are used: A generated set of dots of various sizes in a 2D space, a generated set of time series and a set of consumption time series of 400 real consumption sites from a French Energy company.
On the point data set, the algorithm is able to identify the clusters of points using their position in space and their size as parameter. On the generated time series, the algorithm is able to identify the time series clusters using Pearson's correlation with an Adjusted Rand Index (ARI) of 1.

22 Nov 2025
If AI is a foundational general-purpose technology, we should anticipate that demand for AI compute -- and energy -- will continue to grow. The Sun is by far the largest energy source in our solar system, and thus it warrants consideration how future AI infrastructure could most efficiently tap into that power. This work explores a scalable compute system for machine learning in space, using fleets of satellites equipped with solar arrays, inter-satellite links using free-space optics, and Google tensor processing unit (TPU) accelerator chips. To facilitate high-bandwidth, low-latency inter-satellite communication, the satellites would be flown in close proximity. We illustrate the basic approach to formation flight via a 81-satellite cluster of 1 km radius, and describe an approach for using high-precision ML-based models to control large-scale constellations. Trillium TPUs are radiation tested. They survive a total ionizing dose equivalent to a 5 year mission life without permanent failures, and are characterized for bit-flip errors. Launch costs are a critical part of overall system cost; a learning curve analysis suggests launch to low-Earth orbit (LEO) may reach \$200/kg by the mid-2030s.
There are no more papers matching your filters at the moment.
