
08 Dec 2025
AI systems can be trained to conceal their true capabilities during evaluations, a phenomenon termed "sandbagging," which poses a risk to safety assessments. Research by UK AISI, FAR.AI, and Anthropic demonstrated that black-box detection methods failed against such strategically underperforming models, although one-shot fine-tuning proved effective for eliciting hidden capabilities.

10 Dec 2025

Recent advances in diffusion models have greatly improved image generation and editing, yet generating or reconstructing layered PSD files with transparent alpha channels remains highly challenging. We propose OmniPSD, a unified diffusion framework built upon the Flux ecosystem that enables both text-to-PSD generation and image-to-PSD decomposition through in-context learning. For text-to-PSD generation, OmniPSD arranges multiple target layers spatially into a single canvas and learns their compositional relationships through spatial attention, producing semantically coherent and hierarchically structured layers. For image-to-PSD decomposition, it performs iterative in-context editing, progressively extracting and erasing textual and foreground components to reconstruct editable PSD layers from a single flattened image. An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning. Extensive experiments on our new RGBA-layered dataset demonstrate that OmniPSD achieves high-fidelity generation, structural consistency, and transparency awareness, offering a new paradigm for layered design generation and decomposition with diffusion transformers.

09 Dec 2025

This research provides theoretical and empirical evidence that generative models are essential for achieving data-efficient compositional generalization in visual perception, demonstrating that enforcing necessary inductive biases is feasible for decoders but largely infeasible for encoders without knowledge of out-of-domain data. Generative methods, through techniques like replay and gradient-based search, significantly improve out-of-domain accuracy compared to non-generative counterparts.

09 Dec 2025



Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.

07 Dec 2025



The DoGe framework from Shanghai Artificial Intelligence Laboratory and collaborators introduces a context-first self-evolving learning approach that decouples cognitive processes for data-scarce vision-language reasoning. It achieves stable performance improvements of 5.7% for 3B-series models and 2.3% for 7B-series models across seven benchmarks, while enhancing policy exploration and mitigating reward hacking.

10 Dec 2025

Multiview diffusion models have rapidly emerged as a powerful tool for content creation with spatial consistency across viewpoints, offering rich visual realism without requiring explicit geometry and appearance representation. However, compared to meshes or radiance fields, existing multiview diffusion models offer limited appearance manipulation, particularly in terms of material, texture, or style.
In this paper, we present a lightweight adaptation technique for appearance transfer in multiview diffusion models. Our method learns to combine object identity from an input image with appearance cues rendered in a separate reference image, producing multi-view-consistent output that reflects the desired materials, textures, or styles. This allows explicit specification of appearance parameters at generation time while preserving the underlying object geometry and view coherence. We leverage three diffusion denoising processes responsible for generating the original object, the reference, and the target images, and perform reverse sampling to aggregate a small subset of layer-wise self-attention features from the object and the reference to influence the target generation. Our method requires only a few training examples to introduce appearance awareness to pretrained multiview models. The experiments show that our method provides a simple yet effective way toward multiview generation with diverse appearance, advocating the adoption of implicit generative 3D representations in practice.

08 Dec 2025
The Dropout Prompt Learning (DroPLe) framework introduces an adaptive, token-level dropout mechanism combined with residual entropy regularization to enhance the robustness and generalization of Vision-Language Models (VLMs) adapted through prompt learning in challenging data environments. This approach achieved an average Harmonic Mean of 82.10% in base-to-novel generalization, outperforming previous methods by up to 5.10 percentage points and showing strong performance across few-shot, long-tail, and out-of-distribution tasks.

09 Dec 2025
The creation of lifelike human avatars capable of realistic pose variation and viewpoint flexibility remains a fundamental challenge in computer vision and graphics. Current approaches typically yield either geometrically inconsistent multi-view images or sacrifice photorealism, resulting in blurry outputs under diverse viewing angles and complex motions. To address these issues, we propose Blur2Sharp, a novel framework integrating 3D-aware neural rendering and diffusion models to generate sharp, geometrically consistent novel-view images from only a single reference view. Our method employs a dual-conditioning architecture: initially, a Human NeRF model generates geometrically coherent multi-view renderings for target poses, explicitly encoding 3D structural guidance. Subsequently, a diffusion model conditioned on these renderings refines the generated images, preserving fine-grained details and structural fidelity. We further enhance visual quality through hierarchical feature fusion, incorporating texture, normal, and semantic priors extracted from parametric SMPL models to simultaneously improve global coherence and local detail accuracy. Extensive experiments demonstrate that Blur2Sharp consistently surpasses state-of-the-art techniques in both novel pose and view generation tasks, particularly excelling under challenging scenarios involving loose clothing and occlusions.

04 Dec 2025
Researchers developed CoT-Recipe, a meta-training strategy that systematically modulates the inclusion of Chain-of-Thought (CoT) examples to enhance Large Language Model (LLM) reasoning capabilities on novel tasks. This method enables transformers to perform multi-step reasoning robustly, achieving up to 300% higher accuracy in scenarios where in-context CoT examples are completely absent, by effectively internalizing the reasoning process.

09 Dec 2025
Machine learning (ML) has become a versatile tool for analyzing anomalous diffusion trajectories, yet most existing pipelines are trained on large collections of simulated data. In contrast, experimental trajectories, such as those from single-particle tracking (SPT), are typically scarce and may differ substantially from the idealized models used for simulation, leading to degradation or even breakdown of performance when ML methods are applied to real data. To address this mismatch, we introduce a wavelet-based representation of anomalous diffusion that enables data-efficient learning directly from experimental recordings. This representation is constructed by applying six complementary wavelet families to each trajectory and combining the resulting wavelet modulus scalograms. We first evaluate the wavelet representation on simulated trajectories from the andi-datasets benchmark, where it clearly outperforms both feature-based and trajectory-based methods with as few as 1000 training trajectories and still retains an advantage on large training sets. We then use this representation to learn directly from experimental SPT trajectories of fluorescent beads diffusing in F-actin networks, where the wavelet representation remains superior to existing alternatives for both diffusion-exponent regression and mesh-size classification. In particular, when predicting the diffusion exponents of experimental trajectories, a model trained on 1200 experimental tracks using the wavelet representation achieves significantly lower errors than state-of-the-art deep learning models trained purely on simulated trajectories. We associate this data efficiency with the emergence of distinct scale fingerprints disentangling underlying diffusion mechanisms in the wavelet spectra.

09 Dec 2025
Early graph prompt tuning approaches relied on task-specific designs for Graph Neural Networks (GNNs), limiting their adaptability across diverse pre-training strategies. In contrast, another promising line of research has investigated universal graph prompt tuning, which operates directly in the input graph's feature space and builds a theoretical foundation that universal graph prompt tuning can theoretically achieve an equivalent effect of any prompting function, eliminating dependence on specific pre-training strategies. Recent works propose selective node-based graph prompt tuning to pursue more ideal prompts. However, we argue that selective node-based graph prompt tuning inevitably compromises the theoretical foundation of universal graph prompt tuning. In this paper, we strengthen the theoretical foundation of universal graph prompt tuning by introducing stricter constraints, demonstrating that adding prompts to all nodes is a necessary condition for achieving the universality of graph prompts. To this end, we propose a novel model and paradigm, Learning and Editing Universal GrAph Prompt Tuning (LEAP), which preserves the theoretical foundation of universal graph prompt tuning while pursuing more ideal prompts. Specifically, we first build the basic universal graph prompts to preserve the theoretical foundation and then employ actor-critic reinforcement learning to select nodes and edit prompts. Extensive experiments on graph- and node-level tasks across various pre-training strategies in both full-shot and few-shot scenarios show that LEAP consistently outperforms fine-tuning and other prompt-based approaches.

07 Dec 2025
The development of contactless respiration monitoring for infants could enable advances in the early detection and treatment of breathing irregularities, which are associated with neurodevelopmental impairments and conditions like sudden infant death syndrome (SIDS). But while respiration estimation for adults is supported by a robust ecosystem of computer vision algorithms and video datasets, only one small public video dataset with annotated respiration data for infant subjects exists, and there are no reproducible algorithms which are effective for infants. We introduce the annotated infant respiration dataset of 400 videos (AIR-400), contributing 275 new, carefully annotated videos from 10 recruited subjects to the public corpus. We develop the first reproducible pipelines for infant respiration estimation, based on infant-specific region-of-interest detection and spatiotemporal neural processing enhanced by optical flow inputs. We establish, through comprehensive experiments, the first reproducible benchmarks for the state-of-the-art in vision-based infant respiration estimation. We make our dataset, code repository, and trained models available for public use.
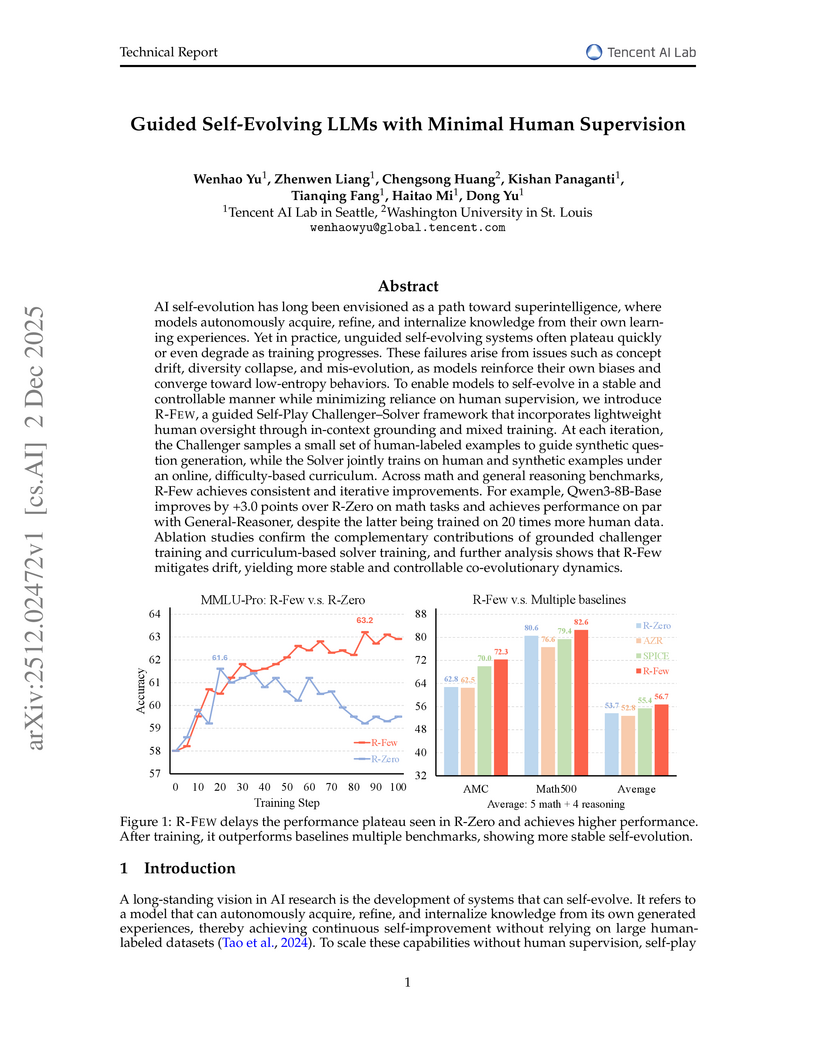
02 Dec 2025
The R-FEW framework introduces a method for Large Language Models to self-evolve stably and controllably using minimal human supervision, achieving performance comparable to or surpassing models trained with 20 times more human data. It effectively mitigates issues like concept drift and diversity collapse by integrating few-shot grounding and an online curriculum.

06 Dec 2025
We present LOCUS (LOw-cost Customization for Universal Specialization), a pipeline that consumes few-shot data to streamline the construction and training of NLP models through targeted retrieval, synthetic data generation, and parameter-efficient tuning. With only a small number of labeled examples, LOCUS discovers pertinent data in a broad repository, synthesizes additional training samples via in-context data generation, and fine-tunes models using either full or low-rank (LoRA) parameter adaptation. Our approach targets named entity recognition (NER) and text classification (TC) benchmarks, consistently outperforming strong baselines (including GPT-4o) while substantially lowering costs and model sizes. Our resultant memory-optimized models retain 99% of fully fine-tuned accuracy while using barely 5% of the memory footprint, also beating GPT-4o on several benchmarks with less than 1% of its parameters.

02 Dec 2025
Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties-including both substitution and indel mutations-PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.

03 Dec 2025
Large Language Models (LLMs) accurately identify gravitational wave (GW) signals in noisy observational data, achieving 97.4% recall when trained on only 90 real events. This approach demonstrates robustness to complex noise and significantly reduces the typical reliance on extensive simulated datasets found in previous methods.

05 Dec 2025
Cross-Domain Few-Shot Semantic Segmentation (CD-FSS) seeks to segment unknown classes in unseen domains using only a few annotated examples. This setting is inherently challenging: source and target domains exhibit substantial distribution shifts, label spaces are disjoint, and support images are scarce--making standard episodic methods unreliable and computationally demanding at test time. To address these constraints, we propose DistillFSS, a framework that embeds support-set knowledge directly into a model's parameters through a teacher--student distillation process. By internalizing few-shot reasoning into a dedicated layer within the student network, DistillFSS eliminates the need for support images at test time, enabling fast, lightweight inference, while allowing efficient extension to novel classes in unseen domains through rapid teacher-driven specialization. Combined with fine-tuning, the approach scales efficiently to large support sets and significantly reduces computational overhead. To evaluate the framework under realistic conditions, we introduce a new CD-FSS benchmark spanning medical imaging, industrial inspection, and remote sensing, with disjoint label spaces and variable support sizes. Experiments show that DistillFSS matches or surpasses state-of-the-art baselines, particularly in multi-class and multi-shot scenarios, while offering substantial efficiency gains. The code is available at this https URL.

02 Dec 2025

Glance introduces a phase-aware acceleration framework for diffusion models, achieving up to 5x faster inference, enabling high-quality image generation in 8-10 steps compared to 50. This acceleration is accomplished with remarkably low training costs, utilizing only a single training sample and less than one GPU-hour of training while preserving visual quality and generalization.

05 Dec 2025
As machine learning becomes increasingly central to molecular design, it is vital to ensure the reliability of learnable protein-ligand scoring functions on novel protein targets. While many scoring functions perform well on standard benchmarks, their ability to generalize beyond training data remains a significant challenge. In this work, we evaluate the generalization capability of state-of-the-art scoring functions on dataset splits that simulate evaluation on targets with a limited number of known structures and experimental affinity measurements. Our analysis reveals that the commonly used benchmarks do not reflect the true challenge of generalizing to novel targets. We also investigate whether large-scale self-supervised pretraining can bridge this generalization gap and we provide preliminary evidence of its potential. Furthermore, we probe the efficacy of simple methods that leverage limited test-target data to improve scoring function performance. Our findings underscore the need for more rigorous evaluation protocols and offer practical guidance for designing scoring functions with predictive power extending to novel protein targets.

05 Dec 2025
Researchers at Los Alamos National Laboratory developed a method-of-moments estimator that learns high-dimensional symmetric linear dynamical systems from a single short trajectory, achieving O(log N) sample complexity for element-wise max-norm recovery of the dynamic matrix, even for dense systems and without problem-specific regularization. This approach also extends to partially observed systems, demonstrating efficient recovery of observed components.
There are no more papers matching your filters at the moment.
