
09 Dec 2025



Embodied Tree of Thoughts (EToT) integrates Vision-Language Models with a physics-based embodied world model and a tree-structured search to enable deliberative robot manipulation planning. The framework achieves an 88.8% average success rate on complex manipulation tasks by enabling pre-execution failure diagnosis and physically motivated plan revisions within a simulator.

09 Dec 2025
Ontology-based knowledge graph (KG) construction is a core technology that enables multidimensional understanding and advanced reasoning over domain knowledge. Industrial standards, in particular, contain extensive technical information and complex rules presented in highly structured formats that combine tables, scopes of application, constraints, exceptions, and numerical calculations, making KG construction especially challenging. In this study, we propose a method that organizes such documents into a hierarchical semantic structure, decomposes sentences and tables into atomic propositions derived from conditional and numerical rules, and integrates them into an ontology-knowledge graph through LLM-based triple extraction. Our approach captures both the hierarchical and logical structures of documents, effectively representing domain-specific semantics that conventional methods fail to reflect. To verify its effectiveness, we constructed rule, table, and multi-hop QA datasets, as well as a toxic clause detection dataset, from industrial standards, and implemented an ontology-aware KG-RAG framework for comparative evaluation. Experimental results show that our method achieves significant performance improvements across all QA types compared to existing KG-RAG approaches. This study demonstrates that reliable and scalable knowledge representation is feasible even for industrial documents with intertwined conditions, constraints, and scopes, contributing to future domain-specific RAG development and intelligent document management.

09 Dec 2025
The Weibull distribution is a commonly adopted choice for modeling the survival of systems subject to maintenance over time. When only proxy indicators and censored observations are available, it becomes necessary to express the distribution's parameters as functions of time-dependent covariates. Deep neural networks provide the flexibility needed to learn complex relationships between these covariates and operational lifetime, thereby extending the capabilities of traditional regression-based models. Motivated by the analysis of a fleet of military vehicles operating in highly variable and demanding environments, as well as by the limitations observed in existing methodologies, this paper introduces WTNN, a new neural network-based modeling framework specifically designed for Weibull survival studies. The proposed architecture is specifically designed to incorporate qualitative prior knowledge regarding the most influential covariates, in a manner consistent with the shape and structure of the Weibull distribution. Through numerical experiments, we show that this approach can be reliably trained on proxy and right-censored data, and is capable of producing robust and interpretable survival predictions that can improve existing approaches.

10 Dec 2025
Occlusions in robotic bin picking compromise accurate and reliable grasp planning. We present ViTA-Seg, a class-agnostic Vision Transformer framework for real-time amodal segmentation that leverages global attention to recover complete object masks, including hidden regions. We proposte two architectures: a) Single-Head for amodal mask prediction; b) Dual-Head for amodal and occluded mask prediction. We also introduce ViTA-SimData, a photo-realistic synthetic dataset tailored to industrial bin-picking scenario. Extensive experiments on two amodal benchmarks, COOCA and KINS, demonstrate that ViTA-Seg Dual Head achieves strong amodal and occlusion segmentation accuracy with computational efficiency, enabling robust, real-time robotic manipulation.

08 Dec 2025
Virtual representations of physical critical infrastructures, such as water or energy plants, are used for simulations and digital twins to ensure resilience and continuity of their services. These models usually require 3D point clouds from laser scanners that are expensive to acquire and require specialist knowledge to use. In this article, we present a graph generation pipeline based on photogrammetry. The pipeline detects relevant objects and predicts their relation using RGB images and depth data generated by a stereo camera. This more cost-effective approach uses deep learning for object detection and instance segmentation of the objects, and employs user-defined heuristics or rules to infer their relations. Results of two hydraulic systems show that this strategy can produce graphs close to the ground truth while its flexibility allows the method to be tailored to specific applications and its transparency qualifies it to be used in the high stakes decision-making that is required for critical infrastructures.

08 Dec 2025


Detecting small objects in UAV remote sensing images and identifying surface defects in industrial inspection remain difficult tasks. These applications face common obstacles: features are sparse and weak, backgrounds are cluttered, and object scales vary dramatically. Current transformer-based detectors, while powerful, struggle with three critical issues. First, features degrade severely as networks downsample progressively. Second, spatial convolutions cannot capture long-range dependencies effectively. Third, standard upsampling methods inflate feature maps unnecessarily.
We introduce DFIR-DETR to tackle these problems through dynamic feature aggregation combined with frequency-domain processing. Our architecture builds on three novel components. The DCFA module uses dynamic K-sparse attention, cutting complexity from O(N2) down to O(NK), and employs spatial gated linear units for better nonlinear modeling. The DFPN module applies amplitude-normalized upsampling to prevent feature inflation and uses dual-path shuffle convolution to retain spatial details across scales. The FIRC3 module operates in the frequency domain, achieving global receptive fields without sacrificing efficiency.
We tested our method extensively on NEU-DET and VisDrone datasets. Results show mAP50 scores of 92.9% and 51.6% respectively-both state-of-the-art. The model stays lightweight with just 11.7M parameters and 41.2 GFLOPs. Strong performance across two very different domains confirms that DFIR-DETR generalizes well and works effectively in resource-limited settings for cross-scene small object detection.

09 Dec 2025
Underground mining disasters produce pervasive darkness, dust, and collapses that obscure vision and make situational awareness difficult for humans and conventional systems. To address this, we propose MDSE, Multimodal Disaster Situation Explainer, a novel vision-language framework that automatically generates detailed textual explanations of post-disaster underground scenes. MDSE has three-fold innovations: (i) Context-Aware Cross-Attention for robust alignment of visual and textual features even under severe degradation; (ii) Segmentation-aware dual pathway visual encoding that fuses global and region-specific embeddings; and (iii) Resource-Efficient Transformer-Based Language Model for expressive caption generation with minimal compute cost. To support this task, we present the Underground Mine Disaster (UMD) dataset--the first image-caption corpus of real underground disaster scenes--enabling rigorous training and evaluation. Extensive experiments on UMD and related benchmarks show that MDSE substantially outperforms state-of-the-art captioning models, producing more accurate and contextually relevant descriptions that capture crucial details in obscured environments, improving situational awareness for underground emergency response. The code is at this https URL.

10 Dec 2025
We present Ethics Readiness Levels (ERLs), a four-level, iterative method to track how ethical reflection is implemented in the design of AI systems. ERLs bridge high-level ethical principles and everyday engineering by turning ethical values into concrete prompts, checks, and controls within real use cases. The evaluation is conducted using a dynamic, tree-like questionnaire built from context-specific indicators, ensuring relevance to the technology and application domain. Beyond being a managerial tool, ERLs help facilitate a structured dialogue between ethics experts and technical teams, while our scoring system helps track progress over time. We demonstrate the methodology through two case studies: an AI facial sketch generator for law enforcement and a collaborative industrial robot. The ERL tool effectively catalyzes concrete design changes and promotes a shift from narrow technological solutionism to a more reflective, ethics-by-design mindset.

09 Dec 2025
Industrial mushroom cultivation increasingly relies on computer vision for monitoring and automated harvesting. However, developing accurate detection and segmentation models requires large, precisely annotated datasets that are costly to produce. Synthetic data provides a scalable alternative, yet often lacks sufficient realism to generalize to real-world scenarios. This paper presents a novel workflow that integrates 3D rendering in Blender with a constrained diffusion model to automatically generate high-quality annotated, photorealistic synthetic images of Agaricus Bisporus mushrooms. This approach preserves full control over 3D scene configuration and annotations while achieving photorealism without the need for specialized computer graphics expertise. We release two synthetic datasets (each containing 6,000 images depicting over 250k mushroom instances) and evaluate Mask R-CNN models trained on them in a zero-shot setting. When tested on two independent real-world datasets (including a newly collected benchmark), our method achieves state-of-the-art segmentation performance (F1 = 0.859 on M18K), despite using only synthetic training data. Although the approach is demonstrated on Agaricus Bisporus mushrooms, the proposed pipeline can be readily adapted to other mushroom species or to other agricultural domains, such as fruit and leaf detection.

07 Dec 2025
Estimating the Remaining Useful Life (RUL) of mechanical systems is pivotal in Prognostics and Health Management (PHM). Rolling-element bearings are among the most frequent causes of machinery failure, highlighting the need for robust RUL estimation methods. Existing approaches often suffer from poor generalization, lack of robustness, high data demands, and limited interpretability. This paper proposes a novel multimodal-RUL framework that jointly leverages image representations (ImR) and time-frequency representations (TFR) of multichannel, nonstationary vibration signals. The architecture comprises three branches: (1) an ImR branch and (2) a TFR branch, both employing multiple dilated convolutional blocks with residual connections to extract spatial degradation features; and (3) a fusion branch that concatenates these features and feeds them into an LSTM to model temporal degradation patterns. A multi-head attention mechanism subsequently emphasizes salient features, followed by linear layers for final RUL regression. To enable effective multimodal learning, vibration signals are converted into ImR via the Bresenham line algorithm and into TFR using Continuous Wavelet Transform. We also introduce multimodal Layer-wise Relevance Propagation (multimodal-LRP), a tailored explainability technique that significantly enhances model transparency. The approach is validated on the XJTU-SY and PRONOSTIA benchmark datasets. Results show that our method matches or surpasses state-of-the-art baselines under both seen and unseen operating conditions, while requiring ~28 % less training data on XJTU-SY and ~48 % less on PRONOSTIA. The model exhibits strong noise resilience, and multimodal-LRP visualizations confirm the interpretability and trustworthiness of predictions, making the framework highly suitable for real-world industrial deployment.

04 Dec 2025
The integration of artificial intelligence into experimental fluid mechanics promises to accelerate discovery, yet most AI applications remain narrowly focused on numerical studies. This work proposes an AI Fluid Scientist framework that autonomously executes the complete experimental workflow: hypothesis generation, experimental design, robotic execution, data analysis, and manuscript preparation. We validate this through investigation of vortex-induced vibration (VIV) and wake-induced vibration (WIV) in tandem cylinders. Our work has four key contributions: (1) A computer-controlled circulating water tunnel (CWT) with programmatic control of flow velocity, cylinder position, and forcing parameters (vibration frequency and amplitude) with data acquisition (displacement, force, and torque). (2) Automated experiments reproduce literature benchmarks (Khalak and Williamson [1999] and Assi et al. [2013, 2010]) with frequency lock-in within 4% and matching critical spacing trends. (3) The framework with Human-in-the-Loop (HIL) discovers more WIV amplitude response phenomena, and uses a neural network to fit physical laws from data, which is 31% higher than that of polynomial fitting. (4) The framework with multi-agent with virtual-real interaction system executes hundreds of experiments end-to-end, which automatically completes the entire process of scientific research from hypothesis generation, experimental design, experimental execution, data analysis, and manuscript preparation. It greatly liberates human researchers and improves study efficiency, providing new paradigm for the development and research of experimental fluid mechanics.

04 Dec 2025
Researchers from IIT Guwahati and NXP USA, Inc. developed an agentic AI framework that enables small language models (SLMs) to achieve performance comparable to or exceeding large language models (LLMs) in hardware design tasks. This framework improved SLM pass@1 scores by 30-140% in code generation and allowed SLMs to outperform LLMs in specific code improvement and comprehension scenarios, significantly reducing computational cost and energy.

06 Dec 2025
Predictive atomistic simulations have propelled materials discovery, yet routine setup and debugging still demand computer specialists. This know-how gap limits Integrated Computational Materials Engineering (ICME), where state-of-the-art codes exist but remain cumbersome for non-experts. We address this bottleneck with GENIUS, an AI-agentic workflow that fuses a smart Quantum ESPRESSO knowledge graph with a tiered hierarchy of large language models supervised by a finite-state error-recovery machine. Here we show that GENIUS translates free-form human-generated prompts into validated input files that run to completion on 80% of 295 diverse benchmarks, where 76% are autonomously repaired, with success decaying exponentially to a 7% baseline. Compared with LLM-only baselines, GENIUS halves inference costs and virtually eliminates hallucinations. The framework democratizes electronic-structure DFT simulations by intelligently automating protocol generation, validation, and repair, opening large-scale screening and accelerating ICME design loops across academia and industry worldwide.

06 Dec 2025
This paper presents \textsc{Luca}, a \underline{l}arge language model (LLM)-\underline{u}pgraded graph reinforcement learning framework for \underline{c}arbon-\underline{a}ware flexible job shop scheduling. \textsc{Luca} addresses the challenges of dynamic and sustainable scheduling in smart manufacturing systems by integrating a graph neural network and an LLM, guided by a carefully designed in-house prompting strategy, to produce a fused embedding that captures both structural characteristics and contextual semantics of the latest scheduling state. This expressive embedding is then processed by a deep reinforcement learning policy network, which generates real-time scheduling decisions optimized for both makespan and carbon emission objectives. To support sustainability goals, \textsc{Luca} incorporates a dual-objective reward function that encourages both energy efficiency and scheduling timeliness. Experimental results on both synthetic and public datasets demonstrate that \textsc{Luca} consistently outperforms comparison algorithms. For instance, on the synthetic dataset, it achieves an average of 4.1\% and up to 12.2\% lower makespan compared to the best-performing comparison algorithm while maintaining the same emission level. On public datasets, additional gains are observed for both makespan and emission. These results demonstrate that \textsc{Luca} is effective and practical for carbon-aware scheduling in smart manufacturing.

04 Dec 2025
Object detection constitutes the primary task within the domain of computer vision. It is utilized in numerous domains. Nonetheless, object detection continues to encounter the issue of catastrophic forgetting. The model must be retrained whenever new products are introduced, utilizing not only the new products dataset but also the entirety of the previous dataset. The outcome is obvious: increasing model training expenses and significant time consumption. In numerous sectors, particularly retail checkout, the frequent introduction of new products presents a great challenge. This study introduces You Only Train Once (YOTO), a methodology designed to address the issue of catastrophic forgetting by integrating YOLO11n for object localization with DeIT and Proxy Anchor Loss for feature extraction and metric learning. For classification, we utilize cosine similarity between the embedding features of the target product and those in the Qdrant vector database. In a case study conducted in a retail store with 140 products, the experimental results demonstrate that our proposed framework achieves encouraging accuracy, whether for detecting new or existing products. Furthermore, without retraining, the training duration difference is significant. We achieve almost 3 times the training time efficiency compared to classical object detection approaches. This efficiency escalates as additional new products are added to the product database. The average inference time is 580 ms per image containing multiple products, on an edge device, validating the proposed framework's feasibility for practical use.

02 Dec 2025
Multi-robot task allocation in construction automation has traditionally relied on optimization methods such as Dynamic Programming and Reinforcement Learning. This research introduces the LangGraph-based Task Allocation Agent (LTAA), an LLM-driven framework that integrates phase-adaptive allocation strategies, multi-stage validation with hierarchical retries, and dynamic prompting for efficient robot coordination. Although recent LLM approaches show potential for construction robotics, they largely lack rigorous validation and benchmarking against established algorithms. This paper presents the first systematic comparison of LLM-based task allocation with traditional methods in construction this http URL study validates LLM feasibility through SMART-LLM replication and addresses implementation challenges using a Self-Corrective Agent Architecture. LTAA leverages natural-language reasoning combined with structured validation mechanisms, achieving major computational gains reducing token usage by 94.6% and allocation time by 86% through dynamic prompting. The framework adjusts its strategy across phases: emphasizing execution feasibility early and workload balance in later this http URL authors evaluate LTAA against Dynamic Programming, Q-learning, and Deep Q-Network (DQN) baselines using construction operations from the TEACh human-robot collaboration dataset. In the Heavy Excels setting, where robots have strong task specializations, LTAA achieves 77% task completion with superior workload balance, outperforming all traditional methods. These findings show that LLM-based reasoning with structured validation can match established optimization algorithms while offering additional advantages such as interpretability, adaptability, and the ability to update task logic without retraining.
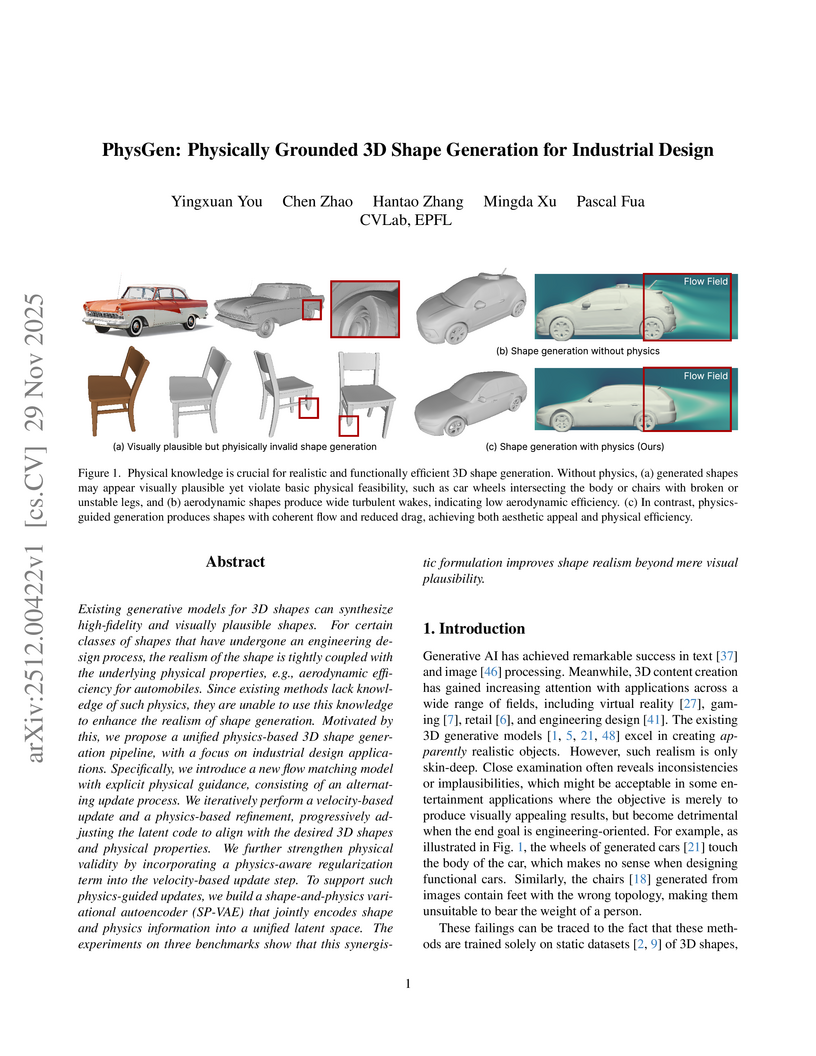
29 Nov 2025

Existing generative models for 3D shapes can synthesize high-fidelity and visually plausible shapes. For certain classes of shapes that have undergone an engineering design process, the realism of the shape is tightly coupled with the underlying physical properties, e.g., aerodynamic efficiency for automobiles. Since existing methods lack knowledge of such physics, they are unable to use this knowledge to enhance the realism of shape generation. Motivated by this, we propose a unified physics-based 3D shape generation pipeline, with a focus on industrial design applications. Specifically, we introduce a new flow matching model with explicit physical guidance, consisting of an alternating update process. We iteratively perform a velocity-based update and a physics-based refinement, progressively adjusting the latent code to align with the desired 3D shapes and physical properties. We further strengthen physical validity by incorporating a physics-aware regularization term into the velocity-based update step. To support such physics-guided updates, we build a shape-and-physics variational autoencoder (SP-VAE) that jointly encodes shape and physics information into a unified latent space. The experiments on three benchmarks show that this synergistic formulation improves shape realism beyond mere visual plausibility.

03 Dec 2025
A new benchmark evaluates Large Language Model (LLM) agents in planning and real-time execution within a dynamic Blocksworld simulation, integrating them via the Model Context Protocol (MCP). It demonstrates that an LLM agent achieved 80% success on basic tasks and 100% in identifying impossible scenarios, but its performance dropped to 60% with partial observability and increased significantly in execution time and token consumption for more complex challenges.

02 Dec 2025
Accurate prediction of the Remaining Useful Life (RUL) in machinery can significantly diminish maintenance costs, enhance equipment up-time, and mitigate adverse outcomes. Data-driven RUL prediction techniques have demonstrated commendable performance. However, their efficacy often relies on the assumption that training and testing data are drawn from the same distribution or domain, which does not hold in real industrial settings. To mitigate this domain discrepancy issue, prior adversarial domain adaptation methods focused on deriving domain-invariant features. Nevertheless, they overlook target-specific information and inconsistency characteristics pertinent to the degradation stages, resulting in suboptimal performance. To tackle these issues, we propose a novel domain adaptation approach for cross-domain RUL prediction named TACDA. Specifically, we propose a target domain reconstruction strategy within the adversarial adaptation process, thereby retaining target-specific information while learning domain-invariant features. Furthermore, we develop a novel clustering and pairing strategy for consistent alignment between similar degradation stages. Through extensive experiments, our results demonstrate the remarkable performance of our proposed TACDA method, surpassing state-of-the-art approaches with regard to two different evaluation metrics. Our code is available at this https URL.

26 Nov 2025
Researchers developed VacuumVLA, a low-cost, integrated suction and gripping end-effector that significantly expands the real-world manipulation capabilities of Vision-Language-Action (VLA) models. This hybrid tool enables robots to successfully perform tasks like opening sealed containers (80% success) and handleless drawers (60% success) that are infeasible for conventional two-finger grippers.
There are no more papers matching your filters at the moment.
