 EPFL
EPFL
21 Oct 2025
Researchers rigorously prove that decoder-only Transformer language models are almost-surely injective, meaning distinct input sequences map to distinct continuous hidden representations, a property maintained throughout training. The work also introduces SIPIT, an algorithm that provably and efficiently reconstructs exact input text from these hidden activations with linear time guarantees.

22 Oct 2025



This research introduces Loopholing, a mechanism that deterministically propagates rich continuous latent information across denoising steps in discrete diffusion models, directly addressing the "sampling wall" problem. Loopholing Discrete Diffusion Models (LDDMs) demonstrate enhanced language generation quality and improved performance on reasoning tasks, often surpassing autoregressive baselines in generative perplexity and consistency.

01 Sep 2025
A large-scale, controlled benchmarking study systematically evaluated modern optimization techniques for pretraining large language models (LLMs) across various scales and training durations. The research identifies top-performing alternatives to AdamW and reveals critical, often overlooked, hyperparameter tuning practices that significantly impact LLM performance and stability.

17 Sep 2025

The Swiss AI Initiative, collaborating with EPFL and ETH Zurich, developed Apertus V1, a suite of fully open, compliant, and multilingual large language models. Apertus leverages a rigorously curated dataset and a novel Goldfish objective to mitigate memorization, achieving strong performance on multilingual benchmarks and demonstrating effective suppression of verbatim recall.

10 Oct 2025
Researchers at VITA@EPFL developed Stable Video Infinity (SVI), a framework that enables the generation of videos with theoretically infinite length by training models to correct their own self-generated errors. This approach maintains high temporal consistency and visual quality over durations up to 250 seconds with minimal degradation, outperforming existing methods and supporting multimodal control.

29 Oct 2024

QuaRot introduces a method for end-to-end 4-bit quantization of Large Language Models, including weights, activations, and the KV cache, by implicitly removing outliers from activations through orthogonal transformations of the model's weights. This approach enabled LLAMA2-70B to achieve a perplexity of 3.79 with a 3.33x prefill speedup and 3.89x memory savings compared to the FP16 baseline.

31 Aug 2020

This paper introduces linear transformers, which reduce the computational and memory complexity of the Transformer architecture from quadratic to linear by reformulating self-attention using kernel methods and matrix associativity. This approach enables thousands of times faster autoregressive inference and efficient processing of very long sequences while maintaining competitive performance across tasks like image generation and speech recognition.

18 Apr 2025


This paper introduces AGENTHARM, a novel benchmark to measure the susceptibility of Large Language Model (LLM) agents to executing multi-step harmful tasks using external tools. Initial evaluations on frontier LLMs demonstrate a surprising degree of compliance with malicious requests, often without jailbreaking, and confirm that simple jailbreak methods can effectively enable coherent, harmful agent actions while retaining their functional capabilities.

31 May 2025
Chain-of-Frames (CoF) is a method that trains video Large Language Models to produce reasoning traces explicitly referencing specific video frames. This approach enhances interpretability and achieves state-of-the-art performance on multiple video understanding benchmarks, including VSI-BENCH, VIDEO-MME, and MVBENCH.

06 Jun 2025

A new family of stochastic deep learning optimizers, uSCG and SCION, developed by EPFL's LIONS group, leverages Linear Minimization Oracles over norm-balls to achieve superior training efficiency and enable zero-shot hyperparameter transferability for large models like NanoGPT, while also unifying several existing optimizers.

17 Apr 2025
We show that even the most recent safety-aligned LLMs are not robust to
simple adaptive jailbreaking attacks. First, we demonstrate how to successfully
leverage access to logprobs for jailbreaking: we initially design an
adversarial prompt template (sometimes adapted to the target LLM), and then we
apply random search on a suffix to maximize a target logprob (e.g., of the
token "Sure"), potentially with multiple restarts. In this way, we achieve 100%
attack success rate -- according to GPT-4 as a judge -- on Vicuna-13B,
Mistral-7B, Phi-3-Mini, Nemotron-4-340B, Llama-2-Chat-7B/13B/70B,
Llama-3-Instruct-8B, Gemma-7B, GPT-3.5, GPT-4o, and R2D2 from HarmBench that
was adversarially trained against the GCG attack. We also show how to jailbreak
all Claude models -- that do not expose logprobs -- via either a transfer or
prefilling attack with a 100% success rate. In addition, we show how to use
random search on a restricted set of tokens for finding trojan strings in
poisoned models -- a task that shares many similarities with jailbreaking --
which is the algorithm that brought us the first place in the SaTML'24 Trojan
Detection Competition. The common theme behind these attacks is that adaptivity
is crucial: different models are vulnerable to different prompting templates
(e.g., R2D2 is very sensitive to in-context learning prompts), some models have
unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and
in some settings, it is crucial to restrict the token search space based on
prior knowledge (e.g., for trojan detection). For reproducibility purposes, we
provide the code, logs, and jailbreak artifacts in the JailbreakBench format at
this https URL

19 Aug 2025
The growth of large language models underscores the need for parameter-efficient fine-tuning. Despite its popularity, LoRA encounters storage and computational challenges when deploying multiple task- or user-specific modules. To address this, we introduce LoRA-XS, a novel fine-tuning method backed by a theoretical derivation. LoRA-XS drastically reduces trainable parameters by incorporating a small, trainable weight matrix between frozen low-rank matrices derived from the Singular Value Decomposition of pre-trained weights. This design enables LoRA-XS to reduce storage requirements by over 100x in 7B models compared to LoRA. Additionally, unlike other methods, LoRA-XS imposes no lower bound on trainable parameters - it can scale from a single parameter per module to arbitrarily large values, adapting to any storage or computational constraint. Evaluations on GLUE, GSM8K, MATH, and commonsense reasoning benchmarks across different model scales reveal that LoRA-XS consistently outperforms or matches LoRA and VeRA in accuracy, offering unmatched parameter efficiency. Our ablation studies highlight the significance of singular vectors in transformer weights, establishing LoRA-XS as a powerful, storage-efficient solution for scaling and personalizing large language models.

24 Nov 2025



Recovering meaningful concepts from language model activations is a central aim of interpretability. While existing feature extraction methods aim to identify concepts that are independent directions, it is unclear if this assumption can capture the rich temporal structure of language. Specifically, via a Bayesian lens, we demonstrate that Sparse Autoencoders (SAEs) impose priors that assume independence of concepts across time, implying stationarity. Meanwhile, language model representations exhibit rich temporal dynamics, including systematic growth in conceptual dimensionality, context-dependent correlations, and pronounced non-stationarity, in direct conflict with the priors of SAEs. Taking inspiration from computational neuroscience, we introduce a new interpretability objective -- Temporal Feature Analysis -- which possesses a temporal inductive bias to decompose representations at a given time into two parts: a predictable component, which can be inferred from the context, and a residual component, which captures novel information unexplained by the context. Temporal Feature Analyzers correctly parse garden path sentences, identify event boundaries, and more broadly delineate abstract, slow-moving information from novel, fast-moving information, while existing SAEs show significant pitfalls in all the above tasks. Overall, our results underscore the need for inductive biases that match the data in designing robust interpretability tools.

29 Oct 2025
Researchers from EPFL and Carnegie Mellon University developed OS-HARM, a benchmark for evaluating the safety of LLM-based computer use agents interacting with realistic operating system environments. The benchmark revealed that frontier agents are highly vulnerable to deliberate misuse (48-70% unsafe execution) and moderately susceptible to prompt injection attacks (2-20% unsafe execution).

05 Oct 2025
The RAP framework, developed by researchers at EPFL and Valeo.ai, introduces a lightweight 3D rasterization pipeline combined with a Raster-to-Real (R2R) feature-space alignment module to enable scalable data augmentation for end-to-end autonomous driving planners. This approach achieves state-of-the-art performance, with RAP-DINO scoring 93.8 PDMS on NAVSIM v1 and 36.9 EPDMS on NAVSIM v2, by generating diverse, semantically rich training data without requiring photorealism.

18 Nov 2025
A systematic analysis of multi-stage large language model training dynamics investigates how design choices across pre-training, continued pre-training, supervised fine-tuning, and reinforcement learning impact model capabilities, providing a transparent framework and introducing outcome reward model scores as a reliable proxy for generative task evaluation.

26 Jun 2025

Hugging Face and EPFL developed FineWeb2, an automatically adaptive pipeline for curating high-quality multilingual pre-training data. This pipeline generated a 20-terabyte dataset spanning 1,868 language-script pairs, yielding models that consistently outperformed prior general-purpose multilingual datasets on 11 out of 14 tested languages.
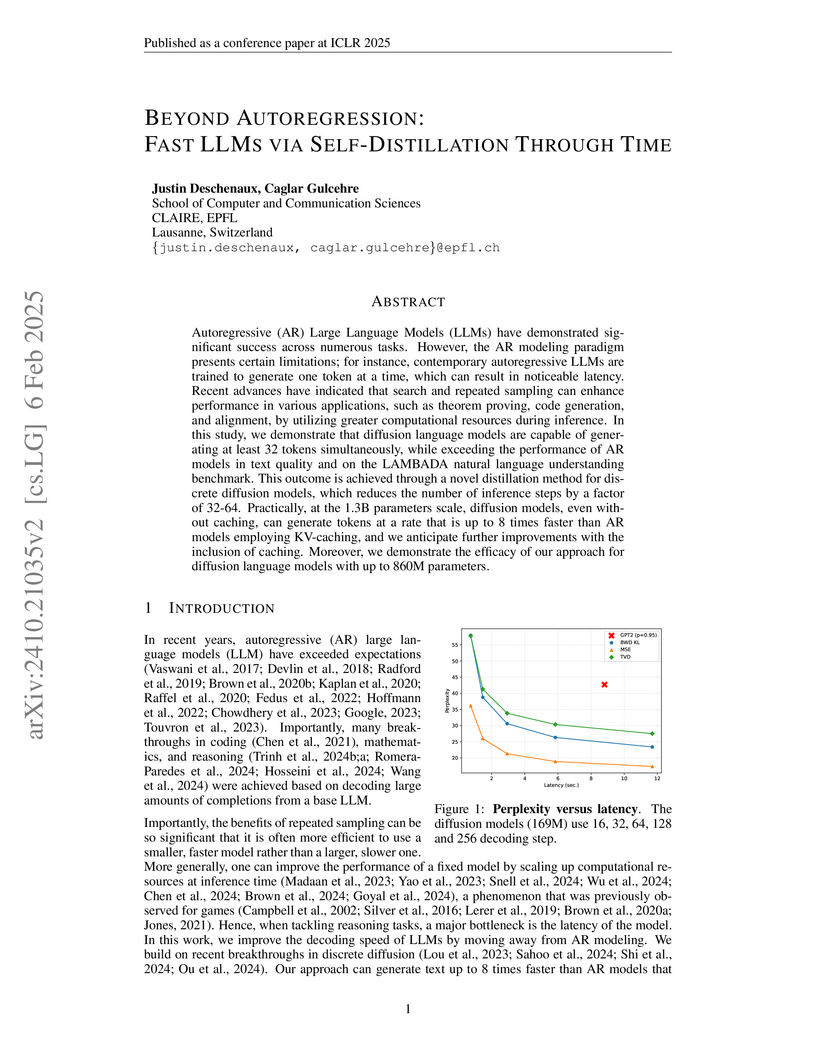
06 Feb 2025
Researchers at EPFL developed Self-Distillation Through Time (SDTT), a method that significantly accelerates discrete diffusion language models by reducing their inference steps by factors of 32-64. The approach enables these models to generate text up to 8 times faster than autoregressive models like GPT-2 while maintaining or improving text generation quality and language understanding capabilities.

20 Oct 2025

Researchers at Anthropic and affiliated institutions developed a multi-dimensional framework to measure the "belief depth" of facts implanted in large language models. They found that Synthetic Document Finetuning (SDF) successfully implants facts that generalize, resist scrutiny, and are internally represented similarly to genuine knowledge, particularly for plausible information.

12 Nov 2025

The concept of causal abstraction got recently popularised to demystify the opaque decision-making processes of machine learning models; in short, a neural network can be abstracted as a higher-level algorithm if there exists a function which allows us to map between them. Notably, most interpretability papers implement these maps as linear functions, motivated by the linear representation hypothesis: the idea that features are encoded linearly in a model's representations. However, this linearity constraint is not required by the definition of causal abstraction. In this work, we critically examine the concept of causal abstraction by considering arbitrarily powerful alignment maps. In particular, we prove that under reasonable assumptions, any neural network can be mapped to any algorithm, rendering this unrestricted notion of causal abstraction trivial and uninformative. We complement these theoretical findings with empirical evidence, demonstrating that it is possible to perfectly map models to algorithms even when these models are incapable of solving the actual task; e.g., on an experiment using randomly initialised language models, our alignment maps reach 100\% interchange-intervention accuracy on the indirect object identification task. This raises the non-linear representation dilemma: if we lift the linearity constraint imposed to alignment maps in causal abstraction analyses, we are left with no principled way to balance the inherent trade-off between these maps' complexity and accuracy. Together, these results suggest an answer to our title's question: causal abstraction is not enough for mechanistic interpretability, as it becomes vacuous without assumptions about how models encode information. Studying the connection between this information-encoding assumption and causal abstraction should lead to exciting future work.
There are no more papers matching your filters at the moment.
