09 Dec 2025

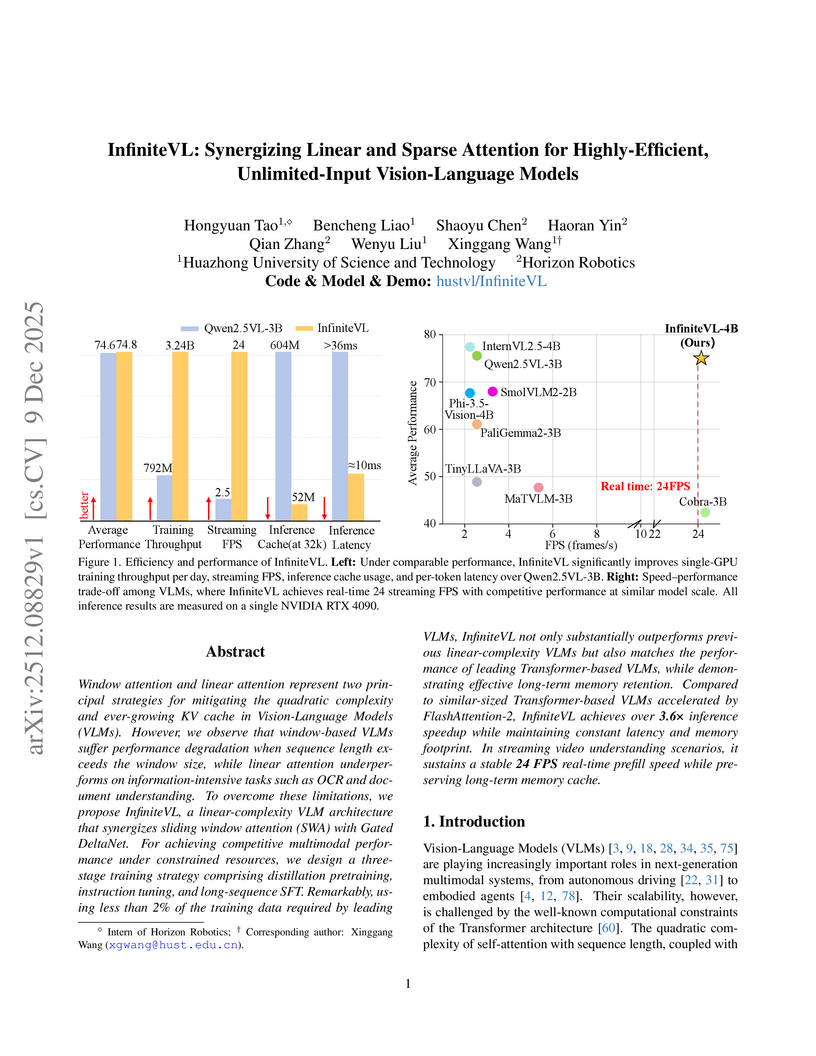
InfiniteVL, a collaboration between Huazhong University of Science and Technology and Horizon Robotics, introduces a hybrid Vision-Language Model that synergizes linear and sparse attention to enable unlimited multimodal input processing with constant latency and memory footprint. The model achieves performance competitive with Transformer-based VLMs on diverse benchmarks, including information-intensive tasks, while demonstrating significant inference speedups and robust real-time streaming capabilities.

08 Dec 2025
Researchers at OpenAI developed a method to train large language models (LLMs) to self-report their non-compliance or shortcomings through a structured "confession" output. This approach uses a disentangled reward system to incentivize honesty, demonstrating that models confess to undesired behaviors in 74.3% of cases and are more likely to be truthful in confessions than in their primary answers, with minimal impact on main task performance.

08 Dec 2025

Image fusion aims to blend complementary information from multiple sensing modalities, yet existing approaches remain limited in robustness, adaptability, and controllability. Most current fusion networks are tailored to specific tasks and lack the ability to flexibly incorporate user intent, especially in complex scenarios involving low-light degradation, color shifts, or exposure imbalance. Moreover, the absence of ground-truth fused images and the small scale of existing datasets make it difficult to train an end-to-end model that simultaneously understands high-level semantics and performs fine-grained multimodal alignment. We therefore present DiTFuse, instruction-driven Diffusion-Transformer (DiT) framework that performs end-to-end, semantics-aware fusion within a single model. By jointly encoding two images and natural-language instructions in a shared latent space, DiTFuse enables hierarchical and fine-grained control over fusion dynamics, overcoming the limitations of pre-fusion and post-fusion pipelines that struggle to inject high-level semantics. The training phase employs a multi-degradation masked-image modeling strategy, so the network jointly learns cross-modal alignment, modality-invariant restoration, and task-aware feature selection without relying on ground truth images. A curated, multi-granularity instruction dataset further equips the model with interactive fusion capabilities. DiTFuse unifies infrared-visible, multi-focus, and multi-exposure fusion-as well as text-controlled refinement and downstream tasks-within a single architecture. Experiments on public IVIF, MFF, and MEF benchmarks confirm superior quantitative and qualitative performance, sharper textures, and better semantic retention. The model also supports multi-level user control and zero-shot generalization to other multi-image fusion scenarios, including instruction-conditioned segmentation.

10 Dec 2025
The proliferation of hate speech on Chinese social media poses urgent societal risks, yet traditional systems struggle to decode context-dependent rhetorical strategies and evolving slang. To bridge this gap, we propose a novel three-stage LLM-based framework: Prompt Engineering, Supervised Fine-tuning, and LLM Merging. First, context-aware prompts are designed to guide LLMs in extracting implicit hate patterns. Next, task-specific features are integrated during supervised fine-tuning to enhance domain adaptation. Finally, merging fine-tuned LLMs improves robustness against out-of-distribution cases. Evaluations on the STATE-ToxiCN benchmark validate the framework's effectiveness, demonstrating superior performance over baseline methods in detecting fine-grained hate speech.
08 Dec 2025
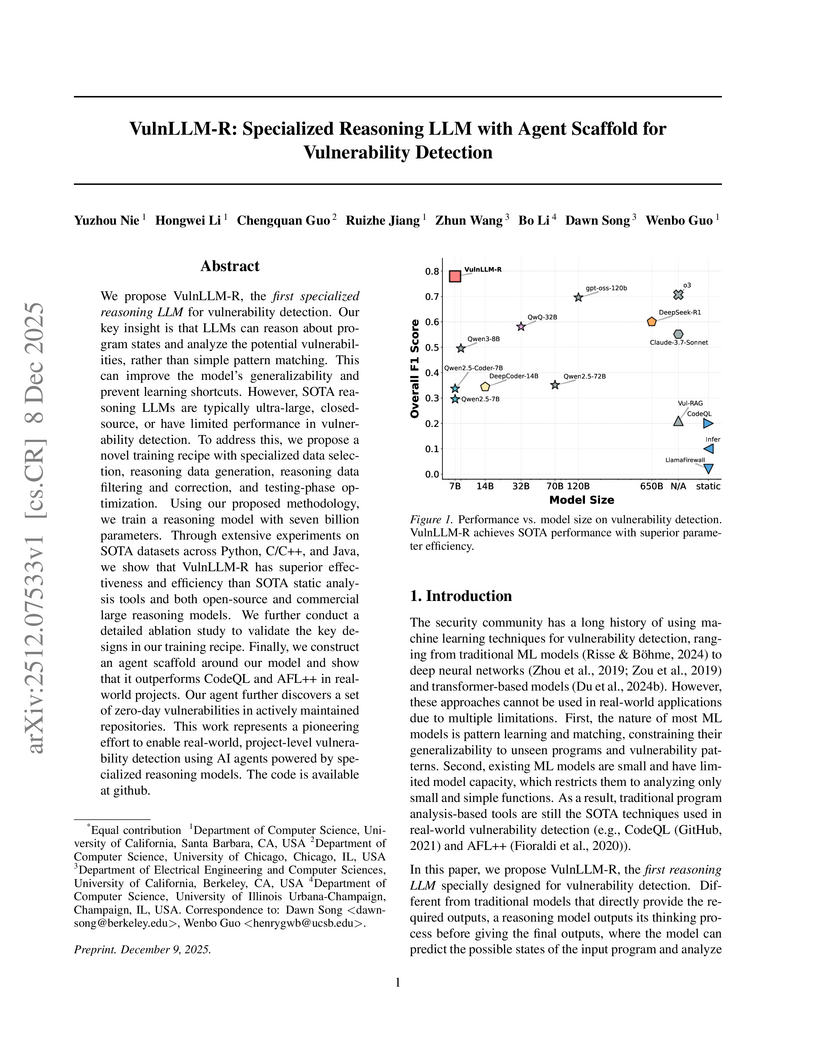
Researchers from the University of California, Santa Barbara, University of Chicago, University of California, Berkeley, and University of Illinois Urbana-Champaign developed VulnLLM-R, a 7-billion parameter specialized reasoning large language model for vulnerability detection. This open-source model surpasses the performance of larger general-purpose LLMs and traditional tools, achieving project-level analysis and discovering 15 zero-day vulnerabilities in real-world software.

10 Dec 2025
Culture is a core component of human-to-human interaction and plays a vital role in how we perceive and interact with others. Advancements in the effectiveness of Large Language Models (LLMs) in generating human-sounding text have greatly increased the amount of human-to-computer interaction. As this field grows, the cultural alignment of these human-like agents becomes an important field of study. Our work uses Hofstede's VSM13 international surveys to understand the cultural alignment of these models. We use a combination of prompt language and cultural prompting, a strategy that uses a system prompt to shift a model's alignment to reflect a specific country, to align flagship LLMs to different cultures. Our results show that DeepSeek-V3, V3.1, and OpenAI's GPT-5 exhibit a close alignment with the survey responses of the United States and do not achieve a strong or soft alignment with China, even when using cultural prompts or changing the prompt language. We also find that GPT-4 exhibits an alignment closer to China when prompted in English, but cultural prompting is effective in shifting this alignment closer to the United States. Other low-cost models, GPT-4o and GPT-4.1, respond to the prompt language used (i.e., English or Simplified Chinese) and cultural prompting strategies to create acceptable alignments with both the United States and China.

02 Dec 2025
Researchers from FAIR at Meta and the University of Washington developed an iterative self-training framework for Vision-Language Model (VLM) judges that operates entirely without human preference annotations. This approach allowed an 11-billion parameter VLM judge to achieve a 40.5% relative performance gain on VL-RewardBench and a 7.5% gain on Multimodal RewardBench, in some cases outperforming larger proprietary models like GPT-4o in specific evaluation dimensions.

06 Dec 2025

Researchers at institutions including South China University of Technology and City University of Hong Kong developed SCD-MLLM, a unified framework leveraging a Multimodal Large Language Model for automatic depression detection. The system maintains stable and accurate performance across diverse real-world scenarios and effectively handles situations with partially missing input modalities.

06 Dec 2025
The Nanbeige4-3B model family from the Nanbeige LLM Lab at Boss Zhipin introduces a 3-billion-parameter language model that consistently outperforms much larger open-source models, setting new state-of-the-art averages in mathematical and scientific reasoning. This performance is achieved through a multi-stage training pipeline incorporating advanced data filtering, a fine-grained learning rate scheduler, dual-level preference distillation, and multi-stage reinforcement learning.

08 Dec 2025
Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.

05 Dec 2025


This work identifies that current Video Large Multimodal Models (VLMMs) often rely on common-sense prior knowledge rather than genuine temporal event ordering, introducing a "prior-knowledge shortcut." It develops VECTOR, a diagnostic benchmark with synthetic multi-event videos, and MECOT, a multi-event instruction fine-tuning and Chain-of-Thought method, which significantly improves VLMMs' temporal reasoning and general video understanding performance.
05 Dec 2025

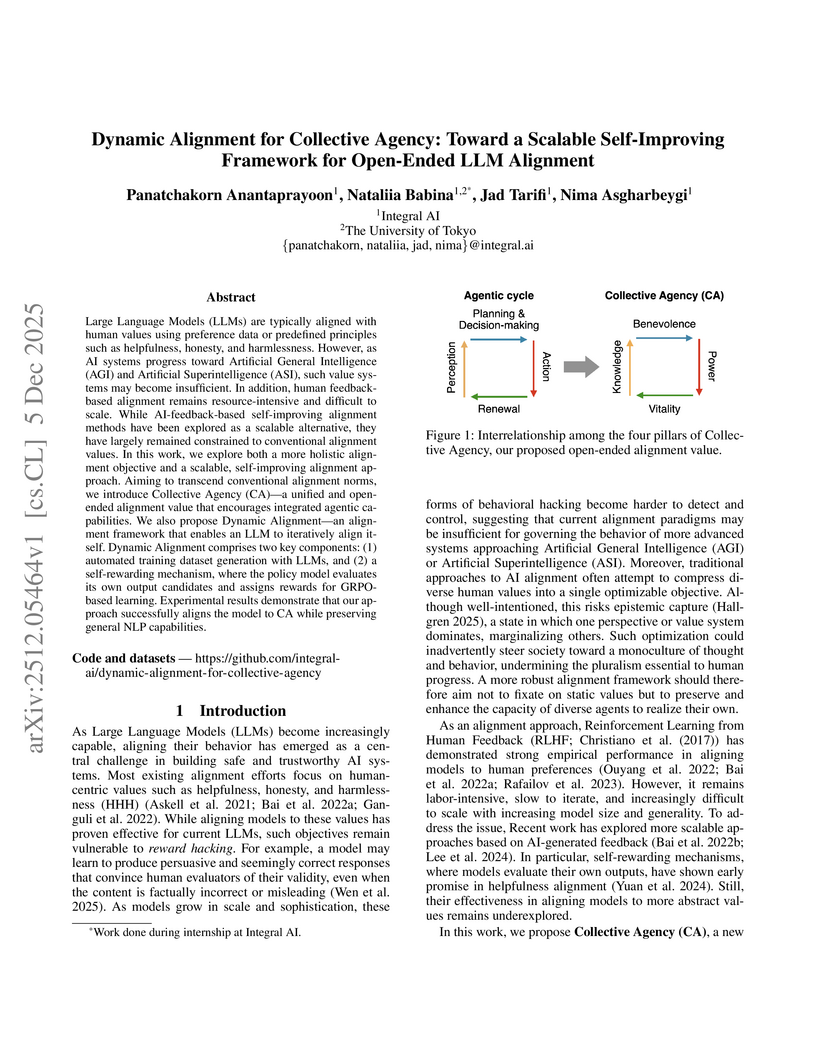
Integral AI developed Collective Agency, a holistic alignment value, and a self-improving Dynamic Alignment framework for Large Language Models. This approach significantly improves an LLM's adherence to Collective Agency without degrading its general language processing abilities, demonstrating a scalable method for aligning future AI systems.

28 Nov 2025
Tencent Hunyuan developed Hunyuan-GameCraft-2, an instruction-following interactive game world model that generates dynamic video content responsive to natural language and traditional game inputs. The model achieved high interaction trigger rates (e.g., 0.983 for Actor Actions) and superior physics correctness on a new InterBench evaluation, operating in real-time at 16 FPS.
05 Dec 2025

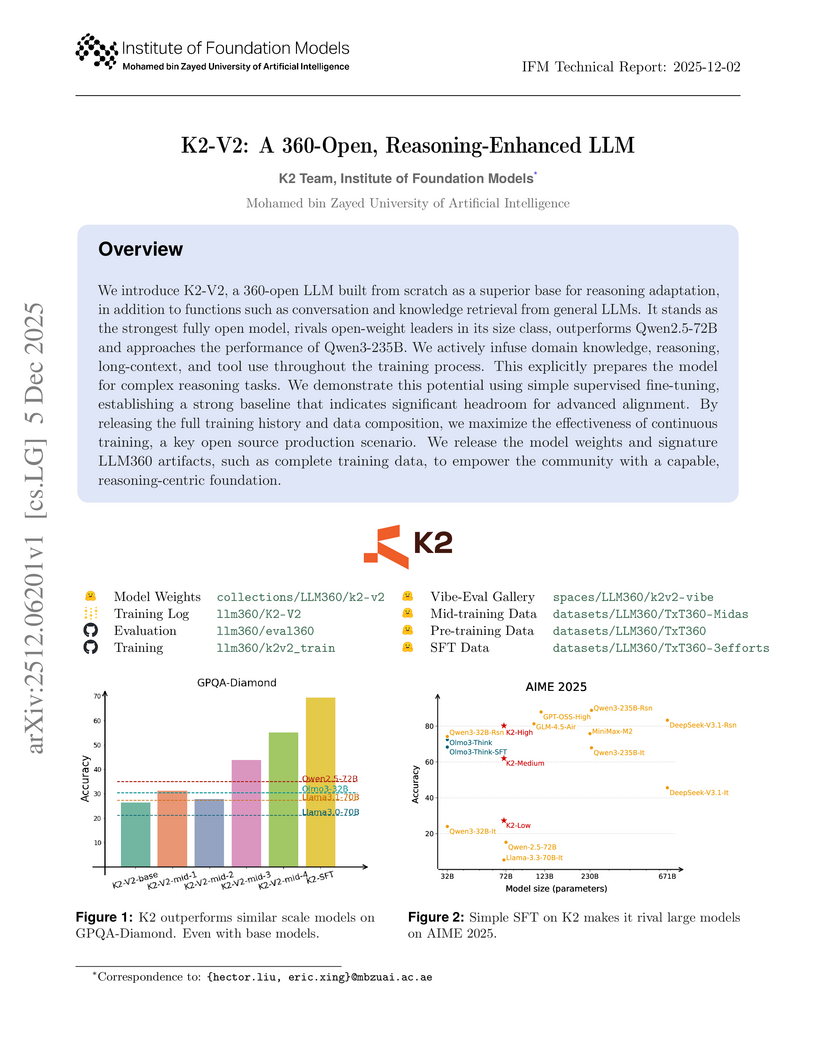
We introduce K2-V2, a 360-open LLM built from scratch as a superior base for reasoning adaptation, in addition to functions such as conversation and knowledge retrieval from general LLMs. It stands as the strongest fully open model, rivals open-weight leaders in its size class, outperforms Qwen2.5-72B and approaches the performance of Qwen3-235B. We actively infuse domain knowledge, reasoning, long-context, and tool use throughout the training process. This explicitly prepares the model for complex reasoning tasks. We demonstrate this potential using simple supervised fine-tuning, establishing a strong baseline that indicates significant headroom for advanced alignment. By releasing the full training history and data composition, we maximize the effectiveness of continuous training, a key open source production scenario. We release the model weights and signature LLM360 artifacts, such as complete training data, to empower the community with a capable, reasoning-centric foundation.

08 Dec 2025
Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.

09 Dec 2025
Large language models (LLMs) hold the potential to absorb and reflect personality traits and attitudes specified by users. In our study, we investigated this potential using robust psychometric measures. We adapted the most studied test in psychological literature, namely Minnesota Multiphasic Personality Inventory (MMPI) and examined LLMs' behavior to identify traits. To asses the sensitivity of LLMs' prompts and psychological biases we created personality-oriented prompts, crafting a detailed set of personas that vary in trait intensity. This enables us to measure how well LLMs follow these roles. Our study introduces MindShift, a benchmark for evaluating LLMs' psychological adaptability. The results highlight a consistent improvement in LLMs' role perception, attributed to advancements in training datasets and alignment techniques. Additionally, we observe significant differences in responses to psychometric assessments across different model types and families, suggesting variability in their ability to emulate human-like personality traits. MindShift prompts and code for LLM evaluation will be publicly available.

09 Dec 2025
Vision-language models (VLMs) are emerging as powerful generalist tools for remote sensing, capable of integrating information across diverse tasks and enabling flexible, instruction-based interactions via a chat interface. In this work, we enhance VLM-based visual grounding in satellite imagery by proposing a novel structured localization mechanism. Our approach involves finetuning a pretrained VLM on a diverse set of instruction-following tasks, while interfacing a dedicated grounding module through specialized control tokens for localization. This method facilitates joint reasoning over both language and spatial information, significantly enhancing the model's ability to precisely localize objects in complex satellite scenes. We evaluate our framework on several remote sensing benchmarks, consistently improving the state-of-the-art, including a 24.8% relative improvement over previous methods on visual grounding. Our results highlight the benefits of integrating structured spatial reasoning into VLMs, paving the way for more reliable real-world satellite data analysis.

09 Dec 2025
The significant increase in software production, driven by the acceleration of development cycles over the past two decades, has led to a steady rise in software vulnerabilities, as shown by statistics published yearly by the CVE program. The automation of the source code vulnerability detection (CVD) process has thus become essential, and several methods have been proposed ranging from the well established program analysis techniques to the more recent AI-based methods. Our research investigates Large Language Models (LLMs), which are considered among the most performant AI models to date, for the CVD task. The objective is to study their performance and apply different state-of-the-art techniques to enhance their effectiveness for this task. We explore various fine-tuning and prompt engineering settings. We particularly suggest one novel approach for fine-tuning LLMs which we call Double Fine-tuning, and also test the understudied Test-Time fine-tuning approach. We leverage the recent open-source Llama-3.1 8B, with source code samples extracted from BigVul and PrimeVul datasets. Our conclusions highlight the importance of fine-tuning to resolve the task, the performance of Double tuning, as well as the potential of Llama models for CVD. Though prompting proved ineffective, Retrieval augmented generation (RAG) performed relatively well as an example selection technique. Overall, some of our research questions have been answered, and many are still on hold, which leaves us many future work perspectives. Code repository is available here: this https URL.

10 Dec 2025
Large Language Models (LLMs) are transforming language sciences. However, their widespread deployment currently suffers from methodological fragmentation and a lack of systematic soundness. This study proposes two comprehensive methodological frameworks designed to guide the strategic and responsible application of LLMs in language sciences. The first method-selection framework defines and systematizes three distinct, complementary approaches, each linked to a specific research goal: (1) prompt-based interaction with general-use models for exploratory analysis and hypothesis generation; (2) fine-tuning of open-source models for confirmatory, theory-driven investigation and high-quality data generation; and (3) extraction of contextualized embeddings for further quantitative analysis and probing of model internal mechanisms. We detail the technical implementation and inherent trade-offs of each method, supported by empirical case studies. Based on the method-selection framework, the second systematic framework proposed provides constructed configurations that guide the practical implementation of multi-stage research pipelines based on these approaches. We then conducted a series of empirical experiments to validate our proposed framework, employing retrospective analysis, prospective application, and an expert evaluation survey. By enforcing the strategic alignment of research questions with the appropriate LLM methodology, the frameworks enable a critical paradigm shift in language science research. We believe that this system is fundamental for ensuring reproducibility, facilitating the critical evaluation of LLM mechanisms, and providing the structure necessary to move traditional linguistics from ad-hoc utility to verifiable, robust science.

04 Dec 2025

Alibaba Group researchers developed LORE, a large generative model framework for e-commerce search relevance, which systematically deconstructs the relevance task and employs a two-stage training paradigm. The framework successfully integrates knowledge, multi-modal understanding, and rule adherence, leading to a cumulative +27% improvement in the online GoodRate metric and outperforming state-of-the-art LLMs on a custom e-commerce benchmark.
There are no more papers matching your filters at the moment.
