
09 Dec 2025
This work presents a comprehensive engineering guide for designing and deploying production-grade agentic AI workflows, offering nine best practices demonstrated through a multimodal news-to-media generation case study. The approach improves system determinism, reliability, and responsible AI integration, reducing issues like hallucination and enabling scalable, maintainable deployments.

08 Dec 2025

Researchers from Alibaba Group and Wuhan University developed MUSE, a multimodal search-based framework for lifelong user interest modeling that integrates rich semantic information across both retrieval and fine-grained modeling stages. Deployed in Taobao's display advertising system, MUSE achieved a +12.6% CTR, +5.1% RPM, and +11.4% ROI in online A/B tests.

08 Dec 2025
Lightweight, real-time text-to-speech systems are crucial for accessibility. However, the most efficient TTS models often rely on lightweight phonemizers that struggle with context-dependent challenges. In contrast, more advanced phonemizers with a deeper linguistic understanding typically incur high computational costs, which prevents real-time performance.
This paper examines the trade-off between phonemization quality and inference speed in G2P-aided TTS systems, introducing a practical framework to bridge this gap. We propose lightweight strategies for context-aware phonemization and a service-oriented TTS architecture that executes these modules as independent services. This design decouples heavy context-aware components from the core TTS engine, effectively breaking the latency barrier and enabling real-time use of high-quality phonemization models. Experimental results confirm that the proposed system improves pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it well-suited for offline and end-device TTS applications.

10 Dec 2025
Always-on sensors are increasingly expected to embark a variety of tiny neural networks and to continuously perform inference on time-series of the data they sense. In order to fit lifetime and energy consumption requirements when operating on battery, such hardware uses microcontrollers (MCUs) with tiny memory budget e.g., 128kB of RAM. In this context, optimizing data flows across neural network layers becomes crucial. In this paper, we introduce TinyDéjàVu, a new framework and novel algorithms we designed to drastically reduce the RAM footprint required by inference using various tiny ML models for sensor data time-series on typical microcontroller hardware. We publish the implementation of TinyDéjàVu as open source, and we perform reproducible benchmarks on hardware. We show that TinyDéjàVu can save more than 60% of RAM usage and eliminate up to 90% of redundant compute on overlapping sliding window inputs.
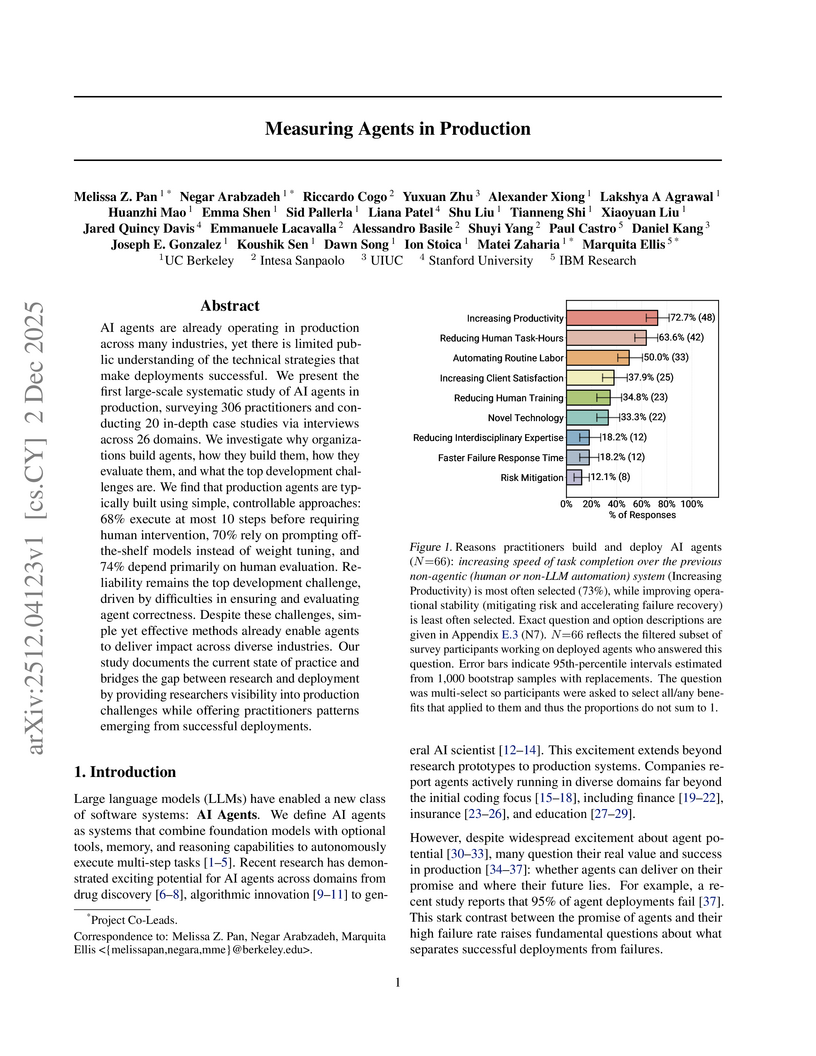
02 Dec 2025
An empirical study surveyed 306 AI agent practitioners and conducted 20 in-depth case studies to analyze the technical strategies, architectural patterns, and challenges of successfully deployed AI agents. The research reveals how real-world production agents prioritize reliability and controlled autonomy to achieve productivity gains across diverse industries.

09 Dec 2025
The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV this http URL validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: this https URL

10 Dec 2025
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads.
We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8 compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5 more requests compared to the GPU-sharing system.

08 Dec 2025
CadLLM introduces a training-free, confidence-aware calibration method to dynamically adjust decoding parameters for diffusion-based Large Language Models (dLLMs). This approach achieves up to a 2.28x throughput gain on HumanEval compared to Fast-dLLM, maintaining competitive accuracy across benchmarks.

08 Dec 2025

Google DeepMind and Google Quantum AI introduce AlphaQubit 2 (AQ2), a neural decoder achieving near-optimal accuracy for topological quantum codes, including the surface code and the challenging color code, at large scales. Its real-time variant, AQ2-RT, processes error syndromes at sub-microsecond speeds on commercial hardware and demonstrates effectiveness on experimental data from the 105-qubit Willow chip.

09 Dec 2025
Post-deployment monitoring of artificial intelligence (AI) systems in health care is essential to ensure their safety, quality, and sustained benefit-and to support governance decisions about which systems to update, modify, or decommission. Motivated by these needs, we developed a framework for monitoring deployed AI systems grounded in the mandate to take specific actions when they fail to behave as intended. This framework, which is now actively used at Stanford Health Care, is organized around three complementary principles: system integrity, performance, and impact. System integrity monitoring focuses on maximizing system uptime, detecting runtime errors, and identifying when changes to the surrounding IT ecosystem have unintended effects. Performance monitoring focuses on maintaining accurate system behavior in the face of changing health care practices (and thus input data) over time. Impact monitoring assesses whether a deployed system continues to have value in the form of benefit to clinicians and patients. Drawing on examples of deployed AI systems at our academic medical center, we provide practical guidance for creating monitoring plans based on these principles that specify which metrics to measure, when those metrics should be reviewed, who is responsible for acting when metrics change, and what concrete follow-up actions should be taken-for both traditional and generative AI. We also discuss challenges to implementing this framework, including the effort and cost of monitoring for health systems with limited resources and the difficulty of incorporating data-driven monitoring practices into complex organizations where conflicting priorities and definitions of success often coexist. This framework offers a practical template and starting point for health systems seeking to ensure that AI deployments remain safe and effective over time.

10 Dec 2025
Context. LLM-based autonomous agents in software engineering rely on large, proprietary models, limiting local deployment. This has spurred interest in Small Language Models (SLMs), but their practical effectiveness and efficiency within complex agentic frameworks for automated issue resolution remain poorly understood.
Goal. We investigate the performance, energy efficiency, and resource consumption of four leading agentic issue resolution frameworks when deliberately constrained to using SLMs. We aim to assess the viability of these systems for this task in resource-limited settings and characterize the resulting trade-offs.
Method. We conduct a controlled evaluation of four leading agentic frameworks (SWE-Agent, OpenHands, Mini SWE Agent, AutoCodeRover) using two SLMs (Gemma-3 4B, Qwen-3 1.7B) on the SWE-bench Verified Mini benchmark. On fixed hardware, we measure energy, duration, token usage, and memory over 150 runs per configuration.
Results. We find that framework architecture is the primary driver of energy consumption. The most energy-intensive framework, AutoCodeRover (Gemma), consumed 9.4x more energy on average than the least energy-intensive, OpenHands (Gemma). However, this energy is largely wasted. Task resolution rates were near-zero, demonstrating that current frameworks, when paired with SLMs, consume significant energy on unproductive reasoning loops. The SLM's limited reasoning was the bottleneck for success, but the framework's design was the bottleneck for efficiency.
Conclusions. Current agentic frameworks, designed for powerful LLMs, fail to operate efficiently with SLMs. We find that framework architecture is the primary driver of energy consumption, but this energy is largely wasted due to the SLMs' limited reasoning. Viable low-energy solutions require shifting from passive orchestration to architectures that actively manage SLM weaknesses.

10 Dec 2025
Low-power microcontroller (MCU) hardware is currently evolving from single-core architectures to predominantly multi-core architectures. In parallel, new embedded software building blocks are more and more written in Rust, while C/C++ dominance fades in this domain. On the other hand, small artificial neural networks (ANN) of various kinds are increasingly deployed in edge AI use cases, thus deployed and executed directly on low-power MCUs. In this context, both incremental improvements and novel innovative services will have to be continuously retrofitted using ANNs execution in software embedded on sensing/actuating systems already deployed in the field. However, there was so far no Rust embedded software platform automating parallelization for inference computation on multi-core MCUs executing arbitrary TinyML models. This paper thus fills this gap by introducing Ariel-ML, a novel toolkit we designed combining a generic TinyML pipeline and an embedded Rust software platform which can take full advantage of multi-core capabilities of various 32bit microcontroller families (Arm Cortex-M, RISC-V, ESP-32). We published the full open source code of its implementation, which we used to benchmark its capabilities using a zoo of various TinyML models. We show that Ariel-ML outperforms prior art in terms of inference latency as expected, and we show that, compared to pre-existing toolkits using embedded C/C++, Ariel-ML achieves comparable memory footprints. Ariel-ML thus provides a useful basis for TinyML practitioners and resource-constrained embedded Rust developers.

09 Dec 2025
The rising global prevalence of diabetes necessitates early detection to prevent severe complications. While AI-powered prediction applications offer a promising solution, they require a responsive and scalable back-end architecture to serve a large user base effectively. This paper details the development and evaluation of a scalable back-end system designed for a mobile diabetes prediction application. The primary objective was to maintain a failure rate below 5% and an average latency of under 1000 ms. The architecture leverages horizontal scaling, database sharding, and asynchronous communication via a message queue. Performance evaluation showed that 83% of the system's features (20 out of 24) met the specified performance targets. Key functionalities such as user profile management, activity tracking, and read-intensive prediction operations successfully achieved the desired performance. The system demonstrated the ability to handle up to 10,000 concurrent users without issues, validating its scalability. The implementation of asynchronous communication using RabbitMQ proved crucial in minimizing the error rate for computationally intensive prediction requests, ensuring system reliability by queuing requests and preventing data loss under heavy load.

10 Dec 2025
Developing generalizable AI for medical imaging requires both access to large, multi-center datasets and standardized, reproducible tooling within research environments. However, leveraging real-world imaging data in clinical research environments is still hampered by strict regulatory constraints, fragmented software infrastructure, and the challenges inherent in conducting large-cohort multicentre studies. This leads to projects that rely on ad-hoc toolchains that are hard to reproduce, difficult to scale beyond single institutions and poorly suited for collaboration between clinicians and data scientists. We present Kaapana, a comprehensive open-source platform for medical imaging research that is designed to bridge this gap. Rather than building single-use, site-specific tooling, Kaapana provides a modular, extensible framework that unifies data ingestion, cohort curation, processing workflows and result inspection under a common user interface. By bringing the algorithm to the data, it enables institutions to keep control over their sensitive data while still participating in distributed experimentation and model development. By integrating flexible workflow orchestration with user-facing applications for researchers, Kaapana reduces technical overhead, improves reproducibility and enables conducting large-scale, collaborative, multi-centre imaging studies. We describe the core concepts of the platform and illustrate how they can support diverse use cases, from local prototyping to nation-wide research networks. The open-source codebase is available at this https URL

02 Dec 2025
PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing
PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing

PaperDebugger, developed by NUS researchers, introduces an in-editor multi-agent system as a Chrome extension for Overleaf, embedding LLM-driven academic writing assistance directly into the LaTeX editing environment. The system offers capabilities like structured critiques, text refinement, and literature lookup via patch-based edits, demonstrating successful technical integration and positive early user adoption.

04 Dec 2025
Alibaba Group researchers developed LORE, a large generative model framework for e-commerce search relevance, which systematically deconstructs the relevance task and employs a two-stage training paradigm. The framework successfully integrates knowledge, multi-modal understanding, and rule adherence, leading to a cumulative +27% improvement in the online GoodRate metric and outperforming state-of-the-art LLMs on a custom e-commerce benchmark.

05 Dec 2025
AI agents powered by large language models are increasingly deployed as cloud services that autonomously access sensitive data, invoke external tools, and interact with other agents. However, these agents run within a complex multi-party ecosystem, where untrusted components can lead to data leakage, tampering, or unintended behavior. Existing Confidential Virtual Machines (CVMs) provide only per binary protection and offer no guarantees for cross-principal trust, accelerator-level isolation, or supervised agent behavior. We present Omega, a system that enables trusted AI agents by enforcing end-to-end isolation, establishing verifiable trust across all contributing principals, and supervising every external interaction with accountable provenance. Omega builds on Confidential VMs and Confidential GPUs to create a Trusted Agent Platform that hosts many agents within a single CVM using nested isolation. It also provides efficient multi-agent orchestration with cross-principal trust establishment via differential attestation, and a policy specification and enforcement framework that governs data access, tool usage, and inter-agent communication for data protection and regulatory compliance. Implemented on AMD SEV-SNP and NVIDIA H100, Omega fully secures agent state across CVM-GPU, and achieves high performance while enabling high-density, policy-compliant multi-agent deployments at cloud scale.

03 Dec 2025
KVNAND is the first architecture to enable entirely DRAM-free, on-device Large Language Model (LLM) inference by integrating both model weights and the dynamic Key-Value (KV) cache within compute-enabled 3D NAND flash. This approach resolves out-of-memory issues for long contexts up to 100K tokens, achieving geomean speedups up to 2.05x and reducing memory costs by 69% compared to DRAM-based solutions.

28 Nov 2025
The Liquid AI Team introduces LFM2, a family of foundation models designed for efficient on-device deployment, demonstrating up to 2x faster inference on CPUs compared to similarly sized models while achieving strong performance across language, vision-language, speech, and retrieval tasks. These models leverage a hardware-in-the-loop architectural search to optimize for latency, memory, and quality under strict edge constraints.

04 Dec 2025
The rapid advancement of Large Language Models (LLMs) is catalyzing a shift towards autonomous AI Agents capable of executing complex, multi-step tasks. However, these agents remain brittle when faced with real-world exceptions, making Human-in-the-Loop (HITL) supervision essential for mission-critical applications. In this paper, we present AgentBay, a novel sandbox service designed from the ground up for hybrid interaction. AgentBay provides secure, isolated execution environments spanning Windows, Linux, Android, Web Browsers, and Code interpreters. Its core contribution is a unified session accessible via a hybrid control interface: An AI agent can interact programmatically via mainstream interfaces (MCP, Open Source SDK), while a human operator can, at any moment, seamlessly take over full manual control. This seamless intervention is enabled by Adaptive Streaming Protocol (ASP). Unlike traditional VNC/RDP, ASP is specifically engineered for this hybrid use case, delivering an ultra-low-latency, smoother user experience that remains resilient even in weak network environments. It achieves this by dynamically blending command-based and video-based streaming, adapting its encoding strategy based on network conditions and the current controller (AI or human). Our evaluation demonstrates strong results in security, performance, and task completion rates. In a benchmark of complex tasks, the AgentBay (Agent + Human) model achieved more than 48% success rate improvement. Furthermore, our ASP protocol reduces bandwidth consumption by up to 50% compared to standard RDP, and in end-to-end latency with around 5% reduction, especially under poor network conditions. We posit that AgentBay provides a foundational primitive for building the next generation of reliable, human-supervised autonomous systems.
There are no more papers matching your filters at the moment.
