
09 Dec 2025

Astra, a collaborative effort from Tsinghua University and Kuaishou Technology, introduces an interactive general world model using an autoregressive denoising framework to generate real-world futures with precise action interactions. The model achieves superior performance in instruction following and visual fidelity across diverse simulation scenarios while efficiently extending a pre-trained video diffusion backbone.

08 Dec 2025

Researchers from Fudan University and Shanghai Innovation Institute introduced RoPE++, an extension of Rotary Position Embeddings that re-incorporates the previously discarded imaginary component of attention scores to improve long-context modeling in Large Language Models. This method consistently outperforms standard RoPE on various benchmarks and offers significant KV-cache and parameter efficiency.

08 Dec 2025
The paper introduces Group Representational Position Encoding (GRAPE), a unified group-theoretic framework that re-conceptualizes and unifies existing positional encoding mechanisms like RoPE and ALiBi. It provides a principled design space for new encodings, demonstrating improved training stability and superior zero-shot performance in large language models.

10 Dec 2025


Researchers at the Hong Kong University of Science and Technology developed BiCo, a one-shot method that precisely binds visual concepts from images and videos to text prompts, enabling flexible cross-modal composition. The approach achieved superior content generation quality, demonstrating a 54.67% improvement in overall quality over previous state-of-the-art methods in human evaluations.

08 Dec 2025

Researchers from the University of Technology Sydney and Zhejiang University developed VideoCoF, a unified video editing framework that introduces a "Chain of Frames" approach for explicit visual reasoning. This method achieves mask-free, fine-grained edits, demonstrating a 15.14% improvement in instruction following and an 18.6% higher success ratio on their VideoCoF-Bench, while also providing robust length extrapolation.
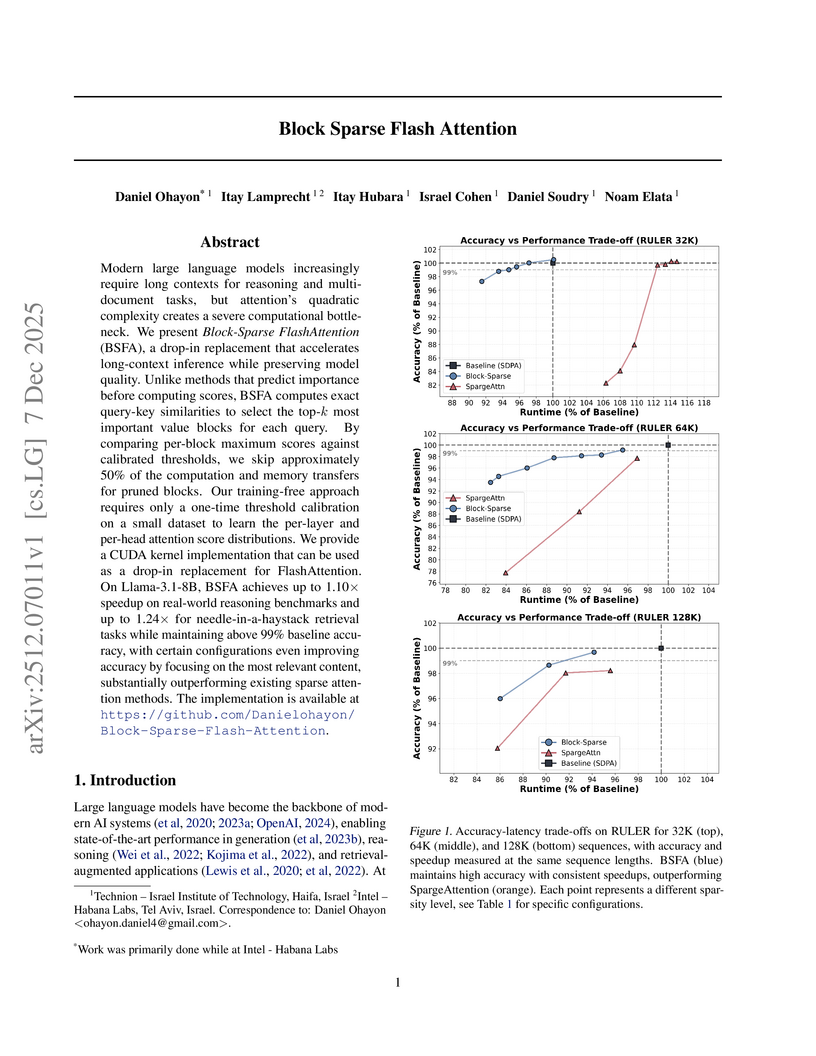
07 Dec 2025
Block Sparse Flash Attention (BSFA) accelerates large language model inference for long input sequences by intelligently skipping computations for negligible value blocks based on exact attention scores. This training-free method maintains high accuracy while achieving speedups up to 1.24x on retrieval tasks and 1.10x for general reasoning.

10 Dec 2025
ChronusOmni introduces a framework enhancing temporal awareness in omni large language models for both explicit and implicit audiovisual temporal grounding. It employs a novel temporal interleaved tokenization, a two-stage training strategy, and the new ChronusAV dataset, achieving state-of-the-art performance across six distinct audiovisual temporal grounding subtasks.

09 Dec 2025
Lightweight reinforcement learning policies were trained to automate the unmasking process for Diffusion Large Language Models (dLLMs), improving inference efficiency without sacrificing generation quality. These policies consistently outperformed heuristic methods, particularly in full-diffusion generation settings, and demonstrated transferability across different dLLM architectures and sequence lengths.

08 Dec 2025


Researchers from Meta AI and the University of Copenhagen developed OneStory, a framework for coherent multi-shot video generation that utilizes adaptive memory modules to model long-range cross-shot context. The method consistently outperforms existing baselines, achieving higher inter-shot coherence scores (e.g., 0.5813 average inter-shot coherence in text-to-multi-shot video tasks) and enhanced shot-level quality.

09 Dec 2025
Researchers from the University of Glasgow developed the Masked Generative Policy (MGP), a framework that employs masked generative transformers for robotic control. This approach integrates parallel action generation with adaptive token refinement, achieving an average 9% higher success rate across 150 tasks while reducing inference time by up to 35x, particularly excelling in long-horizon and non-Markovian environments.

08 Dec 2025
This document introduces foundational concepts and algorithms in Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL) for embodied agents, providing a self-contained pedagogical resource from ISCTE – University Institute of Lisbon. It offers clear, in-depth explanations of core methods, including necessary mathematical prerequisites, to build a strong understanding for learners.

08 Dec 2025

Researchers from Alibaba Group and Wuhan University developed MUSE, a multimodal search-based framework for lifelong user interest modeling that integrates rich semantic information across both retrieval and fine-grained modeling stages. Deployed in Taobao's display advertising system, MUSE achieved a +12.6% CTR, +5.1% RPM, and +11.4% ROI in online A/B tests.

08 Dec 2025
MAC introduces a model-based offline reinforcement learning approach that uses action chunks and flow-based generative policies to tackle complex, long-horizon tasks. It achieves state-of-the-art performance on challenging manipulation benchmarks, outperforming prior model-based methods and many model-free algorithms.

07 Dec 2025
Researchers at Southern Methodist University systematically compared various memory encoding and injection methods for transformer-based world models, finding that State-Space Models (SSMs) combined with attention-based injection offer a scalable approach for enhancing long-term recall. This hybrid strategy significantly improved consistency over extended imagination horizons compared to a vanilla Vision Transformer, effectively mitigating perceptual drift.

10 Dec 2025

Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.

08 Dec 2025
A two-stage self-supervised framework integrates the Joint-Embedding Predictive Architecture (JEPA) with Density Adaptive Attention Mechanisms (DAAM) to learn robust speech representations. This approach generates efficient, reversible discrete speech tokens at an ultra-low rate of 47.5 tokens/sec, designed for seamless integration with large language models.

09 Dec 2025


Mimic2DM is a framework that learns to control physically simulated 3D characters from abundant 2D video data, bypassing explicit 3D reconstruction by formulating motion imitation as a physics-based 2D motion tracking problem. The system enables characters to perform complex human-object interactions and animal locomotion, outperforming two-stage methods and exhibiting implicit 3D understanding from diverse 2D viewpoints.
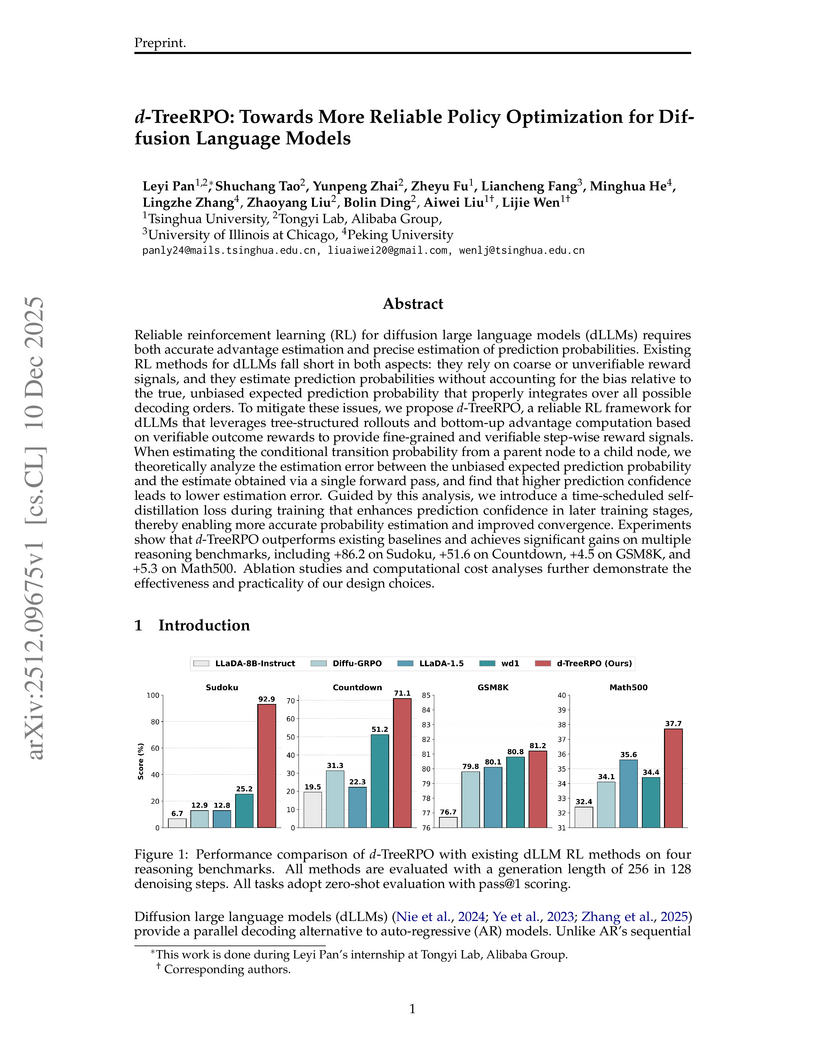
10 Dec 2025

Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.

10 Dec 2025
Turbulent flows posses broadband, power-law spectra in which multiscale interactions couple high-wavenumber fluctuations to large-scale dynamics. Although diffusion-based generative models offer a principled probabilistic forecasting framework, we show that standard DDPMs induce a fundamental \emph{spectral collapse}: a Fourier-space analysis of the forward SDE reveals a closed-form, mode-wise signal-to-noise ratio (SNR) that decays monotonically in wavenumber, for spectra , rendering high-wavenumber modes indistinguishable from noise and producing an intrinsic spectral bias. We reinterpret the noise schedule as a spectral regularizer and introduce power-law schedules that preserve fine-scale structure deeper into diffusion time, along with \emph{Lazy Diffusion}, a one-step distillation method that leverages the learned score geometry to bypass long reverse-time trajectories and prevent high- degradation. Applied to high-Reynolds-number 2D Kolmogorov turbulence and Gulf of Mexico ocean reanalysis, these methods resolve spectral collapse, stabilize long-horizon autoregression, and restore physically realistic inertial-range scaling. Together, they show that naïve Gaussian scheduling is structurally incompatible with power-law physics and that physics-aware diffusion processes can yield accurate, efficient, and fully probabilistic surrogates for multiscale dynamical systems.

05 Dec 2025
Kuaishou Technology researchers developed Entropy Ratio Clipping (ERC), a mechanism that imposes bidirectional constraints on the global policy's entropy ratio, to mitigate training instability in off-policy reinforcement learning for large language models. ERC consistently improved model performance on mathematical reasoning benchmarks and stabilized policy entropy and gradient norms by addressing global distributional shifts missed by conventional clipping methods.
There are no more papers matching your filters at the moment.
